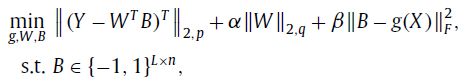前段时间的工作总结
最近做了好多工作,读了好多paper,跑了好多实验,脑子有点乱,东西有点多,思路有点忘,还是做个总结吧!!!
回顾一下之前的工作,我现在的研究的内容重点在于基于深度学习和哈希学习相结合的大规模图像检索,也就是深度哈希学习,说到这儿就不得不提一下哈希学习,哈希学习不是最近提出来的,历史比较久远了。。。。当然大规模图像检索仅仅是哈希学习的一个应用领域,哈希学习本身就是解决大数据检索问题的,只不过最近最近几年深度学习比较火热后,从2015年开始深度学习与哈希学习相互结合来解决大规模图像检索问题,我有时候在想为什么深度哈希在图像检索领域应用那么广泛呢,原因可能是在于基于深度学习的计算机视觉领域这几年很热吧!!而且发现单纯的哈希学习相关工作是针对大规模数据上的而并不是图像数据。
关于深度哈希相关研究领域其实比较广泛的,我涉猎的其实就是那么一丢丢的一丢丢的一丢丢而已。。。。哈希学习主要可以分为数据独立依赖和数据非依赖哈希,而数据依赖哈希又可以分为监督哈希,半监督哈希和无监督哈希,在图像检索(其实不仅仅在图像领域,以图像检索为例)监督哈希根据训练数据可用分为point-wise(每个group为单一图像)、pairs-wise(每个group为图像对)以及Triples-wise(每个group包含三个图像,查询图像,与查询图像相似的图像以及与查询图像不相似的图像),基于上述三种同类型的监督哈希学习可以设计出不同的损失函数。而我现在的工作主要集中在深度哈希学习中数据依赖哈希中的监督学习哈希的大规模图像检索(与之对应的还有,文本检索,视频检索,跨模态检索以及多模态检索等等等等),所以嘛,我真的涉猎了就是那么一丢丢的一丢丢的一丢丢。好了,说了太多废话了,进入正题,对于这几周的几个工作做个总结吧!!!!
- Bayesian Denoising Hashing for Robust Image Retrieval. Pattern Recognition 09/2018
之前的哈希学习中并没有考虑到图像中未知噪音对于检索性能的影响,为增加鲁棒性,本文采用了一种基于贝叶斯去噪的哈希方法,输出可以视为去噪版的哈希code。本质来说通过保留原始输入信息来重建更加健壮的哈希编码,同时增加约束条件来纠正低质量的哈希编码。通过差分的贝叶斯框架(variational Bayes framework) 来优化模型,在该框架中每次迭代都有封闭解,这样比之前的数值优化更有效。该方法可以只能增加到任何哈希方法中并不改变之前的训练过程,同时增加鲁棒性,本文中实验是基于FastH来进行鲁棒性实验的。
本文方法主要分为三个步骤:(1)通过 pretrained CNN(本文采用ResNet) 来进行特征提取;(2)训练FastH模型,然后使用Bayesian denoising hashing method进行错误订正。有被未知分布干扰的binary code以及干净的类标签,我们的目标是来重构去噪版binary code。具体框架图如下图所示。
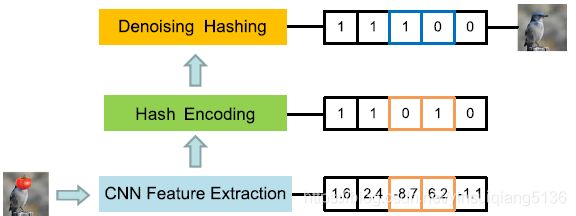
- Deep binary codes for large scale image retrieval[J]. Neurocomputing, 2017.
