基于飞桨Res-Unet网络实现肝脏肿瘤分割任务
点击左上方蓝字关注我们

【飞桨开发者说】韩霖,PPDE飞桨开发者技术专家,吉林大学计算机科学与技术学院,主要研究医学影像方向。

项目背景
近年来,快速发展的深度学习技术已经渗透进了各行各业,医疗方面也不例外。这篇文章我主要介绍如何使用深度学习计算机视觉方法对CT扫描中的肝脏和肝脏肿瘤进行分割。
根据2018年的统计数据[1],肝脏肿瘤是全球第7常见的肿瘤,但致死病例总数却在所有肿瘤类疾病中排名第二。早发现早治疗能有效提升肝脏肿瘤疾病的治愈率,但人工在大量的肝脏CT影像中寻找体积很小的肿瘤工作量极大,也很容易漏检。这个场景下,使用深度学习算法自动进行快速、准确的肝脏及肝脏肿瘤分割筛查是一个很好的解决方案。
基于飞桨PaddlePaddle框架,我使用Res-Unet网络结构在 LiTS 数据集[2]上训练了一个分割网络,最终在肝脏和肝肿瘤上分别达到了 0.92 和 0.77 的分割准确率。LiTS数据集是目前最大的开源肝脏分割数据集,其中包含130名患者的CT扫描和医生对患者肝脏及肿瘤的分割标注,下图是数据集中的一个示例:
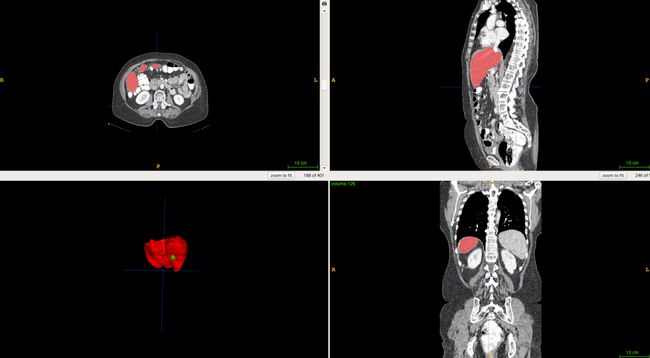
图1 肝脏分割示例
项目在AI Studio上公开,提供包含数据集在内的完整环境,fork后可以直接运行。
https://aistudio.baidu.com/aistudio/projectdetail/250994
此外还有更适合命令行执行的Github开源项目medSeg,经过性能优化,训练及推理速度更快。
https://github.com/davidlinhl/medSeg
网络结构介绍
本文中主要针对项目使用的网络结构,数据预处理及增强,Loss,训练和推理步骤进行描述。
首先简单介绍项目中用到的网络结构Res-Unet。在医学影像领域,Unet[3]结构因为其网络参数规模较小,实现简单,边界分割比较准确被广泛应用。其结构如下图所示:
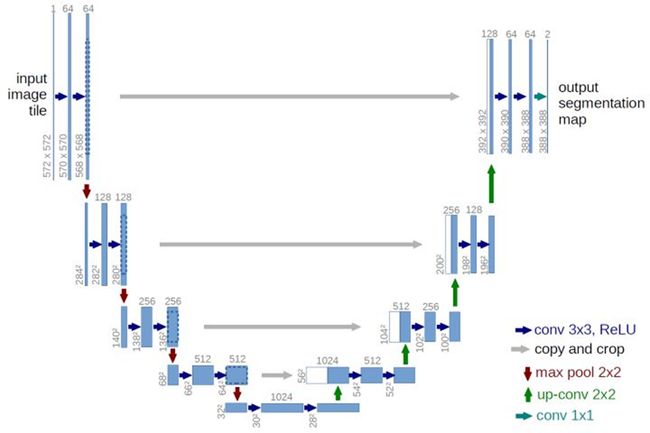
图2 Unet网络结构
其采用编码器-解码器结构,是一个 U 的形状,因此作者取名Unet。网络首先对输入图片进行了左边的4组卷积和下采样操作来获取图像的抽象特征,之后通过右边的对称的4组反卷积和上采样将图像放大回接近输入图像的大小。Unet的一个重要创新是在相同深度的下采样和上采样操作之间加入了跳转连接(图中横向灰色箭头所示),有效地提升了网络的分割精度。具体的实现方法一般是将左侧卷积block的输出拼接到右侧同一深度反卷积block的输入上。
这样反卷积block的输入特征图大小不变,但是厚度变成了原来的两倍。其中一半是绿色箭头代表的下层反卷积block的输入,给网络提供更抽象的高阶图像特征;另一半是灰色箭头代表的左侧卷积block的输出,给网络提供更准确的位置信息,提升边缘分割精度。
我使用的Res-Unet网络在Unet结构的基础上引入了残差连接,如下图所示。具体的做法是添加一条从两次卷积的输入到输出的连接,并做一次卷积操作。这种残差结构改善了网络的梯度流通,避免网络退化,并能加速网络收敛。
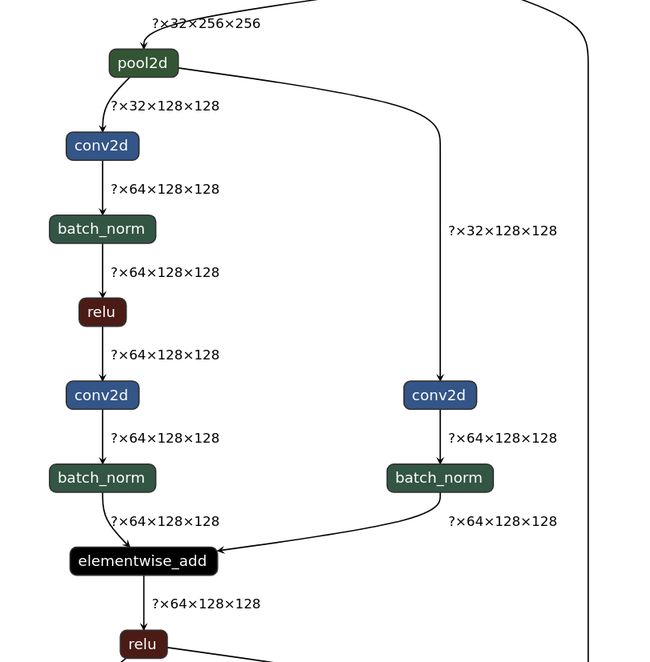
图3 残差连接
具体的网络构建代码比较复杂,这里不做详细展示,可以访问AI Studio项目或Github repo查看。
https://github.com/davidlinhl/medSeg/blob/master/medseg/models/unet.py
数据处理及增强
上述的Res-Unet结构是一个2D的分割网络,因此我们首先将LiTS数据集中3D的CT扫描分成2D的切片。CT在拍摄和重建的过程中会引入一些噪声,因此我们只保留-1024到1024范围内的数据。经过这两步处理,可以得到大概1万张CT扫描切片及对应的分割标签,随机选择一组进行可视化结果如下

