剑指数据仓库-Hadoop一
一、上次课程回顾
二、初识Hadoop
- 2.1、Hadoop软件
- 2.2、Hadoop的伪分布式部署
- 2.3、Hadoop部署之密钥文件解析
- 2.4、Hadoop三进程都以hostname进行启动
- 2.5、Hadoop的安装过程总结
- 2.6、Hadoop的web页面解读
- 2.7、初识hdfs命令
三、本次课程作业
一、上次课程回顾
- https://blog.csdn.net/SparkOnYarn/article/details/104904205
二、初识Hadoop
Hadoop的官网:hadoop.apache.org、spark.apache.org、kafka.apache.org
广义:以apache hadoop软件为主的的生态圈(hive、SQOOP、flume、flink、hbase…)
狭义:单纯的指apache hadoop软件
apache hadoop软件:
1.x:基本不用
2.x:现在市场主流,对应的cdh5.X
3.x:有一些企业尝试使用,cdh对应的版本就是cdh6.X
-
cdh版的hadoop的下载网址,本次课程的组件主要使用cdh的官方提供的:
http://archive.cloudera.com/cdh5/cdh/5/
http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.16.2.tar.gz -
这就说明了hadoop的版本是2.6.0,我们使用的cdh版本的2.6.0,他可以媲美apache hadoop2.9
hadoop-2.6.0-cdh5.16.2.tar.gz
apache hadoop2.6.0 + 以后的patch==apache hadoop2.9 -
如下cdh hadoop的每一个版本都会进行升级打包,比如某个组件有bug,我们从cdh5.14升级到cdh5.16,进入到changes.log进行查看升级即可。
CDH5.14.0 hadoop-2.6.0
CDH5.16.2 hadoop-2.6.0 -
apache的hadoop2.9、3.X版本已经出现了,apache基金会的hadoop是开源的,其主要bug是由cloudera公司的人员进行提交代码、推进的。
-
使用cdh版本hadoop的好处:版本兼容性不必考虑,比如未来要安装hbase,hbase安装的分支也需要和hadoop一样在cdh5.16.2这个分支下。
http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.16.2-changes.log
http://archive.cloudera.com/cdh5/cdh/5/hbase-1.2.0-cdh5.16.2-changes.log
2.1、Hadoop软件
hdfs 存储
mapreduce 计算 作业 挖掘出有价值的数据进行挖掘 --> hive sql spark flink
yarn 资源(内存、Vcore)调度+作业调度
大数据就是由海量数据组成,一台机器完成不了存储,一台机器是一个单点计算;比如我们有1000台的机器,是由hdfs进行存储,mapreduce进行分布式存储,yarn根据cpu、内存来进行资源
作业调度。
为什么mapreduce在业界不用呢?
- 开发难度大,代码量大,维护困难,计算慢,所以大家基本不会使用MR
- 课程版本:hadoop-2.6.0-cdh5.16.2
2.2、Hadoop的部署
1、创建用户、解压软件
1、创建hadoop用户:
- useradd hadoop
2、mkdir app data lib log software sourcecode tmp
[hadoop@hadoop ~]$ ll
total 28
drwxrwxr-x 3 hadoop hadoop 4096 Mar 20 16:21 app 压缩包解压后的文件夹 尽量做软连接
drwxrwxr-x 2 hadoop hadoop 4096 Mar 8 17:49 data 数据目录
drwxrwxr-x 2 hadoop hadoop 4096 Mar 20 16:23 lib 第三方的jar
drwxrwxr-x 2 hadoop hadoop 4096 Mar 20 16:23 log 日志文件夹爱
drwxrwxr-x 2 hadoop hadoop 4096 Mar 8 20:27 software 压缩包
drwxrwxr-x 2 hadoop hadoop 4096 Mar 20 16:23 sourcecode 源代码编译
drwxrwxr-x 2 hadoop hadoop 4096 Mar 20 16:23 tmp 临时文件夹
//linux本身已经自带了tmp目录,为什么我们还要建一个tmp目录呢,系统自带的会30天定期删除。
3、进行解压缩,并且做一个软连接:
[hadoop@hadoop ~]$ tar -xzvf hadoop-2.6.0-cdh5.16.2.tar.gz -C /home/hadoop/app/
[hadoop@hadoop app]$ ln -s hadoop-2.6.0-cdh5.16.2 hadoop
软件的安装前提:java环境、ssh无密码
2、安装java jdk环境:
1、mkdir /usr/java,创建这个目录
2、rz把软件进行上传,解压到这个目录以后配置环境变量,如下所示:
#env
export JAVA_HOME=/usr/java/jdk1.8.0_45
#export JAVA_HOME=/usr/java/jdk1.7.0_45
export PATH=$JAVA_HOME/bin:$PATH
"/etc/profile" 82L, 1900C written
3、使的环境变量生效:
[root@hadoop java]# source /etc/profile
[root@hadoop java]# which java
/usr/java/jdk1.8.0_45/bin/java
[root@hadoop java]# echo $JAVA_HOME
/usr/java/jdk1.8.0_45
[root@hadoop java]# java -version
java version "1.8.0_45"
Java(TM) SE Runtime Environment (build 1.8.0_45-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.45-b02, mixed mode)
3、编辑hadoop-env.sh
[hadoop@hadoop hadoop]$ vi hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/usr/java/jdk1.8.0_45
4、了解hadoop部署的几种模式:
- Local (Standalone) Mode 本地模式,不用
- Pseudo-Distributed Mode 伪分布式模式,学习,测试的时候只需要1台即可
- Fully-Distributed Mode 分布式模型在集群模式下,用于生产环境。
5、开始修改core-site.xml
//vi /etc/hosts,需要配置好ip和hostname的映射:
106.54.226.205 hadoop
1、修改etc/hadoop/core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
</configuration>
2、修改etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
6、配置ssh hadoop无密码:
[root@hadoop ~]# pwd
/root
[root@hadoop ~]# rm -rf .ssh
[root@hadoop ~]# ssh-keygen
//连续三次回车
[root@hadoop ~]# cd .ssh
[root@hadoop .ssh]# ll
total 8
-rw------- 1 root root 1671 Mar 20 17:26 id_rsa
-rw-r--r-- 1 root root 393 Mar 20 17:26 id_rsa.pub
//把公钥文件追加到信任文件中:
[root@hadoop .ssh]# cat id_rsa.pub >> authorized_keys
//权限修改为600
[root@hadoop .ssh]# chmod 600 authorized_keys
//测试如下没问题:
[hadoop@hadoop001 .ssh]$ ssh hadoop001 date
Tue Mar 24 15:19:49 CST 2020
遇到了个问题:
连接超时:
[hadoop@hadoop001 ~]$ ssh hadoop001 date
ssh: connect to host hadoop001 port 22: Connection timed out
本次原因(在/etc/hosts中内网ip+hostname配置错误):
[hadoop@hadoop001 ~]$ ssh hadoop001 date
The authenticity of host 'hadoop001 (172.17.0.5)' can't be established.
RSA key fingerprint is 33:6f:23:f9:ff:10:39:2d:cd:42:72:66:c8:7d:5a:6a.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'hadoop001,172.17.0.5' (RSA) to the list of known hosts.
Tue Mar 24 15:25:19 CST 2020
坑:root用户部署ssh,600权限不需要修改;而使用其它用户的时候,需要进行600权限修改。
7、配置环境变量&&生效环境变量&&which hadoop:
#env
export HADOOP_HOME=/home/hadoop/app/hadoop
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
source ~/.bashrc
[hadoop@hadoop001 app]$ source ~/.bashrc
[hadoop@hadoop001 app]$ which hadoop
~/app/hadoop/bin/hadoop
[hadoop@hadoop001 app]$ which hdfs
~/app/hadoop/bin/hdfs
8、格式化:
- hdfs namenode -format 出现如下这句话就说明没问题:20/03/24 15:42:16 INFO common.Storage: Storage directory /tmp/hadoop-hadoop/dfs/name has been successfully formatted.
9、进行启动:(第一次启动会让我们输入一个yes)
[hadoop@hadoop001 sbin]$ which start-dfs.sh
~/app/hadoop/sbin/start-dfs.sh
[hadoop@hadoop001 sbin]$ start-dfs.sh
20/03/24 15:50:56 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
20/03/24 15:50:57 WARN hdfs.DFSUtil: Namenode for null remains unresolved for ID null. Check your hdfs-site.xml file to ensure namenodes are configured properly.
Starting namenodes on [hadoop]
hadoop: ssh: Could not resolve hostname hadoop: Name or service not known
localhost: starting datanode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.16.2/logs/hadoop-hadoop-datanode-hadoop001.out
Starting secondary namenodes [0.0.0.0]
The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established.
RSA key fingerprint is 33:6f:23:f9:ff:10:39:2d:cd:42:72:66:c8:7d:5a:6a.
Are you sure you want to continue connecting (yes/no)? yes
博客参考:
-
http://blog.itpub.net/30089851/viewspace-2127102/ 故障(修改用户和用户组)
ssh 除了第一次认证以外还是需要密码的话需要去查看系统日志。 -
http://blog.itpub.net/30089851/viewspace-1992210/ ssh多台 高级班会讲 坑
2.3、Hadoop部署之密钥文件解析
1、注意:
hadoop001是启动namenode,0.0.0.0上是启动secondarynamenode;localhost启动的是datanode;
为什么第一次要输入yes,查看~/.ssh/known_hosts
[hadoop@hadoop001 hadoop]$ start-dfs.sh
20/03/24 15:53:35 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [hadoop001]
hadoop001: starting namenode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.16.2/logs/hadoop-hadoop-namenode-hadoop001.out
localhost: starting datanode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.16.2/logs/hadoop-hadoop-datanode-hadoop001.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.16.2/logs/hadoop-hadoop-secondarynamenode-hadoop001.out
20/03/24 15:53:54 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
查看这个信任文件记录,第一次输入yes那句话是维护在known_hosts文件;
[hadoop@hadoop001 .ssh]$ cat known_hosts
localhost ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEA0RbK9Erb/qkvjdPvION6G35oFhaS8ZfA13dyILU069Hzd36i2tgUZa9D4IPbvZNk6DvDFW2zH8jW/j1RS99ZZ4+9yl/CrcrJRP9GjjBS2W1rQCUjolRdLf9PzAZs/AbFvpjxwMbd7vSb5AOeqQ0pTC4BFlvX6IJLGdZmhUYTqNCWj0e40l409o/Hidy0oEXByDaJWmRvRuI6jc5V1v9/FZNze96W/oJC6FLR7MrVgSJA2MmZvzvS3zbCgKU/umgD4ENy+JRBiifHwBWVTkIADHhVq7Ob14eFlawVnEY6tQkdgrwSc2LWBgFQXAYbYmeFLOrEJQKi3e/h4fMLaoeubQ==
hadoop001,172.17.0.5 ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEA0RbK9Erb/qkvjdPvION6G35oFhaS8ZfA13dyILU069Hzd36i2tgUZa9D4IPbvZNk6DvDFW2zH8jW/j1RS99ZZ4+9yl/CrcrJRP9GjjBS2W1rQCUjolRdLf9PzAZs/AbFvpjxwMbd7vSb5AOeqQ0pTC4BFlvX6IJLGdZmhUYTqNCWj0e40l409o/Hidy0oEXByDaJWmRvRuI6jc5V1v9/FZNze96W/oJC6FLR7MrVgSJA2MmZvzvS3zbCgKU/umgD4ENy+JRBiifHwBWVTkIADHhVq7Ob14eFlawVnEY6tQkdgrwSc2LWBgFQXAYbYmeFLOrEJQKi3e/h4fMLaoeubQ==
0.0.0.0 ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEA0RbK9Erb/qkvjdPvION6G35oFhaS8ZfA13dyILU069Hzd36i2tgUZa9D4IPbvZNk6DvDFW2zH8jW/j1RS99ZZ4+9yl/CrcrJRP9GjjBS2W1rQCUjolRdLf9PzAZs/AbFvpjxwMbd7vSb5AOeqQ0pTC4BFlvX6IJLGdZmhUYTqNCWj0e40l409o/Hidy0oEXByDaJWmRvRuI6jc5V1v9/FZNze96W/oJC6FLR7MrVgSJA2MmZvzvS3zbCgKU/umgD4ENy+JRBiifHwBWVTkIADHhVq7Ob14eFlawVnEY6tQkdgrwSc2LWBgFQXAYbYmeFLOrEJQKi3e/h4fMLaoeubQ==
补充一个坑:
比如我们的公钥文件已经发生了变更,在执行命令的时候会出现一个记录,存在一个旧的连接,只要找到这条记录给他删掉就行;工作中如果碰到ssh信任的错误,下意识的要去这个文件中找。
测试修改localhost在known_hosts中的记录:
1、修改内容后尝试重新启动会发现失败了
localhost: key_from_blob: can't read key type
localhost: key_read: key_from_blob EEEEB3NzaC1yc2EAAAABIwAAAQEA0RbK9Erb/qkvjdPvION6G35oFhaS8ZfA13dyILU069Hzd36i2tgUZa9D4IPbvZNk6DvDFW2zH8jW/j1RS99ZZ4+9yl/CrcrJRP9GjjBS2W1rQCUjolRdLf9PzAZs/AbFvpjxwMbd7vSb5AOeqQ0pTC4BFlvX6IJLGdZmhUYTqNCWj0e40l409o/Hidy0oEXByDaJWmRvRuI6jc5V1v9/FZNze96W/oJC6FLR7MrVgSJA2MmZvzvS3zbCgKU/umgD4ENy+JRBiifHwBWVTkIADHhVq7Ob14eFlawVnEY6tQkdgrwSc2LWBgFQXAYbYmeFLOrEJQKi3e/h4fMLaoeubQ==
localhost: failed
2、解决:进入~/.ssh/known_hosts文件下,找到对应的localhost那一行,使用dd进行删除。
重新启动start-dfs.sh,然后再次输入yes进行认证,会再known_hosts中追加进去一条新的记录。
2.4、三个进程都以hadoop001进行启动
| 节点名称 | 对应文件名称 |
|---|---|
| namenode | core-site.xml |
| datanode | slaves |
| secondarynamenode | hdfs-site.xml |
1、cat /etc/hadoop
1、修改slaves,删除原有的,直接写入hadoop001
2、修改hdfs-site.xml,如下这两段话进行插入:
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop001:50090</value>
</property>
<property>
<name>dfs.namenode.secondary.https-address</name>
<value>hadoop001:50091</value>
</property>
[hadoop@hadoop001 .ssh]$ jps
11488 NameNode
13634 Jps
12308 DataNode
11805 SecondaryNameNode
[hadoop@hadoop001 .ssh]$ netstat -nlp|grep 11805
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 0.0.0.0:50090 0.0.0.0:* LISTEN 11805/java
成果如下:Hadoop的三进程都以机器名hadoop001进行启动如下:
[hadoop@hadoop001 hadoop]$ start-dfs.sh
20/03/24 16:48:14 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [hadoop001]
hadoop001: starting namenode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.16.2/logs/hadoop-hadoop-namenode-hadoop001.out
hadoop001: starting datanode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.16.2/logs/hadoop-hadoop-datanode-hadoop001.out
Starting secondary namenodes [hadoop001]
hadoop001: starting secondarynamenode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.16.2/logs/hadoop-hadoop-secondarynamenode-hadoop001.out
20/03/24 16:48:31 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2.5、总结hadoop的安装过程
1、创建用户及用户目录,su - hadoop进行切换
2、上传压缩包并进行解压,做一个软连接
3、环境要求:java1.8、ssh必须安装
4、java_home的显性配置
5、配置core-site.xml和hdfs-site.xml
6、ssh的无密码信任关系
7、Hadoop配置环境变量
8、格式话namenode
9、start-dfs.sh进行第一次启动,输入yes进行验证
10、datanode、secondarynamenode都要知道在官网的哪边去修改参数
11、namenode是名称节点,老大,读写请求都要先经过它;datanode是数据节点,小弟,存储数据,检索数据;secondarynamenode是第二名称节点,是n+1是时间进行备份。
- 因为单点问题,1个小时的力度所以以后会有高可用HA的配置。
注意:
- 大数据的组件基本都是主从架构,hdfs、hbase(读写请求不经过老大,master进程)
2.6、Hadoop的web页面
- 如何使用hostname访问,在/etc/hosts中配置的是内网ip+hostname,而在windows本地目录:C:\Windows\System32\drivers\etc\hosts,配置的是外网IP+hostname。
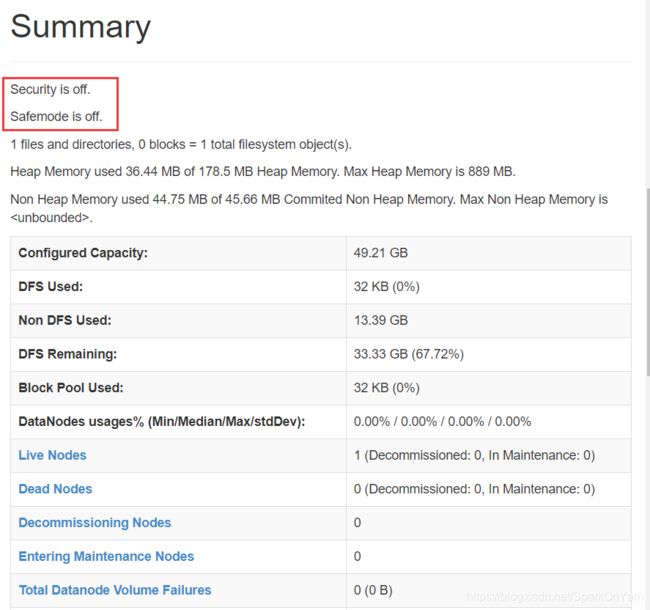
1、safemode is off,安全模式
2、磁盘空间解读:集群总容量49.21G,DFS的使用是12k,不是DFS使用的是13.39G,DFS预留是33.33G;如下图我们还剩34G,这个空间默认是我们dfs的使用空间。
[hadoop@hadoop001 hadoop]$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 50G 14G 34G 29% /
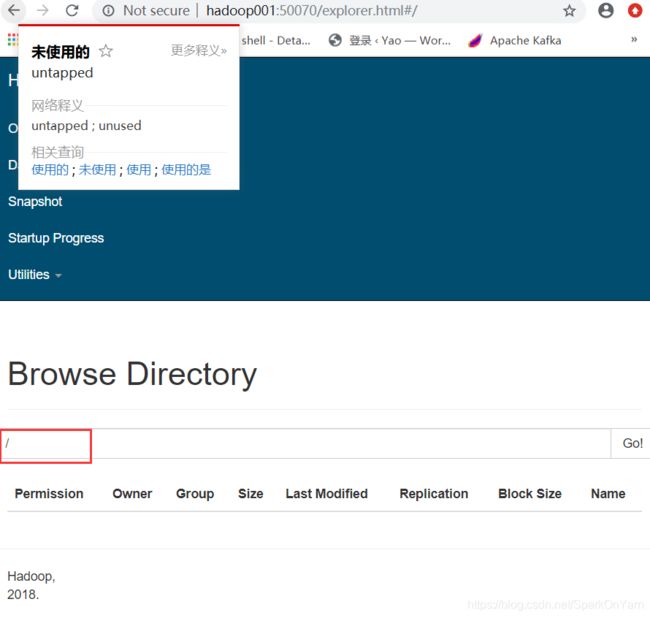
2、文件可视化系统界面:
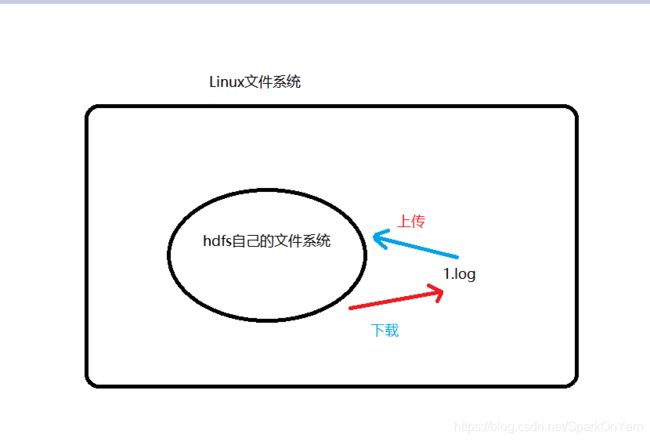
2.7、hdfs上的命令
1、hdfs --help查看命令帮助:
eg:
1、[hadoop@hadoop001 data]$ hdfs dfs -mkdir ruozedata
2、[hadoop@hadoop001 data]$ hdfs dfs -put ruoze.log /ruozedata/
3、下载到本地目录下:
[hadoop@hadoop001 data]$ hdfs dfs -get /ruozedata/ruoze.log ./
20/03/24 17:37:31 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[hadoop@hadoop001 data]$ ll
total 4
-rw-r--r-- 1 hadoop hadoop 10 Mar 24 17:37 ruoze.log
4、删除hdfs上的该文件:
[hadoop@hadoop001 data]$ hdfs dfs -rm -r /ruozedata/ruoze.log
20/03/24 17:38:11 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Deleted /ruozedata/ruoze.log
三、本次课程作业
1、hdfs上的基础命令尽心总结
2、安装hadoop的hdfs伪分布式部署