【pytorch】(deeplizard14-21)CNN 加载数据 | 构建神经网络 | 前向传播
p14 fashion-mnist数据集
mnist数据集是一个非常出名的用于训练机器学习的图像处理系统的数据集,这个数据集是由七万张手写的数字图像组成
p15 torchvision——提取、转换、加载流程
torchvision是pytorch的用于深度学习的计算机视觉包
四个步骤:
1、准备数据:E-T-L 提取(extract)-转换(transfrom)-加载(load)
2、构建模型:
3、训练模型、
4、分析模型结果
- 准备数据
extract:从源获取fashion-mnist数据
transform:将图像数据转换成一个pytorch张量
load:将数据放入一个使其易于访问的对象中
pytorch提供了两个类:dataset数据集、dataloader数据加载器
dataset数据集:torch.utils.data.Dataset
dataloader数据加载器:torch.utils.data.DataLoader

torchvision可以让我们接触到四个东西:dataset、models(比如vgg-16或其他的模型)、transform、utils实用程序
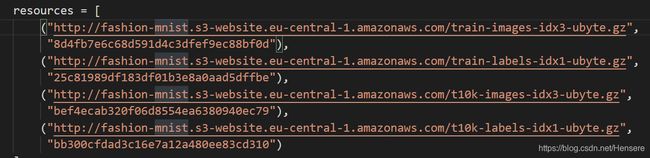
torchvision中fashion-mnist的源码:
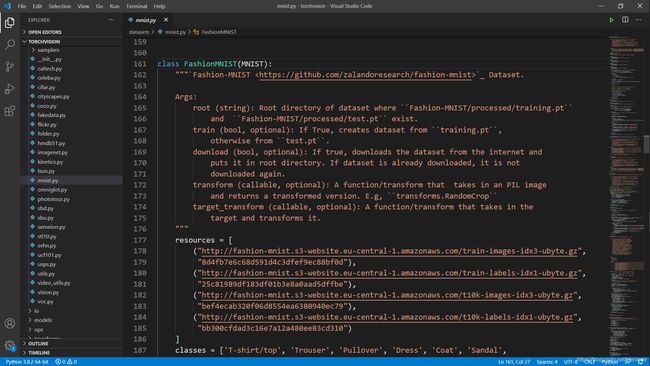
fashion-mnist是mnist的替换,唯一需要改变的是交换url
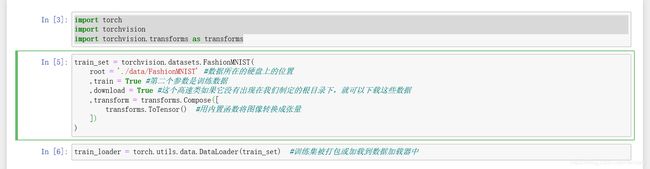
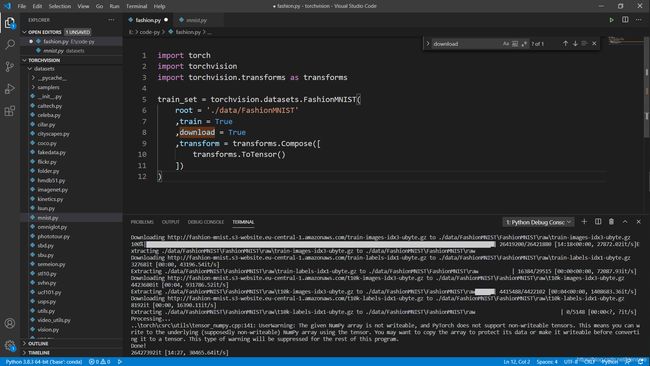
使用torchvision获得一个fashion-mnist数据集的实例:
p16 熟悉训练集及其中的数据
记住,我们有两个pytorch对象,数据集(也称训练集)和数据加载器(也称加载器)
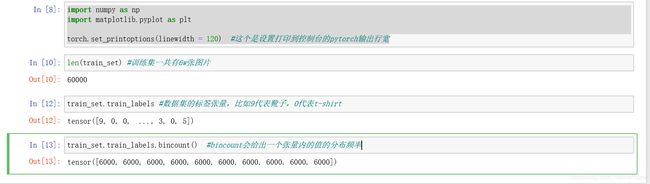
bincount()得出fashion-mnist数据集与对应的每个类的样本数是一致的,如果每类有不同数量的样本,我们将称这个数据集为不平衡的数据集
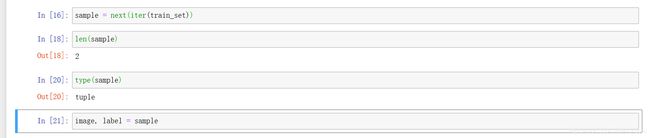
训练集对象传递给python的内置函数,iter():他返回一个表示数据流的对象,然后可以进行迭代。
next():有了大量的数据之后,可以使用python构建的next()函数来获取流中的下一个数据元素。
可以看到实例中包含两个项目。
数据集中包含的是图像标签对,我们从训练集中获取的每个样本都包含图像数据张量,以及相应的标签张量image, label = sample à image = sample[0] label = sample[1]
打印出一张图片:
![]()
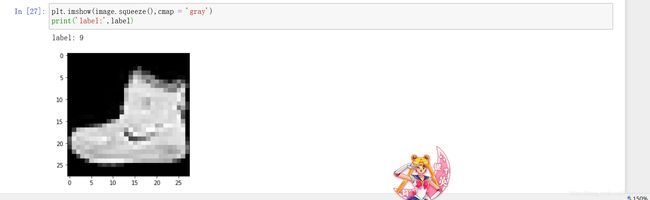
gray:表示只有一个颜色通道,灰色通道
这时有一个高度和宽度分别为28的通道,标签是一个标量值,所以有一个没有形状的标量张量(label:9)
imgshow():图像显示函数,我们传递的图像张量及其颜色通道轴被压缩
颜色参数用gray
处理批量和数据加载器:
打印10个:

