剑指数据仓库-Shell命令一
一、Linux Shell命令一
- 1.1、环境准备
- 1.2、linux基础命令
- 1.2.1、cd 切换家目录
- 1.2.2、绝对路径&相对路径
- 1.2.3、查看文件、文件大小、文件根据修改时间进行排序、查看命令帮助
- 1.2.4、创建文件夹(级联创建、并行创建)
- 1.2.5、拷贝、移动文件&对文件重命名
- 1.2.6、对文件内容进行置空的三种方式
- 1.2.7、查看文件内容的三种方式 && tail -f 和tail -F的区别
- 1.2.8、定位ERROR的几种方式
二、出现的问题及解决
- 2.1、解决SecureCRT对话框session超时
- 2.2、Linux上的日志如何下载到windows
- 2.3、本次课程作业
Linux Shell命令一
1.1、环境准备
-
建议自行购买一台阿里云、京东云主机,安装Xshell CRT安装包、SecureCRT安装包,再次使用进行连接。
-
SecureCRT如何进行连接云主机:打开SecureCRT,File --> Quick Connect --> 输入hostname;
1.2、Linux基础命令
1.2.1、cd切换家目录
- 切换目录cd
[root@hadoop001 ~]# cd /home
[root@hadoop001 home]# //波浪线就会变成当前光标所在目录
[root@hadoop001 home]# ll
total 4
drwx------ 6 hadoop hadoop 4096 Mar 5 16:32 hadoop
root用户 家目录 /root 规定
XXX用户 家目录 /home/XXX 默认
1、回退到上一次的目录:
当我们的想要回到上一次的目录的时候:cd -
2、快速回退到家目录的三种语法:
cd
cd ~
cd /root
3、回退到上一层目录:
cd ../
4、回退到上两层目录:
cd ../../
1.2.2、绝对路径、相对路径
-
目录 文件夹 路径
绝对路径:/根目录 以根目录为开始 以windows举例:F:\剑指数据仓库\01开班课+Shell命令一
相对路径:不以根目录未开始,以当前光标所在的目录为开始,进入到/home/hadoop目录,这个目录是因为我们执行了useradd hadoop -
相对路径与绝对路径的写法:
1、绝对路径:/usr/local/bin
2、使用相对路径在/usr/local目录下进入bin目录
[root@hadoop001 local]# cd ./bin
[root@hadoop001 bin]# cd -
/usr/local
[root@hadoop001 local]# cd bin
1.2.3、查看文件、文件大小、文件根据修改时间进行排序、查看命令帮助
1、列出目录下的文件夹
[root@hadoop001 local]# ls
aegis include mysql php src
bin lib mysql-5.7.11-linux-glibc2.5-x86_64 php-7.2.28
etc lib64 nginx sbin
games libexec nginx-1.12.2 share
2、列出目录下的文件夹信息,权限+所属用户、用户组、大小(不一定准确)、文件名称
[root@hadoop001 local]# ll
total 56
drwxr-xr-x 6 root root 4096 Mar 9 13:44 aegis
drwxr-xr-x. 2 root root 4096 Nov 5 2016 bin
drwxr-xr-x. 2 root root 4096 Nov 5 2016 etc
3、ls -l -a ⇒ ll -a,列出所有文件夹+隐藏文件(以.开头)
小结:ls -l ⇒ ll
ls -l -a ⇒ ll -a
4、ll -h 查看的是文件的大小(不是文件夹)
[root@hadoop001 nginx]# ll -h
total 760K
drwxr-xr-x 6 root root 4.0K Mar 5 17:15 auto
-rw-r--r-- 1 root root 272K Oct 17 2017 CHANGES
-rw-r--r-- 1 root root 415K Oct 17 2017 CHANGES.ru
drwx------ 2 nobody root 4.0K Mar 5 23:21 client_body_temp
5、ll -rt 按照时间进行排序,就是查看到哪个文件是最新的
6、如何查询命令帮助:
ls --help -a, --all do not ignore entries starting with .
-h, --human-readable with -l, print sizes in human readable format
(e.g., 1K 234M 2G)
//查看文件的大小,不针对文件夹
-r, --reverse reverse order while sorting //排序
-t sort by modification time, newest first //根据时间排序
1.2.4、创建文件夹(级联、平行创建)
- 目录:文件夹组成的,那如何创建文件夹呢?mkdir app software
1、单纯的创建一个文件夹:
[root@hadoop001 ~]# mkdir a
[root@hadoop001 ~]# ll
total 4
drwxr-xr-x 2 root root 4096 Mar 10 11:55 a
2、级联创建文件夹:mkdir -p
[root@hadoop001 ~]# mkdir b/c/d
mkdir: cannot create directory 鈥榖/c/d鈥 No such file or directory
[root@hadoop001 ~]# mkdir -p b/c/d
[root@hadoop001 ~]# ll
total 8
drwxr-xr-x 2 root root 4096 Mar 10 11:55 a
drwxr-xr-x 3 root root 4096 Mar 10 11:56 b
3、创建同级别的并行文件夹:
[root@hadoop001 ~]# mkdir 1 2 3
[root@hadoop001 ~]# ll
total 20
drwxr-xr-x 2 root root 4096 Mar 10 11:58 1
drwxr-xr-x 2 root root 4096 Mar 10 11:58 2
drwxr-xr-x 2 root root 4096 Mar 10 11:58 3
1.2.5、拷贝、移动文件,对文件重命名
- 移动mv和拷贝cp:
1、创建空文件,使用mv进行文件移动:
[hadoop@hadoop001 test]$ touch ruoze.log
[hadoop@hadoop001 test]$ ll
total 0
-rw-rw-r-- 1 hadoop hadoop 0 Mar 10 12:01 ruoze.log
[hadoop@hadoop001 test]$ echo "www.ruozedata.com" >> ruoze.log
[hadoop@hadoop001 test]$ mv ruoze.log ../1
[hadoop@hadoop001 test]$ ll
total 0
[hadoop@hadoop001 test]$ cd ../1
[hadoop@hadoop001 1]$ ll
total 4
-rw-rw-r-- 1 hadoop hadoop 18 Mar 10 12:01 ruoze.log
2、mv移动的同时修改文件名称,
[hadoop@hadoop001 1]$ mv ruoze.log ../test/ruozedata.log
[hadoop@hadoop001 1]$ ll
total 0
[hadoop@hadoop001 1]$ ll ../test/ruozedata.log
-rw-rw-r-- 1 hadoop hadoop 18 Mar 10 12:01 ../test/ruozedata.log
1、拷贝文件,拷贝的时候对文件重命名
[hadoop@hadoop001 test]$ cp ruozedata.log ruozedata.log1
[hadoop@hadoop001 test]$ ll
total 8
-rw-rw-r-- 1 hadoop hadoop 18 Mar 10 12:01 ruozedata.log
-rw-rw-r-- 1 hadoop hadoop 18 Mar 10 12:07 ruozedata.log1
//拷贝到上一层目录下的1文件夹下并且重命名
[hadoop@hadoop001 test]$ cp ruozedata.log ../1/ruozedata.log2
//验证文件夹是否存在
[hadoop@hadoop001 test]$ ll ../1/ruozedata.log2
-rw-rw-r-- 1 hadoop hadoop 18 Mar 10 12:08 ../1/ruozedata.log2
思考题:mv快还是cp快?mv快,mv底层源文件还是没有变得,只是修改了个路径位置;
1.2.6、对文件内容进行置空的三种方式
- 如何创建一个空文件,或者把文件内容置为空
1、注意这两种方式的区别:
[hadoop@hadoop001 test]$ touch rz.log
[hadoop@hadoop001 test]$ echo "" > rz.log1
[hadoop@hadoop001 test]$ ll
total 12
-rw-rw-r-- 1 hadoop hadoop 0 Mar 10 12:11 rz.log
-rw-rw-r-- 1 hadoop hadoop 1 Mar 10 12:11 rz.log1
[hadoop@hadoop001 test]$ cat rz.log
[hadoop@hadoop001 test]$ cat rz.log1
[hadoop@hadoop001 test]$
//观察得到使用echo的方式会在文件中存在一个空位符,这种方式生产上慎用
2、对于内容已经存在的文件如何去置空:
[hadoop@hadoop001 test]$ cat ruozedata.log
www.ruozedata.com
[hadoop@hadoop001 test]$ cat /dev/null > ruozedata.log
[hadoop@hadoop001 test]$ ll
total 8
-rw-rw-r-- 1 hadoop hadoop 0 Mar 10 12:14 ruozedata.log
小结:echo追加的方式使文件置空,文件下永远有一个空字节
1.2.7、查看文件内容的三种方式(tail -f和tail -F)
- 查看文件内容:
cat 文件内容一下子全部显示
more 文件内容一页一页的翻,按空格键往下翻,回退不了,按q键退出
less 文件内容往上和往下都可以,按方向键的上下键.
配置文件:内容较少,使用cat、more、less都可以
log日志:内容较多,如上三个命令都不怎么合适了,此时引出实时查看命令,tail -f
- 引申出面试题:tail -f和tail -F的区别?
1、生产场景:
xxx.log 在代码项目中配置输出的日志,正常会有一个规则,输出的xxx.log,我们保留10份。
aaa ---> xxx.log 99m
xxx.log 100m
系统做了一个动作:mv xxx.log xxx.log1
touch xxx.log
tail -f 和tail -F针对于日志切换的场景就展现出了它的用途,在生产上,flume是大数据平台抽取数据的一个组件,exec source中,提示一定使用tail -F
2、测试tail -f和tail -F:
secureCRT下开3个session,在另外两个session中分别使用tail -f /home/hadoop/test/ruozedata.log,tail -F /home/hadoop/test/ruozedata.log;
//分别输入1和123到ruozedata.log中,对ruozedata.log进行重命名,再次新建一个ruozedata.log的文件,再次输入123到ruozedata.log
[root@hadoop001 test]# echo "1" >> ruozedata.log
[root@hadoop001 test]# echo "123" >> ruozedata.log
[root@hadoop001 test]# mv ruozedata.log ruozedata.log2
[root@hadoop001 test]# touch ruozedata.log
[root@hadoop001 test]# echo 123 >> ruozedata.log
//tail -f下显示的信息如下:
[root@hadoop001 ~]# tail -f /home/hadoop/test/ruozedata.log
1
123
//tail -F显示的信息如下:
[root@hadoop001 test]# tail -F ruozedata.log
1
123
tail: ruozedata.log has become inaccessible: No such file or directory
tail: ruozedata.log has appeared; following end of new file
123
小结:tail -F就是tail -f + retry,对于文件重命名后再新建一个原来的文件名,tail -f是嗅探不到的,而tail -F是能够进行嗅探到的。
1.2.8、对于定位ERROR的几种方式
- 对于ERROR我们如何进行定位:
1、内容少的时候直接使用cat more less查看:
2、重新启动服务的时候使用tail -f 200f,来进行查看
3、文件内容小的时候 几十兆(23十兆、45十兆的时候),下载到windows上,用editplus进行下载打开搜索日志,详见下面的下载目录安装
4、在文件内容几百兆的时候就不合适了,使用这个命令:cat messages|grep error
|:管道符,前面命令的输出结果作为后面命令的输入,此种方式只能cat到error处,并不能获取上下文;
//那如何获取到error的上下文呢?
cat XXX.log | grep -A 10 ERROR //ERROR的后10行
cat XXX.log | grep -B 10 ERROR //ERROR的前10行
cat XXX.log | grep -C 10 ERROR //ERROR的前后各10行,此条命令经常用
在生产上文件内容实时打印的话用f的话没什么问题,对于想要打印一个文件倒数200行且一个文件正在实时打印:tail -300f messages 实时查看倒数300行文件。
但是tail -300F messages是不支持这个语法的。
[root@hadoop001 test]# tail -15F ruozedata.log
tail: option used in invalid context – 1
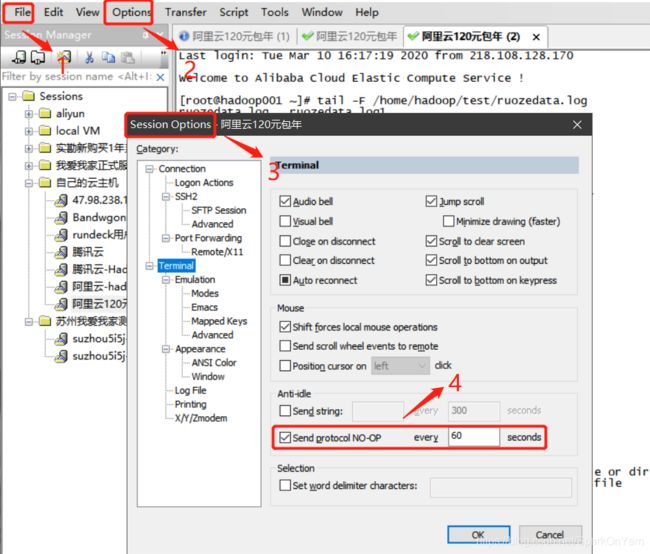
2.1、解决SecureCRT对话框session超时
1、File --> Options --> Session Options,选中Terminal,选中每60秒进行一次通信.
2.2、Linux上的日志如何下载到windows
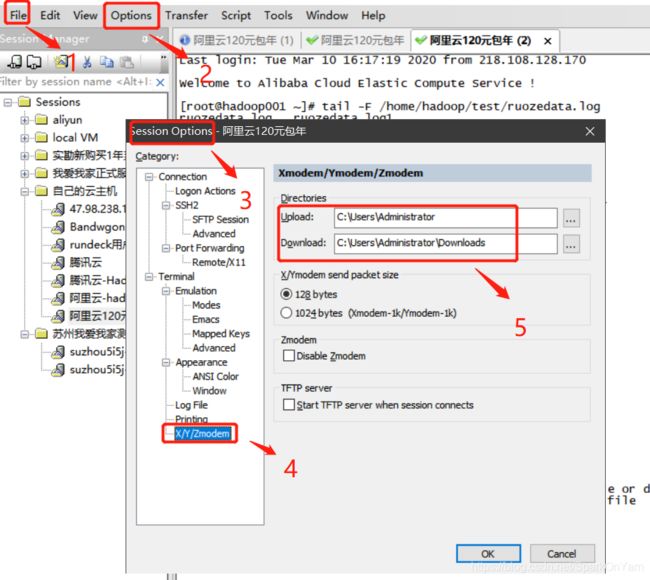
1、在root用户下使用yum install lrzsz进行下载,设置Download下载目录
2.3、本次课程作业
1、环境准备
2、练习课堂内容
3、整理日志如何查看,如何定位error