Cortex-M系列:中断的内在机理
在博客[2]Cortex-M系列: 软件中断和硬件中断中,主要写的是要怎么配置中断并产生中断,而本篇主要将CPU是如何识别我们的代码并运行中断,同时不破坏程序的上下文的。文中用一个例子解释了惰性压栈的原理。在发生中断嵌套时,Cortex-M处理器将使用出栈抢占、末端连锁、延迟到达等机制来优化响应速度,同时降低了功耗[6]。理解这部分原理,一方面有利于处理在中断中出现的BUG,另一方面是有利于深入理解嵌入式操作系统(这部分算是基础)。
在阅读本文前,推荐先阅读[4]Cortex-M系列:非中断、特权模式下的汇编语言,因为:调用者(函数)+被调用者(函数)的关系和进程(或在无操作系统中的main函数)与中断的上下文关系是类似的。
本文是在Stm32H743单片机下进行测试的,对Cortex-M4和Cortex-M7适用,对CortexM3不一定适用。
目录
1 接收异常请求
2 异常进入
2.1 寄存器压栈(Stacking)
2.1.1 栈帧
2.1.2 MSP/PSP
2.1.3 双字对齐
2.1+ 一个例子
2.2 从中断向量表中取出异常向量( vector fetch)
2.3 更新NVIC寄存器和内核状态寄存器
3 异常中
3.1 同步/异步异常分类
3.2 按异常句柄类型分类
3.3 中断嵌套时stacking的优化机制
4 异常返回
5 参考文献
1 接收异常请求
在博客[2]中的硬件中断请求设置完成后,要能够接收异常请求还有以下条件(虽然大多是情况下是满足的):
1、处理器正在运行(未被暂停或处于复位状态)[7.7.1]
2、异常处于使能状态
3、异常的优先级高于当前优先级
4、异常未被屏蔽
2 异常进入
参考[7.7.2],[2.3.7]
当有一个具有足够优先级的挂起异常时发生异常项,并且满足一下其中一个条件:
•处理器处于线程模式。
•新异常的优先级高于正在处理的异常,在这种情况下,新异常会抢占原始异常。
当一个异常抢占另一个异常时,异常被嵌套。
注:2.1,2.2,2.3的工作是同步进行的,并不是顺序关系。
2.1 寄存器压栈(Stacking)
先解释下上下文(context),这里的上文指中断前程序所在的地方,下文指中断后的中断服务程序所在的地方,先不考虑中断嵌套的情况。另外文中不特别区分中断和异常两个概念的区别,而当做一个意思。
2.1.1 栈帧
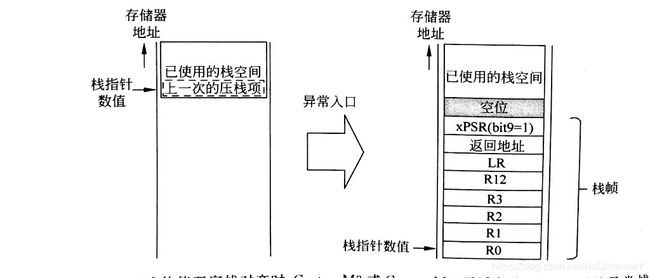
寄存器压栈分为短栈帧压栈和长栈帧压栈。
短栈帧由不保护浮点寄存器的调用者保护寄存器组成:R0~R3,R12,返回地址,LR,xPSR组成,共8个字。[8.1.3]
注:栈帧包括返回地址。这是中断程序中的下一条指令的地址。此值在异常返回时恢复到PC寄存器,以便中断的程序恢复运行.