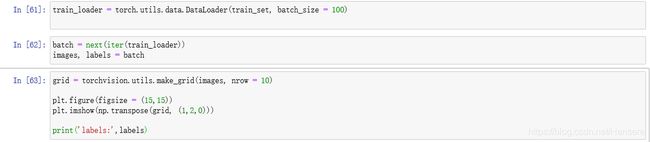
得到的结果是标签序号为9,0,0,3,0,2,7,2,5,5的十张图片
grid:使用grid = torchvision.utils.make_grid()函数创建了一个网络,括号里,图像张量作为第一个参数,第二个参数nrow赋值为10,指定每一行的图像数量,这样所有图像就会沿着一行展示
plt:是指定的一些管道配置,使用plt.imshow(np.transpose(grid,(1,2,0)))让轴满足图像的功能需要的规格
打印100个:
结果:

p17 构建神经网络
- 构建模型(网络)
网络 == 模型
希望模型近似一个将输入图像映射到正确输出类的函数
对象、类:
类class:像一个实际对象的蓝图或描述
对象:是事物本身
一个给定类的所有实例都有两个核心组件,方法 & 属性;
方法代表code,属性代表数据data,方法和属性都是由类定义的。我们可以将属性用于描述对象的特征,方法用于描述对象的行为。
在一个程序中,许多对象,也就是给定类的实例可以同时存在,一个特定类的所有实例在相同可用方法中都具有相同的可用属性。同一对象的不同之处,在于每个属性的对象中包含的值,每个对象都有自己的属性值。
每个对象的代码和数据,可以说是封装在对象中的。
类被认为是包含代码和数据的自包含单元,所以可以把它看作是把属性和方法打包在一起,然后封装到类中。
我们创建类的实例来执行我们程序中的任务。
eg:

定义一个类lizard,第二行定义了一个称为类构造函数的特殊方法,当类的对象(新实例)被创建为这个特殊构造函数的参数的时候,就会调用构造函数。
init函数中,有一个名为self的name的参数(init和self是必须构造的)
self:使我们能够创建存储或封装在类对象中的属性值。当我们调用这个构造函数时,我们没有通过参数来传递self参数,是由python在后台做的。
任何其他参数的参数值都是由调用者任意传递的。在完成构造函数之后,可以创建任意数量的自定义方法,比如set_name():
eg:



pytorch的神经网络库:torch.nn
oop对象编程
每一个pytorch.nn.module都有一个前向方法来代表前向传播,所以神经网络中构建层时,必须提供前向方法的实现
在cnn中创建一个神经网络
- extend the nn.Module base class.
- 在类构造函数中将网络层定义为类属性
- 使用网络层属性以及API来定义网络的前向传输
简单的网络:

ptorch神经网络:

有了line1和line3就构成了一个神经网络类,它具有pytorch.nn模块类的所有功能
这样的好处是,在覆盖之下,模块基类可以保持跟踪每个层中包含的网络的权重
现在用一写真正的图层来代替pytorch的神经网络库
加入线性层 & 卷积层:
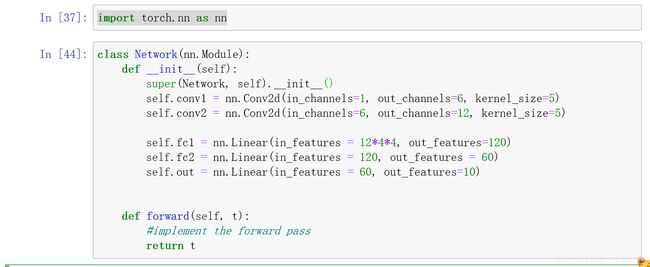
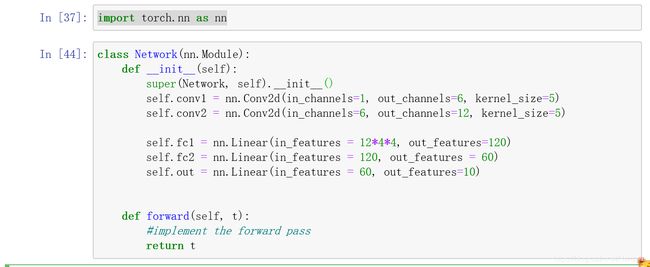
如果要扩展一个类,可以用super关键字访问他的方法
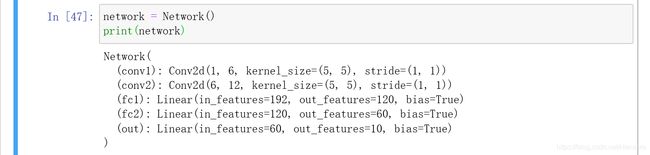
有一个名为Network的python类,扩展了pytorch的nn.module类
我们有两个复合层(卷积层):conv1和conv2,三个线性层(全连接):fc1,fc2,和out输出层
线性层也被称为全连接层 或者dense
通过调用构造函数来获得网络实例:

p18 CNN层参数的含义
利用继承这个功能,将我们的层标记为内部或网络模块中的属性
parameter / argument:
parameter是函数定义时候的一个占位符(形参)
而argument是当函数被调用时传递给函数的实际值(实参)
参数:
卷积层有三个参数:输入/输出通道,核大小
线性层有两个参数:输入/输出特征
为了构建一个CNN层,我们需要手动选择一些参数:内核大小、输出通道大小、输出特征大小
内核大小:设置了在该层中使用的滤波器的大小
【内核 == 滤波器 / 卷积核 == 卷积滤波器】
在一个卷积层内,输入通道与一个卷积滤波器配对来执行卷积运算,滤波器可以包含输入通道,这个操作的结果就是一个输出通道 à 所以一个包含输入通道的滤波器可以给我们一个对应的输出通道 à 所以设置输出通道时实际上是在设置滤波器的数量
in_channels = 1 à out_channels = 6
一个输入通道对应有六个输出通道 在线性层也叫六个特征图 所以out_features
超参数:
超参数:在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。
依赖的超参是在网络的开始的末端,即第一个卷积层的输入通道in_channels = 1以及最后一个线性层的输出特征out_features = 10
第一个卷积层的输入通道依赖于构成训练集的图像内部的彩色通道的数量,因为处理的是灰色图像,所以这个值是1 in_channels = 1
因为我们再fashion-minst数据集里有十种服装,所以需要输出10个特征来判断是个类别 out_features = 10
然后中间每一层的输入是上一层的输出,所以卷积层的所有输入通道和线性层中的输入特征都依赖于来自上一层的数据,所有这些都是依赖于数据的超参数
in_channels = 1 in_channels = 6 in_features = 12*4*4 infeatures = 120 in_features = 60
从卷积层到线性层需要使张量变平,所以用12*4*4作为输入的特征数,12来自于上一层的输出通道数量,4*4是the size of feature map
p19 CNN内部的权重张量
这里kernel_size(5,5)两个5,是因为我们滤波器实际上有一个高度和宽度,我们传入了一个数组,而层构造函数中的代码假设我们想要一个正方形的滤波器
strid步长:没有指定时层会自动添加,步长告诉了卷积层在整个卷积过程中,每个操作之后,滤波器应该滑动的距离;stride=(1,1)表示向右移动一个单位,且向下移动一个单位
bias默认值为ture,可以设置为false来关闭
学习参数:
即在训练过程中,网络学习时这些值会以迭代的方式更新
网络正在学习:学习规则参数的适当值,即学习最小化损失函数的值
可以学习的是网络中的权重,存在于每一层:
self.weight = nn.Parameter(torch.Tensor(out_features, in_features))
当我们键入类名后面跟着圆括号,代表当这句代码执行的时候,init类构造函数中的代码将会运行
我们的网络类是从pytorch Module基类继承这个功能的
卷积层的权重张量
第一个卷积层的权重




权重值对卷积层的影响:权重在滤波器内的值,对滤波器进行编码的实际上是权重张量本身
张量的形状编码了我们需要知道的关于张量的所有信息
conv1中:我们有一个颜色通道,它包含了6个5*5的滤波器,产生6个输出通道
而张量的形状告诉我们:有一个秩为4的张量,第一个轴的长度是6
conv2中:第二个轴为6,有6个颜色通道,是由上一个conv1传进来的,说明张量内的每个滤波器也有一个深度,可以解释所涉及到的输入通道
总结:第一个轴代表滤波器数量,第二个轴代表每个滤波器深度以及对应的输入通道的数量,最后两个轴代表每个滤波器的高度和宽度

这给了我们一个单独的滤波器,他的高度和宽度是5,深度为6
线性层的权重张量
线性层使用矩阵乘法来将他门的输入特征转换为输出特征

在线性层,我们将张量压平成秩为1的张量来作为输入和输出
可以看到每个线性层都有一个秩为2的张量作为权重张量,一个轴为高度是期望的输出特征的值二个轴是输入特征的值,这是由于矩阵乘法得到的执行结果
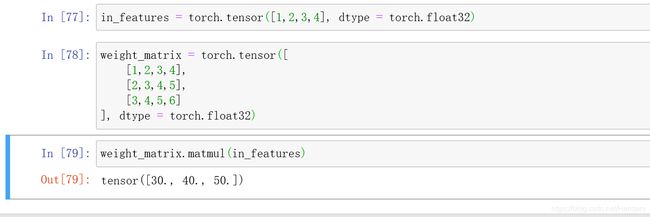
矩阵乘法:
同时访问所有参数:
方法一:

方法二:

P20 线性层的深度
eg1:
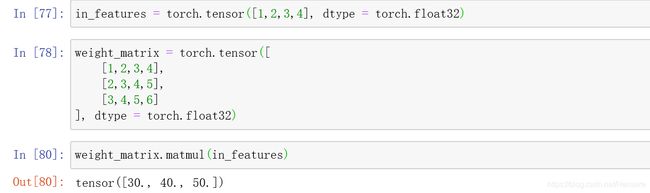
这里矩阵乘法将一个四维的映射成为了一个三维的
可以把这个函数想象成一个从四维的欧几里得空间到三维欧几里得空间的映射,利用了一个权重矩阵将一个输入特征空间映射到输出特征空间
eg2:

可以看到得到的张量里的值是不同的,因为这两个例子中的线性函数不同
总结:权重矩阵中的值,定义了一个线性函数
eg3:

可以看到当把权重矩阵改成eg1中的时,得到的值更接近与30,40,50了
不是精确的30,40,50,是因为线性层在输出中增加了一个偏置张量,可以用bias=false关掉
__call__(input)
里面有前向方法的实现
P21 神经网络中的前向方法(前向传播)
实现了前向方法之后就可以开始训练模型了
前向方法:是输入张量到一个预测的输出张量的映射
输入层:input layer
f(x) = x

卷积层:conv

第一个卷积层的输出张量t被传递到下一个卷积层conv2,第二个卷积层与第一个一样
每一层都由一组权重和一组操作组成,权重被封装在神经网络模块层类实例(对象)中;
relu操作和最大池化操作都是纯操作,没有权重(可以直接从nn.functional API调用他们)
F:import torch.nn.functional as F
激活操作 == 激活层 / 池化操作 == 池化层
层与操作不同的是,层有权重,而操作没有。池化操作和激活函数没有权值
比如:网络中的第二层是一个卷积层,他包含一个权重集合并执行三个操作,一个卷积运算、一个值激活操作和一个最大池操作
整个网络仅仅是一个函数的组合,NOW我们做的是在我们的前向方法中定义这个函数组合
卷积层:做一个运算,形成feature map
激活层:取一个最大值,大于0的去本值,小于等于0的取0
池化层:去值,减少数据量
线性层:linear
在把输入传递给第一个隐藏的线性层之前,必须要重塑平坦的张量

12是由之前的卷积层产生的输出通道的数量决定的
4*4实际上是12个输出通道的高度和宽度,比如一个[1,28,28]的张量输入,到了线性层被减少成为了4*4,这种减少是由于卷积和池化操作造成的
张量reshape之后,我们把一个扁平的张量传递给了线性层,并把它的结果传递给relu激活函数
输出层:output

输出10个预测
除了输入和输出层,其它层统称为隐藏层,我们通常使用relu作为我们的非线性激活函数
但是对于输出层,我们有一个单独的类别要预测,使用的都是softMax激活函数
SoftMax函数为每个预测类返回一个正的概率,这些概率之和为1
在本例中不使用softMax,因为如果在训练过程中使用的损失函数有隐形的softMax()
我们网络使用softMax操作进行训练,但是在训练过程完成后,将不需要计算额外的操作