基于飞桨实现高光谱反演:通过遥感数据获取土壤某物质含量
点击左上方蓝字关注我们

【飞桨开发者说】马云飞,枣庄学院地理信息科学专业在读,计算机视觉技术爱好者,研究方向为神经网络在遥感领域的应用等。

高光谱反演是什么?
高光谱反演是使用遥感卫星拍摄的高光谱数据以及实地采样化验的某物质含量数据来建立一个反演模型。简单来说就是:有模型以后卫星一拍,就能得知土壤中某物质的含量,不用实地采样化验了。

高光谱遥感可应用在矿物精细识别(比如油气资源及灾害探测)、地质环境信息反演(比如植被重金属污染探测)、行星地质探测(比如中国行星探测工程 天问一号)等。

目前有许多模型可用于高光谱反演,如线性模型、自然对数模型、包络线去除模型、简化Hapke模型,人工神经网络模型等,本文选择线性模型进行研究。
准备数据集
本次使用的数据集是前段时间跟一位博士师哥学习时使用的数据,是师哥辛辛苦苦从各地采样带回实验室化验以及处理遥感图像得来的。我们常用的遥感卫星有高分一号、高分二号、Landsat7 、Landsat8等。以Lansat8为例,其OLI陆地成像仪包括9个波段,空间分辨率为30米,其中包括一个15米的全色波段,成像宽幅为185x185km。热红外传感器TIRS包括2个单独的热红外波段,分辨率100米。以下是各波段的常见用途。





本次使用的数据集格式如下:

切割数据的比例要考虑到两个因素:更多的训练数据会降低参数估计的方差,从而得到更可信的模型;而更多的测试数据会降低测试误差的方差,从而得到更可信的测试误差。我们这个例子中设置的分割比例为8:2。
以下代码可直接在百度AI Studio 上fork我的项目来运行:
https://aistudio.baidu.com/aistudio/projectdetail/693750/
dataset = pd.read_csv('data/data48548/data.csv')#读取数据集
# df转array
values = dataset.values
# 原始数据标准化,为了加速收敛
scaler = MinMaxScaler(feature_range=(0, 1))
scaled = scaler.fit_transform(values)
data = scaled
ratio = 0.8 # 训练集和验证集的划分比例
offset = int(data.shape[0]*ratio)
train_data = data[:offset]
test_data = data[offset:]
def reader_creator(train_data):
def reader():
for d in train_data:
yield d[:-1], d[-1:]
return reader
BUF_SIZE=50
BATCH_SIZE=20
#用于训练的数据提供器,每次从缓存中随机读取批次大小的数据
train_reader = paddle.batch(
paddle.reader.shuffle(reader_creator(train_data),
buf_size=BUF_SIZE),
batch_size=BATCH_SIZE)
#用于测试的数据提供器,每次从缓存中随机读取批次大小的数据
test_reader = paddle.batch(
paddle.reader.shuffle(reader_creator(test_data),
buf_size=BUF_SIZE),
batch_size=BATCH_SIZE)
配置训练程序
下面我们开始配置训练程序,目的是定义一个训练模型的网络结构。
对于线性回归来讲,它就是一个从输入到输出的简单的全连接层。训练程序必须返回 平均损失作为第一个返回值,因为它会被后面反向传播算法所用到。
优化器选择的是 SGD(随机梯度下降)optimizer,其中 learning_rate 是学习率,与网络的训练收敛速度有关系。代码如下:
#定义张量变量x,表示14维的特征值
x = fluid.layers.data(name='x', shape=[14], dtype='float32')
#定义张量y,表示1维的目标值
y = fluid.layers.data(name='y', shape=[1], dtype='float32')
#定义一个简单的线性网络,连接输入和输出的全连接层
#input:输入tensor;
#size:该层输出单元的数目
#act:激活函数
y_predict=fluid.layers.fc(input=x,size=1,act=None)
cost = fluid.layers.square_error_cost(input=y_predict, label=y) #求一个batch的损失值
avg_cost = fluid.layers.mean(cost)
optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.001)
opts = optimizer.minimize(avg_cost)
开始训练
请使用如下代码开始训练,其中EPOCH_NUM为模型的训练轮数,这个数量要适中,否则可能发生过拟合等问题
model_save_dir:模型的保存目录,保存下来,下次就可以继续训练或者直接推理了。
for pass_id in range(EPOCH_NUM): #训练EPOCH_NUM轮
# 开始训练并输出最后一个batch的损失值
train_cost = 0
for batch_id, data in enumerate(train_reader()): #遍历train_reader迭代器
train_cost = exe.run(program=fluid.default_main_program(),#运行主程序
feed=feeder.feed(data), #喂入一个batch的训练数据,根据feed_list和data提供的信息,将输入数据转成一种特殊的数据结构
fetch_list=[avg_cost])
if batch_id % 40 == 0:
print("Pass:%d, Cost:%0.5f" % (pass_id, train_cost[0][0])) #打印最后一个batch的损失值
iter=iter+BATCH_SIZE
iters.append(iter)
train_costs.append(train_cost[0][0])
# 开始测试并输出最后一个batch的损失值
test_cost = 0
for batch_id, data in enumerate(test_reader()): #遍历test_reader迭代器
test_cost= exe.run(program=test_program, #运行测试cheng
feed=feeder.feed(data), #喂入一个batch的测试数据
fetch_list=[avg_cost]) #fetch均方误差
print('Test:%d, Cost:%0.5f' % (pass_id, test_cost[0][0])) #打印最后一个batch的损失值
训练过程图:

模型预测
需要构建一个使用训练好的模型来进行预测的程序,训练好的模型位置在 model_save_dir 。
with fluid.scope_guard(inference_scope):#修改全局/默认作用域(scope), 运行时中的所有变量都将分配给新的scope。
#从指定目录中加载 推理model(inference model)
[inference_program, #推理的program
feed_target_names, #需要在推理program中提供数据的变量名称
fetch_targets] = fluid.io.load_inference_model(#fetch_targets: 推断结果
model_save_dir, #model_save_dir:模型训练路径
infer_exe) #infer_exe: 预测用executor
#获取预测数据
infer_reader = paddle.batch(reader_creator(test_data), #测试数据
batch_size=20) #从测试数据中读取一个大小为20的batch数据
#从test_reader中分割x
test_data = next(infer_reader())
test_x = np.array([data[0] for data in test_data]).astype("float32")
test_y= np.array([data[1] for data in test_data]).astype("float32")
results = infer_exe.run(inference_program, #预测模型
feed={feed_target_names[0]: np.array(test_x)}, #输入光谱数据
fetch_list=fetch_targets) #得到推测含量
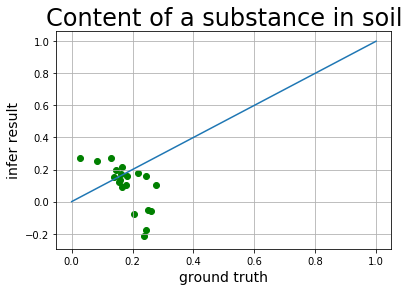
将结果进行可视化,横轴为实际含量,纵轴为根据光谱预测的含量,大部分得结果还是比较接近得。至此,我们获得了通过光谱看到土壤中某物质含量的火眼金睛啦!高光谱反演的用途还有许多,快快在AI Studio中fork项目展示出你的创意吧:
https://aistudio.baidu.com/aistudio/projectdetail/693750/
如在使用过程中有问题,可加入飞桨官方QQ群进行交流:1108045677。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
飞桨官网地址:
https://www.paddlepaddle.org.cn/
飞桨开源框架项目地址:
GitHub:
https://github.com/PaddlePaddle/Paddle
Gitee:
https://gitee.com/paddlepaddle/Paddle