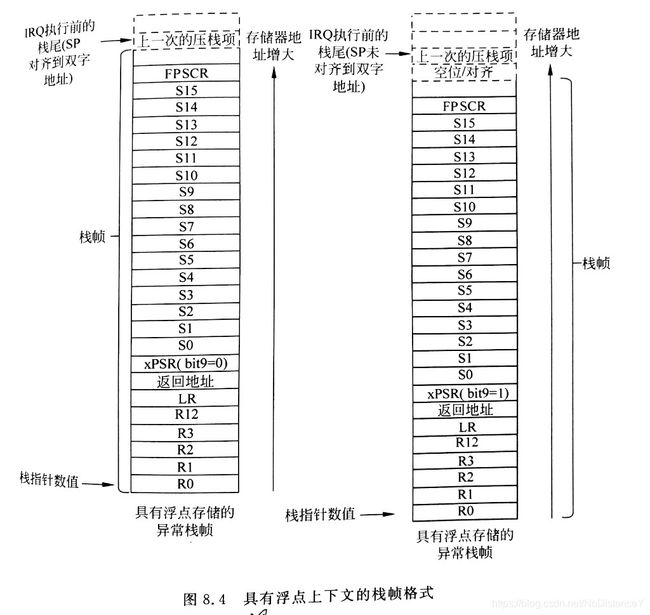
长栈帧由包含浮点寄存器的调用者保护寄存器组成:R0~R3,R12,返回地址,LR,xPSR,S0~S15,FPSCR组成,共26个字。
长短栈帧的选择由:CONTROL.FPCA位决定。该位为1时表示该进程或主函数使用了浮点运算,则需要保护浮点寄存器上文,因此选用长栈帧。反之使用短栈帧。
2.1.2 MSP/PSP
选择保存的栈的位置由:CONTROL.SPSEL位决定。该位为1时使用进程栈指针所指向的地址为栈入口,反之(默认)以主栈指针所指向的指针作为栈入口。
注:有操作系统时,当前任务选择使用进程栈指针(PSP),OS内核及异常处理使用MSP。没有操作系统时,默认始终使用MSP。
2.1.3 双字对齐
最后还需要考虑双字对齐:该特性在SCB.CCR.STKALLGN中设置,Cortex-M4和Cortex-M7是默认开启的。压栈前,程序会判断所需要的栈帧压栈后是否满足双字对齐,如果不满足,则将xPSR.bit9写为1,并在压栈后,附加一个栈顶空位来实现对齐。
另外,“惰性压栈”将在2.1+中讲解。
2.1+ 一个例子
现在我们实测下长栈帧的情况:无操作系统的最小系统程序进入主程序后就进入”while(1);“中,程序只开启一个定时器2中断,定时器2中除了清除定时器状态寄存器的状态标志,无其他操作。中断前寄存器为下图(FPU部分比较长,就没截图了):

中断后在memory找到如下长栈帧:

疑问:上文没使用浮点运算也是长栈帧,浮点单元中读取的值和Keil寄存器中观察的值不一致。
答:
a\先解释为什么是长栈帧,FPCA的值:
1、在SystemInit()前,FPCA==0,在进入main()函数后,FPCA自动变为1,即使程序还没有进行浮点运算,整个没有进入操作系统调度的上下文一直处于FPCA==1的状态。
2、而在有通过操作系统中建立的每个任务,只要还没有执行浮点运算FPCA一直为0,而只要执行一次浮点运算后,那么无论之后有没有再使用浮点运算,这个任务中的FPCA恒等于1(因为,如果有异常发生时,FPCA状态信息会被存到EXC_RETURN中,在异常返回时,FPCA通过解析EXC_RETURN来写回)。.(本文不主讲操作系统下的线程调度,可详见后续博文)
3、FPCA在异常处理的开始被清零。每次异常处理都像是创建一个任务,在本次异常处理结束后,“任务”被删除。在这样的比喻下,异常的FPCA设置就和第2条现象一致了。
这是因为“惰性压栈”的机制引起的。这里符合[13.3]中第二种情况:“被打断的任务中有浮点上下文,ISR中没有”。
| CPACR |
协处理器访问控制寄存器 Coprocessor Access Control Register |
为协处理器指定访问权限 |
| FPCCR |
浮点上下文控制寄存器 Floating-point Context Control Register |
设置或返回FPU控制数据 LSPACT位为1时:惰性状态保存被激活。已分配浮点堆栈帧,但将状态保存到该帧的操作会被延迟。 |
| FPCAR |
浮点上下文地址寄存器 Floating-point Context Address Register |
保存分配在异常堆栈帧上的未填充浮点寄存器空间的位置。 |
b\那么由CONTRL.FPCA确定了需要保护上文的浮点寄存器,但浮点寄存的压栈操作会将中断响应时间从12个时钟周期延长到25个时钟周期,引起激活了FPCCR.LSPACT,该位被置位1。在异常中,只有当异常中也进行了浮点运算,LSPACT位才会复位为0,此时S0~S15和FPSCR会根据FPCAR的地址压与预留给浮点寄存器的栈中。若异常中没有浮点运算,则S0~S15将使用处于保留状态,和中断前的浮点寄存器组的值不一致。

2.2 从中断向量表中取出异常向量( vector fetch)
异常向量可以看做是存储异常服务程序(异常处理)地址的指针。中断向量表的偏移一般是提供给远程升级/在线升级程序使用的。在确定异常处理的起始地址后,指令就会被取出。[7.9.3]
2.3 更新NVIC寄存器和内核状态寄存器
1、PC有2.2中的中断向量所指向的地址确定。
2、LR会更名为EXC_RETURN的特殊值。该值有CONTRL寄存器表征系统状态的位来确定。

3、在异常处理内部,栈操作使用主栈指针(MSP),处理器运行在特权模式访问等级。
4、另外中断的挂起和激活属性见博客[2].