图4 2D切片
在训练深度神经网络的过程中,我们通常需要在训练集上训练多个epoch以让网络达到一个比较高的训练准确率。但是这样做又容易使网络过拟合训练集,其表现为网络在训练集上准确率很高但是测试时准确率偏低。针对这个问题有多方面的解决方案,数据增强是其中重要的一种。这个项目中我们采用的数据增强策略包括随机水平、垂直翻转、随机旋转、随机尺度缩放、随机位置裁剪和弹性形变。在项目中可以看到具体代码,图5是对图4中数据进行数据增强的结果:

图5 数据增强效果
CT图像和分割标签共同进行了左右翻转,逆时针15度旋转,0.8倍尺度缩放和弹性形变。虽然一些简单的数据增强步骤过后图像看起来没有很大区别,但是只要图像有变化对算法来说就是新的数据,结合Droupout、权重正则化等方法能较好地抑制网络过拟合,提升测试准确率。
开始训练前的最后一个步骤是定义损失函数。飞桨PaddlePaddle框架为开发者准备了许多Loss函数,通过几行代码就可以方便地调用。这里我们采用交叉熵和Dice Loss结合作为模型的Loss。Dice评价我们网络分割输出和数据集中的实际分割结果有多大程度的重合,是我们最终的优化目标。但是Dice Loss在训练过程中不是很稳定,不利于网络收敛,因此加入了交叉熵来稳定训练。
def create_loss(predict, label, num_classes=2):
predict = fluid.layers.transpose(predict, perm=[0, 2, 3, 1])
predict = fluid.layers.reshape(predict, shape=[-1, num_classes])
predict = fluid.layers.softmax(predict)
label = fluid.layers.reshape(label, shape=[-1, 1])
label = fluid.layers.cast(label, "int64")
dice_loss = fluid.layers.dice_loss(predict, label) # 计算dice loss
ce_loss = fluid.layers.cross_entropy(predict, label) # 计算交叉熵
return fluid.layers.reduce_mean(ce_loss + dice_loss) # 最后使用的loss是dice和交叉熵的和
模型训练
万事俱备,下面可以开始训练了。首先使用静态图API进行组网
with fluid.program_guard(train_program, train_init):
# 定义网络输入
image = fluid.layers.data(name="image", shape=[3, 512, 512], dtype="float32")
label = fluid.layers.data(name="label", shape=[1, 512, 512], dtype="int32")
# 定义给网络训练提供数据的loader
train_loader = fluid.io.DataLoader.from_generator(
feed_list=[image, label],
capacity=cfg.TRAIN.BATCH_SIZE * 2,
)
# 创建网络
prediction = create_model(image, 2)
# 定义 Loss
avg_loss = loss.create_loss(prediction, label, 2)
# 定义正则项
decay = paddle.fluid.regularizer.L2Decay(cfg.TRAIN.REG_COEFF)
# 选择优化器
if cfg.TRAIN.OPTIMIZER == "adam":
optimizer = fluid.optimizer.AdamOptimizer(learning_rate=0.003, regularization=decay)
optimizer.minimize(avg_loss)
之后定义读取数据的reader
def data_reader(part_start=0, part_end=8):
data_names = os.listdir(preprocess_path)
data_part=data_names[len(data_names) * part_start // 10: len(data_names) * part_end // 10] # 取所有数据中80%做训练数据
random.shuffle(data_part) # 打乱输入顺序
def reader():
for data_name in data_part:
data=np.load(os.path.join(preprocess_path, data_name) )
vol=data[0:3, :, :]
lab=data[3, :, :]
yield (vol, lab)
return reader
将数据增强操作整合进一个函数
def aug_mapper(data):
vol = data[0]
lab = data[1]
vol, lab = aug.flip(vol, lab, cfg.AUG.FLIP.RATIO)
