Objects as Points论文总结
《Objects as Points 论文总结》
本人逐字翻译了CenterNet 之 Objects as points的论文,这里主要整理CenterNet中提到的知识点,以及写下自己的感悟和看法,主要从主干网络、监督方式以及我目前对anchor free的理解。方便后续对CenterNet的复习。
Key Words:Bottom-up、监督方式、Anchor free、推理增强
CVPR, 2019
Agile Pioneer
文章目录
-
-
- Bottom-up
- 监督方式
-
- 目标检测
- 姿态估计
- Anchor free
- 推理增强
- 缺点
-
Bottom-up
Encoder-Decoder模型结构能cover绝大多数的场景,标准的Encoder-Decoder是对称的网络结构,通过卷积+下采样进行图像编码,得到高层语义信息。而后通过转置卷积或插值等上采样方法进行Decoder。当然这种结构也不限于CNN,也可以用RNN以及全连接之类的进行编解码。
Encoder-Decoder模型结构可以做图像语义分割、Crow Count、AutoEncoder以及各种生成模型,其优点在于可以逐像素的进行分类(Focal Loss)或回归(MSE),感觉上监督的范围更广,所以对各种任务的普适性更强。
CenterNet的主干网络采取了类似于编解码的方式进行预测,target与原图相比下采样了4倍,是一个不对称的编解码模型,这也是借鉴了openpose、hourglass等文章的做法。我理解这样的做法能够降低图像的视觉冗余性,抗噪的同时还降低了运算量,下采样四倍对于目标检测以及关键点估计来说不会有太大的损失。而且这里Center采用了对量化产生的误差加了一项offset回归。
CenterNet在上采样阶段采用的可变形卷积,这对提高精度很有帮助,有空还需要拜读一下可变形卷积v1和v2的论文。
DLA-34 DenseNet Hourglass-104 都是关键点估计网络不错的backbone选择
监督方式
目标检测
GroundTruth:对原图下采样4倍,然后对目标中心点位置进行二维高斯和卷积。对于高斯核卷积两个物体的重叠部分,取重叠元素的最大值

预测head:中心点的类别(K个类别channel的heatMap)、中心点的size(2个channel,W和H)、量化offset(2个channel,X和Y)
*损失函数:

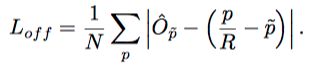
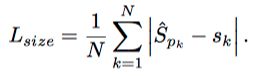
![]()
点变为框的方式

每个目标仅仅有一个正的锚点,因此不会用到NMS,提取关键点特征图上局部峰值点(local peaks)使用3x3的mac pooling即可。
姿态估计
损失函数:关键点和目标检测的中心点的损失函数一样,关键点到中心点回归用L1 loss,回归offset也是用L1 loss。
预测head:「C个类别,K个关键点」
- 中心点(C个类别channel)
- 中心点的size(2个channel,W、H)
- 中心点的量化offset(2个channel,X和Y)
- 关键点到中心点的距离(2*K个channel)
- 关键点的heatMap(K个channel)
- 关键点的offset(2个channel,X和Y)
技巧:文中说过通过对关键点的回归得到的结果是无法达到SOTA水平的,所以作者巧妙的把回归的结果和bottom up的结果进行了结合,不需要像openpose一样的复杂后处理算法就能够对关键点进行分组,非常值得学习。
Anchor free
最早一代的Anchor free模型当数yolo v1了,此后进入了SSD为代表的AnchorBased时代,SSD可谓是把anchor机制用到了极致。anchor极致之能够有效的原因是对特征的featureMap上每个点都做了几乎可以涵盖所有目标的预设anchor,预设的越多,运算量越大,模型也就越准确。但实际我们使用的场景里这些预设的anchor的利用率并不高,所以很多的运算其实都是徒劳的,这也就引发了anchor free再度兴起。
我理解的anchor free没有显式的对每个位置的各种建议框的尺寸和比例进行预设而已,但是位置信息还是有所保留的,比如CenterNet的做法就是在关键点处进行回归,可以理解为这个点其实也是一个"anchor",基于目标的中心进行的回归,也是非常合理的。可以认为anchor-free 和每个位置有一个正方形 anchor 在形式上可以是等价的,也就是利用 FCN 的结构对 feature map 的每个位置预测一个框,这也就是为什么bottom up的模型效果很好的原因。
anchor-free 的方法由于网络结构简单,对于工业应用来说可能更加友好。对于方法本身的发展,我感觉一个是新的 实例分割流程,因为 anchor-free 天生和 segmentation 更加接近。
能够用简单的方法来代替目前复杂的目标检测方法是一个质的飞越。
推理增强
论文的实验中用到了推理增强,这是一个屡见不鲜的技巧,通过损失推理效率来增加精度的方法。
分类中我们可以对原图进行crop或flip等,然后结果取众数。
分割中我们也可以对原图进行flip,得到结果后在flip回来,叠加在一起。
论文中使用的方法是在解码前对推理增强的结果取平均,然后在进行解码。
缺点
当中心点重合的时候CenterNet就没有办法处理了,如果能保持CenterNet的优势,在想办法解决这个问题,下个中CVPR的可能就是你。