Oracle 基础总结:关键字总结
Oracle 基础总结:关键字总结
- 一、SQL基础查询语句
- 1、SELECT
- 二、过滤和排序数据
- 2、DISTINCT
- 3、WHERE
- 4、BETWEEN…AND…
- 5、IN
- 6、like:使用like运算选择类似的值,选择条件可以包含字符或数字。
- 7、ESCAPE:转义符,回避特殊符号时使用。
- 8、NULL :使用 IS (NOT) NULL 判断空值
- 9、AND:逻辑并,要求并的关系为真。
- 10、OR:逻辑或,要求或的关系为真。
- 11、NOT:逻辑否,要求否的关系为真。
- 12、order by 子句:使用 ORDER BY 子句排序,在select 语句的结尾。
- 三、单行函数
- 13、字符串控制函数
- 1)大小写控制函数:这类函数可改变字符的大小写
- 2)字符控制函数
- 2).1 CONCAT(A,B,C):连接函数,只能联结合并两个字符串
- 2).2 SUBSTR('字符串',截取起始位置,截取长度):字符截取函数,截取起始位置:从1开始
- 2).3 LENGTH('字符串'):返回字符串的长度
- 2).4 INSTR('字符串', '指定字符') :返回指定字符在字符串中的位置,从1算起
- 2).5 LPAD('目标',总需位数,'补齐代替符号') : 左补齐位数;
- 2).6 RPAD('目标',总需位数,'补齐代替符号') : 右补齐位数;
- 2).7 TRIM('指定字符' FROM '字符串')
- 14、数字函数
- 14.1 ROUND(数值,位数):四舍五入
- 14.2 TRUNC(数值,位数):截断,直接进行截断,不进行四舍五入。
- 14.3 MOD(数值,被除数):求余,显示余数值
- 14.4、TO_CHAR函数对数字的转换
- 14.5 TO_NUMBER 函数对字符的转换
- 15、通用函数
- 15.1 NVL函数:将空值转换成一个已知的值。可以使用的数据类型有日期、字符、数字。
- 15.2 NVL2 函数
- 15.3 NULLIF 函数
- 15.4 COALESCE 函数
- 16、CASE 表达式
开发工具与关键技术:oracle,plsql
作者:王雅思
撰写时间:2019-03-27
此篇总结涵盖了本人在Oracle 基础学习中的所接触到的部分常用关键字,及其常用语法。
一、SQL基础查询语句
1、SELECT
SELECT 语句用于从表中选取数据,后面一般跟着 from 关键字。
语法:
SELECT *|{[DISTINCT] column|expression [alias],...} FROM table;
SELECT *|列名 FROM 表名;
二、过滤和排序数据
2、DISTINCT
去除查询结果中的重复数据,留下不重复的。
语法:
SELECT DISTINCT(列名) FROM 表名;
3、WHERE
使用WHERE 子句,将不满足条件的行过滤掉。
语法:
SELECT *|{[DISTINCT] column|expression [alias],...} FROM table [WHERE condition(s)];
SELECT *|列名 FROM 表名 where 条件;
注:WHERE 子句紧随 FROM 子句。
4、BETWEEN…AND…
使用 BETWEEN 运算来显示在一个区间内[值1,值2]的值。
语法:SELECT 列名 FROM 表名 WHERE 列名 BETWEEN 值1 and 值2;
5、IN
使用 IN运算显示出查询的列名的值等于列表中的值之一的数据。
语法:SELECT 列名 FROM 表名 WHERE 列名 IN (值1,值2, 值3…);
6、like:使用like运算选择类似的值,选择条件可以包含字符或数字。
%:代表零个或多个字符(任意个字符)。
_ :代表一个字符。
语法:
SELECT 列名 FROM 表名 WHERE 列名 LIKE '%value';
SELECT 列名 FROM 表名 WHERE 列名 LIKE '_value';
SELECT 列名 FROM 表名 WHERE 列名 LIKE '_value%';
SELECT 列名 FROM 表名 WHERE 列名 LIKE '%value_';
注:% 和 _ 可重复使用和同时使用,like 后的字符大小写敏感。
7、ESCAPE:转义符,回避特殊符号时使用。
例如:将[%]转为[%]、[_]转为[_],然后再加上[ESCAPE ‘\’] 即可。
语法:
SELECT 列名 FROM 表名 WHERE 列名 LIKE 'IT\_%' escape '\';
个人理解:
Escape 后的字符被标识为一个特殊字符,假设是A,
转义字符A存在Escape前的字符串中,字符A的下一个字符将从特殊字符转为普通字符,
(被转特殊字符可以是Oracle本身定义的,如:,%…;如也可以是自己定义的,如自己定义的转义字符 A),回归到字符串中。
例:
select last_name from employees where last_name like '_aSataabaa%' escape 'a';