vol, lab = aug.rotate(vol, lab, cfg.AUG.ROTATE.RANGE, cfg.AUG.ROTATE.RATIO, 0)
vol, lab = aug.zoom(vol, lab, cfg.AUG.ZOOM.RANGE, cfg.AUG.ZOOM.RATIO)
vol, lab = aug.crop(vol, lab, cfg.AUG.CROP.SIZE, 0)
return vol, lab
数据增强操作涉及旋转和弹性形变,计算比较复杂,耗时长,如果只使用单线程进行数据读取和增强会拖慢网络的训练速度。但使用飞桨PaddlePaddle框架,只需两行代码就可以将单线程reader变成多线程,大幅提升训练效率。在AI Studio的测试环境中,8线程reader让训练速度提升了7倍以上。
train_reader = fluid.io.xmap_readers(aug_mapper, data_reader(0, 8), 8, cfg.TRAIN.BATCH_SIZE * 2)
train_loader.set_sample_generator(train_reader, batch_size=cfg.TRAIN.BATCH_SIZE, places=places)
最后一步就是进行训练,以下是训练中进行前向和反向梯度传递的核心代码,其余的输出,验证等操作可以视需要添加。
step = 0
for pass_id in range(cfg.TRAIN.EPOCHS):
for train_data in train_loader():
step += 1
avg_loss_value = exe.run(compiled_train_program, feed=train_data, fetch_list=[avg_loss])
print(step, avg_loss_value)
LiTS数据集比较大,我们选择的Res-Unet也比较复杂,整个训练过程大概需要20个epoch,6个小时左右的时间完成。
推理预测
训练完成后保存模型,我们就可以对新的数据进行分割了。进行分割前我们同样需要将数据转化为2D切片,并保留相同的强度范围。经过网络前向处理后将数据从2D合并为原来的3D形态
segmentation = np.zeros(scan.shape)
with fluid.scope_guard(inference_scope):
# 读取预训练权重
[inference_program, feed_target_names, fetch_targets] = fluid.io.load_inference_model(infer_param_path, infer_exe)
for slice_ind in tqdm(range(1, scan.shape[2]-1)):
# 2.5D的输入,每次取出CT中3个相邻的层作为模型输入
scan_slice = scan[:, :, slice_ind - 1: slice_ind + 2]
# 添加batch_size维度
scan_slice = scan_slice[np.newaxis, :, :, :]
# 模型的输入是 CWH 的, 通道在第一个维度,因此需要将数组中的第一和第三个维度互换
scan_slice = scan_slice.swapaxes(1,3)
result = infer_exe.run(inference_program, feed={feed_target_names[0]: scan_slice }, fetch_list=fetch_targets)
result = result[0][0][1].reshape([scan.shape[0], scan.shape[1]])
# 保存分割结果
segmentation[:, :, slice_ind] = result.swapaxes(0,1)
# 预测概率超过 0.5 的部分认为是前景,否则认为是背景
segmentation[segmentation >= 0.5] = 1
segmentation[segmentation < 0.5 ] = 0

图6 分割结果
深度学习算法对一组CT扫描进行分割大概耗时15S,其效率明显高于医生阅片的效率。而且从分割结果中,我们可以计算获得肝脏体积,肿瘤数量,肿瘤体积,肝脏肿瘤负担等数量化的指标,更好地辅助医生进行诊断。
项目内容到这里就介绍完了,如果你对深度学习医疗应用感兴趣,欢迎加入 AI Studio医疗兴趣小组和更多大佬一起学习进步,QQ群号:810823161
·Reference·
[1] https://pubmed.ncbi.nlm.nih.gov/30207593/
[2] https://aistudio.baidu.com/aistudio/datasetdetail/10273
[3] https://arxiv.org/abs/1505.04597
·飞桨官网地址·
https://www.paddlepaddle.org.cn/
·飞桨开源框架项目地址·
GitHub:
https://github.com/PaddlePaddle/Paddle
Gitee:
https://gitee.com/paddlepaddle/Paddle

扫描二维码 | 关注我们
微信号 : PaddleOpenSource