本文中采用通过比较所有特征图的平均响应和每个特征图的相应来生成binary code;此外,通过采用空间交叉求和策略( spatial cross-summing strategy)来生成可伸缩的binary code.我们提出一种动态-即时融合方法,该方法可以在线自动选择Top-N的高质量搜索进行在线融合从而提高检索精度。该两个策略基于通用模型的,不需要额外训练并且动态后期融合方案是查询自适应的。基于相似的视觉对象在特征图相应上分布相似。对网络结构进行的优化操作,并没有优化哈希函数。
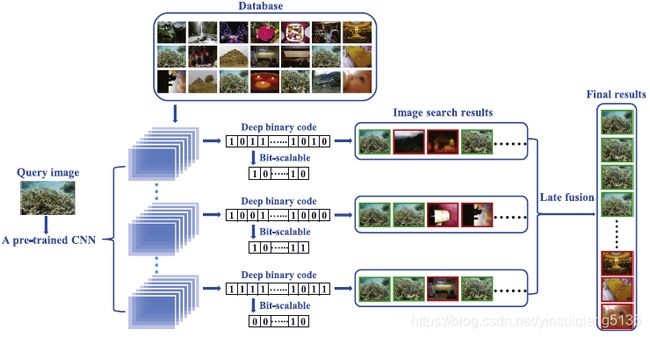
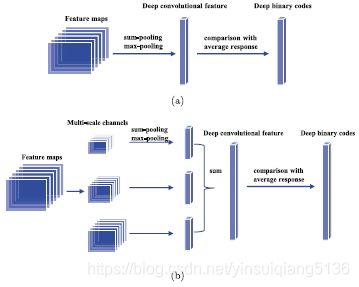
- Deep convolutional hashing using pairwise multi-label supervision for large-scale visual search[J]. Signal Processing Image Communication, 2017, 59.
之前的工作主要倾向于学习基于单标签图像的分层哈希模型,这样就会限制图像语义层次的表示。本文中,利用多标签图像以及标签之间的关系提出了一种新的卷积哈希模型,该模型利用pairwise的监督信息将图像分层的转换为hash编码。在深度哈希框架内CNN会自动学习具有较小语义间隔的视觉特征;然后哈希层利用非线性映射才获得hash编码。本文中提出了一种基于正则化的损失函数,此外pairwise的类标签监督信息利用标签相关性来计算语义相似性的图像。Deep Convolutional Hashing approach with Pairwise Multi-label Supervision, DCH-PMS 具体架构如图1所示。
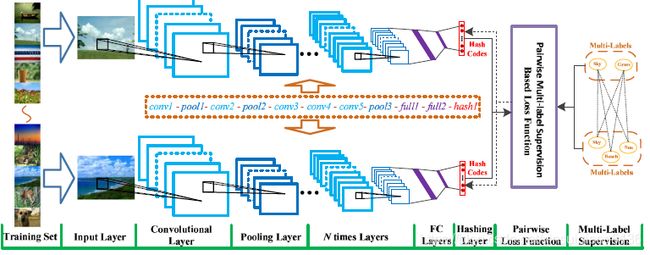
另外本文提供了一种很好的图像对直接度标签语义相似度度量值。可以借鉴一下在后期的研究中。
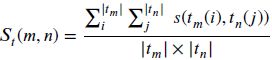
损失函数的设计基于哈希距离和上述定义的语义距离最小。即:
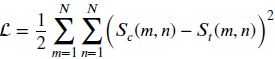
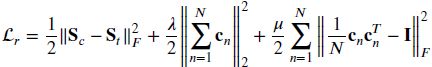
- Jiang Q Y, Cui X, Li W J. Deep Discrete Supervised Hashing[J]. IEEE Transactions on Image Processing, 2018, 27(12): 5996-6009.
本文主要思想是在同一个框架下使用监督信息直接指导离散哈希生成和特征提取——deep discrete supervised hashing (DDSH),DDSH是第一个利用监督信息来直接离散哈希编码生成和特征提取,可以增强上述两个过程的反馈调节。因此核心思想就是把离散哈希和特征提取放在同一个框架下,基于此也设计了损失函数。基于pairwise loss的损失函数设计。
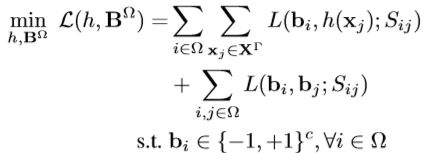
- Li T, Gao S, Xu Y. Deep Multi-Similarity Hashing for Multi-label Image Retrieval[C]//Proceedings of the 2017 ACM on Conference on Information and Knowledge Management. ACM, 2017: 2159-2162.
本文主要解决多标签检索的问题——Deep Multi-Similarity Hashing的框架(DMSH),采用了一种zero-loss interval(共享标签的数目)的pairwise的损失函数,损失函数包括哈希量化损失和多标签图像的pairwise损失,更加注重高层语义相似度而不是低层的语义相似度。此外,DMSH很容易扩展到各种网络深度网络。损失函数如下所示,其中t(c)即为zero-loss interval。
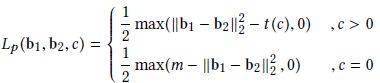
- Zareapoor M , Yang J , Jain D K , et al. Deep semantic preserving hashing for large scale image retrieval[J]. Multimedia Tools and Applications, 2018.