3 异常中
通过清除相关状态寄存器的事件位,从而清除片内外设的中断请求信号,详见博客[2]。
3.1 同步/异步异常分类
先解释下同步异常和异步异常[5],在cortex-M7中[2.3.2]:
| 异步异常 Asynchronous exception |
Reset NMI BusFault PendSV SysTick Interrupt(IRQ) |
除了Reset之外,处理器还可以在触发异常和处理器进入异常处理程序之间执行另一条指令。 |
| 同步异常 Synchronous exception |
MemManage BusFault UsageFault SVCall |
/ |
3.2 按异常句柄类型分类
| 中断服务路径 Interrupt Service Routines (ISRs) |
中断IRQ0到IRQ239是ISRs可以处理的最大异常范围。可用的实际异常数由实现定义。 |
| 错误句柄 |
HardFault、MemManage fault、UsageFault和BusFault是由错误处理程序处理的错误异常。 |
| 系统句柄 |
NMI、PendSV、SVCall SysTick和故障异常都是由系统处理程序处理的系统异常。 |
3.3 中断嵌套时stacking的优化机制
在异常中,可能出现中断嵌套,中断为了保证中断的快速响应,Cortex-M7、Cortex-M4也引入了如下机制,由于不方便观察,这里不细讲,只粘贴进来[2.3.7]。
| 出栈抢占 Preemption |
When the processor is executing an exception handler, an exception can preempt the exception handler if its priority is higher than the priority of the exception being handled. When one exception preempts another, the exceptions are called nested exceptions. |
| 末端连锁 Tail-chaining |
This mechanism speeds up exception servicing. On completion of an exception handler, if there is a pending exception that meets the requirements for exception entry, the stack pop is skipped and control transfers to the new exception handler . |
| 延迟到达 Late-arriving |
This mechanism speeds up preemption. If a higher priority exception occurs during state saving for a previous exception, the processor switches to handle the higher priority exception and initiates the vector fetch for that exception. Late arrival does not affect state saving because the state saved is the same for both exceptions. Therefore the state saving continues uninterrupted. The processor can accept a late arriving exception until the first instruction of the exception handler of the original exception enters the execute stage of the processor. On return from the exception handler of the late-arriving exception, the normal tail-chaining rules apply. |
4 异常返回
在异常处理的结尾,程序代码执行的返回会引起EXCETURN数值被加载到程序技术器中(PC),触发异常返回机制。[7.7.3]
过程可以看做是异常进入逆过程,这里就不进行赘述。出栈主要依据的寄存器有FPCCR、CONTRL、EXC_RETURN和被压入栈中的xPSR。
5 参考文献
文中涉及的链接:
[1] ARM Cortex-M3 与Cortex-M4 权威指南 ,文中[x.x.x](蓝色)为具体的参考章节
[2] Cortex-M系列: 软件中断和硬件中断 https://blog.csdn.net/NoDistanceY/article/details/104046160
[3] ARM® Cortex®-M7 Devices Generic User Guide , [x.x.x](红色)为具体的参考章节
[4] Cortex-M系列:非中断、特权模式下的汇编语言 https://blog.csdn.net/NoDistanceY/article/details/104003831
[5] 同步中断、异步中断区别 https://blog.csdn.net/jasonLee_lijiaqi/article/details/80181814
[6] 实现减轻Cortex-M设备上CPU功耗的方法和技巧 http://www.elecfans.com/d/758630.html
文中未涉及但有参考意义的链接:
[1] 一文分清Cortex-M系列处理器指令集 https://blog.csdn.net/chenhaifeng2016/article/details/70314238
[2] 微控制器Cortex-M7为高性能而生 针对高端控制系统嵌入式应用 http://www.elecfans.com/emb/danpianji/20180205630354.html
[3] IEEE754 http://www.softelectro.ru/ieee754_en.html
[4] ARM官网资料 http://infocenter.arm.com/help/advanced/help.jsp?
修改:
1、:对部分英文术语的中文翻译进行修改:“抢占”改为“出栈抢占”,“延迟”改为“延迟到达”