结果视图:
![]()
查询结果:Pataballa。
注:
a 是转义字符,但 a 的下一个字符是普通字符,
上面例句是转义字符将自己转回普通字符,但一般不会这么写,
一般选用的字符不同于字符串中的普通字符或筛选条件用到的特殊字符(如:_、%等),否则会混乱。
例句只是用于说明这种可能性,写法不要参照这个。
8、NULL :使用 IS (NOT) NULL 判断空值
语法:SELECT 列名 FROM 表名 WHERE 列名 IS NULL; 值为空。
SELECT 列名 FROM 表名 WHERE 列名 IS NOT NULL;值不为空。
9、AND:逻辑并,要求并的关系为真。
语法:SELECT 列名 FROM 表名 WHERE 条件1 AND 条件2;
注:and 常用于where 等子句中,使多个条件的关系为并。and 可重复使用。
10、OR:逻辑或,要求或的关系为真。
语法:SELECT 列名 FROM 表名 WHERE 条件1 OR 条件2;
注:or 常用于where等子句中,使多个条件的关系为或。or 可重复使用。
11、NOT:逻辑否,要求否的关系为真。
语法:SELECT 列名 FROM 表名 WHERE 列名 NOT IN (值1,值2, 值3…);
注:not 常用于where等子句中,使not前的值与not后的值的关系为否。
12、order by 子句:使用 ORDER BY 子句排序,在select 语句的结尾。
ASC(ascend): 升序
DESC(descend): 降序
语法:
SELECT 列名 FROM 表名 ORDER BY 列名 ASC; 升序
SELECT 列名 FROM 表名 ORDER BY 列名 DESC; 降序
SELECT 列名 AS 别名 FROM 表名 ORDER BY 别名 ; --按别名排序
SELECT 列名, 列名2 FROM 表名 ORDER BY 列名 DESC, 列名2 ASC; --可用列名进行排序
SELECT 列名 FROM 表名 ORDER BY 表名.其他列名 ; --可以使用不在SELECT 列表中的列排序
注:
1)oracle中如果使用了ORDER BY,在不指明是升序还是降序的情况下,则默认升序,
所以需要升序排序时,ASC可以不写,如果需要倒序,则DESC必须写。
2)当列名的值为字母时,字母名称排序 默认 A-Z;
3)当列名的值为数字时,数字默认升序,从小到大 ,默认0-9;
4)当列名的值为字母与数字的组合时,则从第一个字符开始,顺着下去,是什么字符就用那种排序方式。
5)当列名的值为汉字时,请参考链接: Oracle 的 order by的中文排序问题.。作者:風云。
6)在多个列名参与order by组合排序时,按列名顺序进行排序,这种排序结果在一定顺序范围整齐,整体排序不怎么齐。
7)可以使用不在SELECT 列表中的列排序,但需要排序的所用的值在查询的表中存在。
8)按别名排序,根据别名所代表的列里面的值排序。
三、单行函数
13、字符串控制函数
1)大小写控制函数:这类函数可改变字符的大小写
| 函数 | 结果 | 作用 |
|---|---|---|
| LOWER(‘SQL Course’) | sql course | 单词全部字母小写 |
| UPPER(‘SQL Course’) | SQL COURSE | 单词全部字母小写 |
| INITCAP(‘SQL Course’) | Sql Course | 单词首字母大写,其余字母全部小写 |
语法:
SELECT 列名, lower(列名),UPPER(列名),INITCAP(列名),FROM 表名;
例句:
SELECT last_name,lower(last_name),UPPER(last_name),INITCAP('hu lu wa'),INITCAP('DSkofoiDjioj')
FROM employees
WHERE LOWER(last_name) = LOWER('hiGGins')
结果视图:注意观察大小写变化。
![]()
Where 子句后的大小写控制函数:
让查询的对象全部转换成对应大小写 也将查询条件转换,这样即便不清楚字母大小写,也能查出满意的结果。
2)字符控制函数
语法语句 例句:
-- 函数 结果
SELECT CONCAT('Hello', 'World') a -- HelloWorld
, SUBSTR('HelloWorld',-1,1) b -- Hello
, LENGTH('HelloWorld') c -- 10
, INSTR('HelloWorld', 'W') d -- 6
, LPAD('24000',5,'*') e -- *****24000
, RPAD('24000', 10,'*') f -- 24000*****
, TRIM('H' FROM 'HelloWorld') g -- elloWorld
, REPLACE('abcd','b','m') h -- amcd
FROM 表名;
结果视图:

释义理解:
2).1 CONCAT(A,B,C):连接函数,只能联结合并两个字符串
2).2 SUBSTR(‘字符串’,截取起始位置,截取长度):字符截取函数,截取起始位置:从1开始
如果截取起始位置>0,为正,则截取起始位置为从左往右算起第N位;
如果截取起始位置<0,为负,则截取起始位置为从右往左算起第N位;
然后就从截取起始位置开始,从左到右,截取对应截取长度的字符串。
截取起始位置为0或1,截取起始位置是一致的,都是第1位;
为2,才是第2位;为-2,则是从字符串的最有边往左数起的第2位。
如果目标截取的长度>最终可截取到的长度,则截取结果为最终可截取到的长度,多出的长度不会用空格补齐。
2).3 LENGTH(‘字符串’):返回字符串的长度
汉字字符与字母字符返回长度是相同的算法,一个汉字是一个字符。
2).4 INSTR(‘字符串’, ‘指定字符’) :返回指定字符在字符串中的位置,从1算起
2).5 LPAD(‘目标’,总需位数,‘补齐代替符号’) : 左补齐位数;
2).6 RPAD(‘目标’,总需位数,‘补齐代替符号’) : 右补齐位数;
先计算目标的位数,减去总需位数,得出结果;
结果为正,则在目标的左边/右边,用补齐代替符号将位数补齐;
结果为负,则从目标的左边算起,保留总需位数的字符,其余字符删除
2).7 TRIM(‘指定字符’ FROM ‘字符串’)
将指定字符,在字符串的最左边和最右边,检测匹配的字符,然后去除,只能在字符串的最左边和最右边的各一个字符;无指定字符,默认是 去最左边和最右边的空格。
2).8 REPLACE(‘字符串’,‘指定字符(串)’,‘替换的字符(串)’) :替换字符(串),在字符串中筛选出指定字符(串),将其替换为替换的字符(串);
14、数字函数
14.1 ROUND(数值,位数):四舍五入
语法例句:
SELECT ROUND(45.926,2), ROUND(45.926,0), ROUND(45.926,-1) FROM DUAL;
查询结果视图:
![]()
如果位数>0 ,就四舍五入,保留相应位数的小数;
如果位数=0 ,就根据第一位小数四舍五入,只保留整数部分;
如果位数<0 ,就从个位数起,根据第(位数的绝对值)位的值,四舍五入到整数部分。
例:
数值为145.38,位数=-2,则是从个位数起2位,即是十位,值为4,舍去,最终的值为100。
数值为45.926,位数=-2,则是从个位数起2位,即是十位,值为4,舍去,最终的值为0。
数值为45.926,位数=-1,则是从个位数起1位,即是个位,值为5,进1,最终的值为50。
查询语句:
SELECT ROUND(145.38,-2), ROUND(45.926,-2),ROUND(45.926,-1) FROM DUAL;
结果视图:
![]()
DUAL 是一张伪表,可以用来测试函数和表达式。
14.2 TRUNC(数值,位数):截断,直接进行截断,不进行四舍五入。
语法例句:
SELECT TRUNC(45.926,2), TRUNC(45.926,0),TRUNC(145.926,-2) FROM DUAL;
查询结果视图:
![]()
如果位数>0 ,就只保留相应位数的小数,其余的去掉;
如果位数=0 ,就只保留整数部分,其余的去掉;
如果位数<0 ,就截断(位数值的绝对值)位整数,从个位起,截断部分值修改为0,保留其他整数部分。
例:
数值为145.38,位数=-2,则是从个位数起的2位,即是个位和十位,值都变为0,最终的值为100。
数值为45.926,位数=-2,则是从个位数起的2位,即是个位和十位,值都变为0,最终的值为0。
数值为45.926,位数=-1,则是从个位数起的1位,即是个位,值变为0,最终的值为40。
查询语句:
SELECT TRUNC(145.38,-2), TRUNC(45.926,-2),TRUNC(45.926,-1)FROM DUAL;
查询结果视图:
![]()
14.3 MOD(数值,被除数):求余,显示余数值
将数值除以被除数,得到商和余数,如果数值能被被除数整除,即余数=0,显示值为0,
如果不能,即余数>0,显示值为余数;
语法例句:
select salary,mod(salary,3000) FROM employees;
查询结果视图:
![]()
14.4、TO_CHAR函数对数字的转换
TO_CHAR 函数中经常使用的几种格式:
9 数字
0 零
$ 美元符
L 本地货币符号
. 小数点
, 千位符\
查询语句例句
SELECT
TO_CHAR(6000,'L99,999.00') AS A, --L 本地货币符号
TO_CHAR(6000,'$99,999.00') AS B , --$ 美元符
TO_CHAR('9992429925555','$99,999.00') AS C, -- 位数不一致将会出现 ##
TO_CHAR('9992429925555','$999,999,999,999,999.00') AS D -- 位数一致
FROM dual;
查询结果视图:
![]()
注意:前后两个参数,后面的参数位数要大于或等于前面参数的位数。