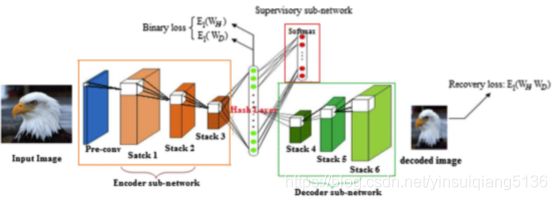
本文是我关注到的第一篇引入自编码器进行哈希生成的paper,主要思想是将堆积的卷积自编码器与哈希学习相互结合,DCAH包含编码器-解码器和监督子网络,生成了低维的binary code。同时,为了优化哈希算法,目标函数中添加了一种额外的松弛约束条件。
损失函数:
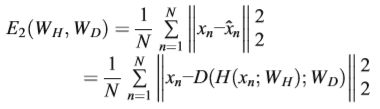
- Song K, Li F, Long F, et al. Discriminative Deep Feature Learning for Semantic-Based Image Retrieval[J]. IEEE Access, 2018, 6: 44268-44280.
本文主要解决的是基于语义的图像检索中类内和类间之间的空间特征分布,通过提出两种不同损失函数来解决上述问题。第一种损失函数是在softmax的基础上结合了中心损失(center loss),同时保证不同内容的图像特征是分离的,相同的类内图像是相似的;第二种损失函数基于改进的中心损失(improved center loss),不仅惩罚获得深度特征和类别特征中心的距离。而且拉大深度特征和其类别特征中心的距离。
损失函数一: 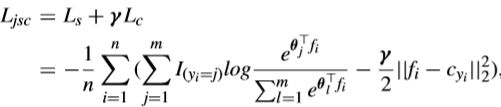
损失函数二: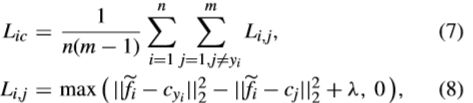
- Yang H F, Lin K, Chen C S. Supervised learning of semantics-preserving hash via deep convolutional neural networks[J]. IEEE transactions on pattern analysis and machine intelligence, 2018, 40(2): 437-451.
本文中假设图像的语义特征由几个潜在的属性控制,每个属性on 或者off,分类依赖这些属性,基于上述假设,本文提出一种基于监督学习的语义保持的深度哈希方法SSDH,在深度网络中嵌入隐藏层,同时通过最小化分类错误和离散哈希编码来设计了损失函数。SSDH将图像表示,哈希编码和分类放在同一个框架下考虑,并采用point-wise的方式进行训练。网络架构如下图所示。
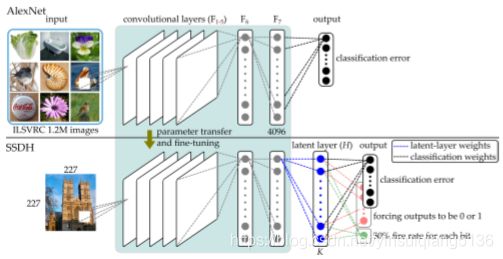
损失函数设计如下:
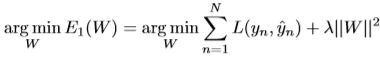
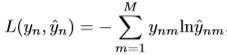
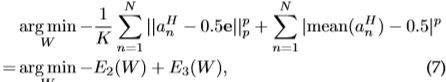
![]()
- Luo Y, Yang Y, Shen F, et al. Robust discrete code modeling for supervised hashing [J]. Pattern Recognition, 2018, 75: 128-135.
现有的方法存在如下问题:(1)由于二进制码连续松弛引起的严重量化误差;(2)后续哈希学习中不可靠的哈希编码干扰;(3)来自不精确和不完整语义标签的错误指导。为解决上述问题,提出鲁棒性离散哈希模型(RDCM),通过抑制不信任binary code和噪音标签的干扰从而直接产生高质量的哈希编码和哈希函数。在本文中,增加鲁棒性的方法主要采用L2,P正则化,该方法可以导致样本稀疏性,同时进行编码选择和噪音样本识别。更重要的是,在RDCM中增加了离散型限制来消除量化误差。网络架构设计如下所示。
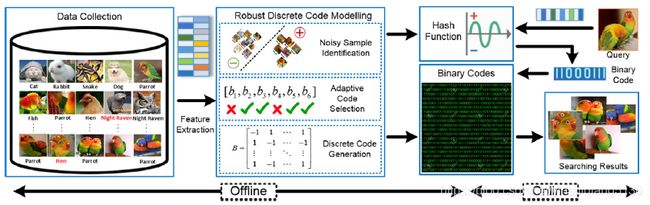
损失函数设计如下: