Solr学习笔记之添加文档
通过本文,你将学到:
- 发送XML或JSON格式的文档到Solr
- 使用SolrJ客户端添加documents
发送XML或JSON格式的文档到Solr
准备工作
在添加文档到Solr之前,我们必须修改Solr的schema.xml文件,添加一些我们自己的字段。该文件位于:solr core 目录下的conf目录。在本文中,可能是:collection1\conf\ 目录下。然后添加如下内容到该文件
添加XML格式的documents到Solr
在本节中,我们将使用发送文档到Solr的索引中,并展示下我们在 http://blog.csdn.net/yanan_seachange/article/details/43303311 一文中,所提到的复制字段的神奇之处。
首先,我们定义如下格式的XML:
1
日志型 II
116300
该腕表于2009年面世,在其增大的表壳内,蕴含了劳力士最新的技术
2
黑水鬼
116610ln
它是潜水腕表中的出众典范。自1953年诞生以来,不仅依靠完美表现征服深海世界,魅力更遍及陆地。置身海洋,该腕表是专业潜水员的最佳陪伴;探索陆地,它亦是精湛与勇往直前的完美体现,因此备受深具远见卓识的腕表爱好者的青睐。
然后,启动Solr,为了简便起见,我们将上述文档放到了example\exampledocs这个目录下,之后在命令行中输入:
java -jar post.jar watches.xml随后我们可以看到类似下面的输出:

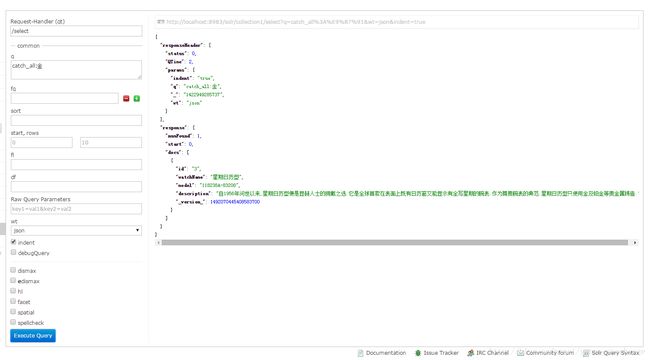
在浏览器中输入:http://localhost:8983/solr 选择collection1之后,点击查询,可以看到类似下图的页面:

下面展示下catch_all 字段:

请注意,post.jar。它是我们学习Solr的一个好工具,在命令,你可以输入 java -jar post.jar -h 来看更多的帮助信息,其中就包括如何添加json格式的文档到Solr索引。
添加json格式的document到Solr索引
我们在\example\exampledocs目录下定义了如下的json文件:
[
{
"id": "1",
"watchName": "星期日历型",
"model": "118238A-83208",
"description": "自1956年问世以来,星期日历型便是显赫人士的拥戴之选。它是全球首款在表面上既有日历窗又能显示有全写星期的腕表。作为尊贵腕表的典范,星期日历型只使用金及铂金等贵金属铸造。"
}
]请注意,你可能需要对json文件中,汉字进行unicode处理。
并使用post.jar的相关命令添加该文件到Solr索引,整个过程如下:

下面的输出,验证了上面的添加方式:
使用SolrJ客户端添加documents
SolrJ是一个以Java为基础的客户端库,它提供了从一个Java应用中,Solr项目与你的Solr服务器交互.在本节中,
我们将会实现一个简单的SolrJ客户端程序来发送文档使用Java。
SolrJ的maven配置:
org.apache.solr
solr-solrj
4.7.1
org.slf4j
slf4j-api
1.7.5
commons-logging
commons-logging
1.1.1
package com.lemon.solrj.test;
import java.io.IOException;
import java.io.PrintStream;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrServer;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.impl.HttpSolrServer;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrInputDocument;
public class ExampleSolrJClient {
private static final String serverUrl= "http://localhost:8983/solr/collection1";
private static SolrServer solr;
static{
solr= new HttpSolrServer(serverUrl);
}
public static void main(String[] args) throws Exception {
// addDocument();
for (SolrDocument next : simpleSolrQuery(solr, "catch_all:鬼", 10)) {
prettyPrint(System.out, next);
}
}
static void addDocument(){
try {
SolrInputDocument datejustII = new SolrInputDocument();
datejustII.setField("id", "1");
datejustII.setField("watchName", "日志型 II");
datejustII.setField("model", "116300");
datejustII.setField("description", "该腕表于2009年面世,在其增大的表壳内,蕴含了劳力士最新的技术");
solr.add(datejustII);
SolrInputDocument blackSubmariner = new SolrInputDocument();
blackSubmariner.setField("id", "2");
blackSubmariner.setField("watchName", "黑水鬼");
blackSubmariner.setField("model", "116610ln");
blackSubmariner.setField("description", "它是潜水腕表中的出众典范。"
+ "自1953年诞生以来,不仅依靠完美表现征服深海世界,魅力更遍及陆地。置身海洋,该腕表是专业潜水员的最佳陪伴;"+
"探索陆地,它亦是精湛与勇往直前的完美体现,因此备受深具远见卓识的腕表爱好者的青睐。");
solr.add(blackSubmariner);
solr.commit(true, true);
} catch (SolrServerException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
static SolrDocumentList simpleSolrQuery(SolrServer solr,
String query, int rows) throws SolrServerException {
SolrQuery solrQuery = new SolrQuery(query);
solrQuery.setRows(rows);
QueryResponse resp = solr.query(solrQuery);
SolrDocumentList hits = resp.getResults();
return hits;
}
static void prettyPrint(PrintStream out, SolrDocument doc) {
List sortedFieldNames =
new ArrayList(doc.getFieldNames());
Collections.sort(sortedFieldNames);
out.println();
for (String field : sortedFieldNames) {
out.println(String.format("\t%s: %s",
field, doc.getFieldValue(field)));
}
out.println();
}
}
关于上述代码的输出,这里就不再赘述了。