14.5 TO_NUMBER 函数对字符的转换
查询语句例句:
select TO_NUMBER('¥1,234,567,890.00','L999,999,999,999.99') as A ,
TO_NUMBER('¥1234567890.00','L999999999999.99') as B ,
TO_NUMBER('$1,234,567,890.00','$999,999,999,999.99') as C ,
TO_NUMBER('1,234,567,890.00','999,999,999,999.99') as D
from dual;
查询结果视图:
![]()
注:
右边的参数数字一定要为9,不然会报错提示“无效的数字格式模型”。
左边货币符‘¥’对应右边的“L”
15、通用函数
15.1 NVL函数:将空值转换成一个已知的值。可以使用的数据类型有日期、字符、数字。
其函数的一般形式为:
NVL(commission_pct,0)
NVL(hire_date,‘01-1月-97’)
NVL(job_id,‘No Job Yet’)
语法释义:
NVL (expr1, expr2): expr1不为NULL,返回expr1;为NULL,返回expr2。
查询语句例句:
SELECT salary, commission_pct,
NVL(commission_pct,0) AS A,
NVL(hire_date,'01-1月-97') AS B,
NVL(job_id,'No Job Yet') AS C,
(salary * 12) + (salary * 12 * NVL(commission_pct, 0)) AN_SAL
FROM employees;
查询结果视图:
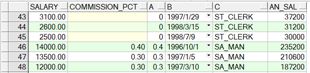
15.2 NVL2 函数
语法释义:
NVL2 (expr1, expr2, expr3) : expr1不为NULL,返回expr2;为NULL,返回expr3。
查询语句例句:
SELECT commission_pct a,NVL2(commission_pct,'SAL+COMM','SAL') b FROM employees;
查询结果视图:

15.3 NULLIF 函数
语法释义:
NULLIF (expr1, expr2) : 相等返回NULL,不等返回expr1 。
查询语句例句:
SELECT first_name, LENGTH(first_name) "expr1",
last_name, LENGTH(last_name) "expr2",
NULLIF(LENGTH(first_name), LENGTH(last_name)) result
FROM employees;
查询结果视图:
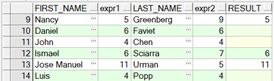
15.4 COALESCE 函数
语法释义:
COALESCE (expr1, expr2, …, exprn) : 如果第一个表达式为空,则返回下一个表达式,对其他的参数进行COALESCE;若不为空,则返回当前值 。
优点:
COALESCE 与 NVL 相比的优点在于 COALESCE 可以同时处理交替的多个值。
查询语句例句:
SELECT commission_pct, salary, nvl2(commission_pct, salary, 10) "nvl2",
COALESCE(commission_pct, salary, 10) "COALESCE"
FROM employees;
查询结果视图:
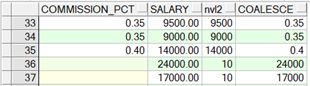
16、CASE 表达式
语法:
CASE expr
WHEN comparison_expr1 THEN return_expr1
[WHEN comparison_expr2 THEN return_expr2
WHEN comparison_exprn THEN return_exprn
ELSE else_expr]
END
查询语句例句:
SELECT job_id, salary,
CASE job_id WHEN 'AD_PRES' THEN 1.10*salary
WHEN 'AD_VP' THEN 1.15*salary
WHEN 'IT_PROG' THEN 1.20*salary
ELSE salary
END "REVISED_SALARY"
FROM employees;
查询结果视图:

如需想了解更多的关键字,请点击:SQL 常用关键字释义和用法.。CSDN 用户’天之丛云’的博客。
或在 plsql 中执行查询语句:
select * from v$reserved_words order by keyword asc;
查询方法来源于链接:https://www.cnblogs.com/yingsong/p/4485651.html.
博客园用户NewLife365的博客。
以上内容包含了老师的教学内容和个人理解,如内容有不正确的地方,还请指正。
感谢您的浏览。