剑指数据仓库-Hadoop六
一、上次课程回顾
二、Hadoop六
- 2.1、Container剖析
- 2.2、MapReduce2.x的架构设计
- 2.3、解析wordcount.java
- 2.4、Map Task的启动个数由谁来决定?
- 2.4、生产上文件格式、压缩格式的考量?
- 2.5、WordCount流程图解析(Shuffle)
三、作业
一、上次课程回顾
- https://blog.csdn.net/SparkOnYarn/article/details/105126486
二、Hadoop六
2.1、Yarn生产调优之Container剖析
Container:容器的,虚拟化的,维度:memory+vcore,运行task任务
Container容器生产如何调优?
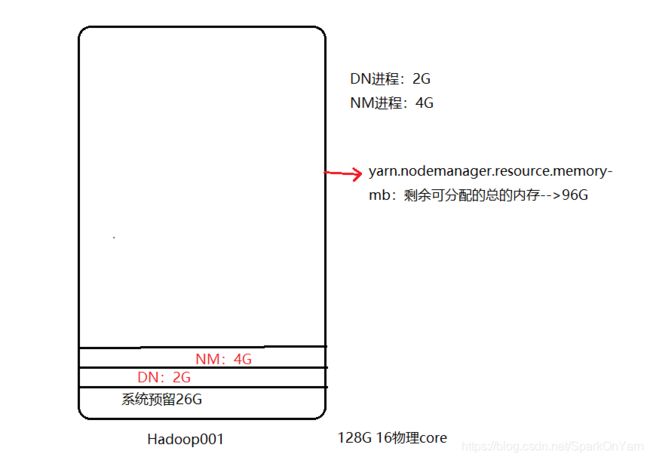
假设机器128G,有16物理core
Example举例:机器装完CentOS机器,会消耗系统内存1G;系统会预留15%-20%内存(以防内存全部使用导致系统夯住,和OOM机制的发生),或者给未来部署组件预留空间
依据上面给出的条件计算预留空间:128G X 20% = 25.6G 约等于 26G
1、假设只有DN、NM节点,余下可使用内存128G - 26G = 102G
DN=2G
NM=4G //此时剩余96G
2、 Container内存:
- yarn.nodemanager.resource.memory-mb 96G(剩余可分配的总的内存是96G)
- yarn.scheduler.minimum-allocation-mb 1G(一个容器设定最小的内存是1G,极限情况下只有96个container,内存1G)
- yarn.scheduler.maximum-allocation-mb 96G(一个容器最大的内存是8G,极限情况下,只有1个container,内存96G)
Container的内存会自动增加,默认以1G递增:
所以此时Conatiner的个数:1-96个递增
3、 Container虚拟核:
在yarn中是没有物理核,只有虚拟核的概念;物理核:虚拟核 = 1:2;此处也就是32vcore.
- 物理核:虚拟核是1:2,它的默认参数:yarn.nodemanager.resource.pcores-vcores-multiplier 2
yarn.nodemanager.resource.pcores-vcores-multiplier 32vcore
yarn.scheduler.minimum-allocation-vcores 1 (极限情况下,只有32个container)
yarn.scheduler.maximum-allocation-vcores 32 (极限情况下,只有1个container)
container:1-32个虚拟核
4、 官方建议:
cloudera公司推荐,一个container的vcore最好不要超过5,所以我们在此处设置为4;换而言之:
yarn.scheduler.minimum-allocation-vcores 4
极限情况下:32vcore / 4 = 8个executor
5、所以最终根据memory+vcore:
确定vcore=4 executor=8个;反推极限情况下每个executor就是设定为12G
总结:
-
对于一台机器128G内存,16个物理core的机器来说:我们能分配的是:
32vcore / 4vcore = 8个container,为了满足内存条件:96G / 8个Container = 每个container是12G,突破点是Cloudera公司推荐使用的4个Vcore -
当Spark计算时,内存不够大,这个参数肯定要调大,那么这种理想化的设置个数必然要打破,以memory为主,说白了目的就是让CPU、Memory去最大程度的利用。
衡量到底应该是从memory考虑还是vcore考虑
- 内存参数:
yarn.nodemanager.resource.memory-mb 96G(控制的是所有的剩余空闲内存)
yarn.scheduler.minimum-allocation-mb 1G
yarn.scheduler.maximum-allocation-mb 8G
以内存为主:Container容器的个数:12-96个;我们拿最大的vcore来进行计算,12 x 2 = 24个vcore,24是远小于32的,不能100%的使用。
- 虚拟core参数
yarn.nodemanager.resource.pcores-vcores-multiplier 32vcore
yarn.scheduler.minimum-allocation-vcores 1
yarn.scheduler.maximum-allocation-vcores 2
以虚拟core为主:Container容器的个数:16-32个;16个container x 8G = 128G,又远大于96G会撑爆
在yarn-default.xml中配置如下:
| name | value | description |
|---|---|---|
| yarn.nodemanager.resource.memory-mb | 96G(用于做计算的总内存) | |
| yarn.scheduler.minimum-allocation-mb | 1024MB | The minimum allocation for every container request at the RM in MBs. Memory requests lower than this will be set to the value of this property. Additionally, a node manager that is configured to have less memory than this value will be shut down by the resource manager. |
| yarn.scheduler.maximum-allocation-mb | 8192MB | The maximum allocation for every container request at the RM in MBs. Memory requests higher than this will throw an InvalidResourceRequestException. |
2.2、如何分配参数
假如256G内存,56个物理core,请问参数如何设置?
-
默认给系统预留20%的空间,是否去除DN、NM占据的内存;算它剩余还有200G内存;按照cloudera推荐的4个vcore来进行计算
-
内存参数:
yarn.nodemanager.resource.memory-mb 200G(控制的是所有的剩余空闲内存)
yarn.scheduler.minimum-allocation-mb 1G
yarn.scheduler.maximum-allocation-mb 8G
container的数量在25 ~ 200,进行弹性计算
- 虚拟core参数:
yarn.nodemanager.resource.pcores-vcores-multiplier 112vcore
yarn.scheduler.minimum-allocation-vcores 1
yarn.scheduler.maximum-allocation-vcores 2
container的数量在56~112,
假如该节点还有组件,比如hbase regionserver进程=30G,那么该如何设置?
vcore的概念:是yarn自己引入的,设计初衷是考虑不同节点的CPU的性能不一样,每个CPU的计算能力不一样;比如某个物理CPU是另外一个物理CPU的两倍,这时通过设置第一个物理CPU的虚拟Core来弥补这种差异。
第一台机器 强悍:物理core:虚拟core = 1:1
第二台机器:不强悍:pcore:vcore = 1:2
在xml中配置即可,直接所有节点设置pcore:vcore = 1:2,现在基本上大家的机配置都差不多。
2.3、yarn中的三种调度器
调度器分为如下三种:
1、FIFO:先进先出
- 举例:在0点启动job1,在1点启动job2,只有等到job1完成后才会再进行job2的计算。
2、Capacity:计算调度器
- 有一个专门的队列来运行小任务,但是为了一个小任务专门设置一个队列预先占用一定的集群资源,这会导致大任务的执行时间落后FIFO的调度时间。
- 就是资源只有100%,还会留出20%给小任务,会导致运行大任务的资源变少相对应的就是时间增长。
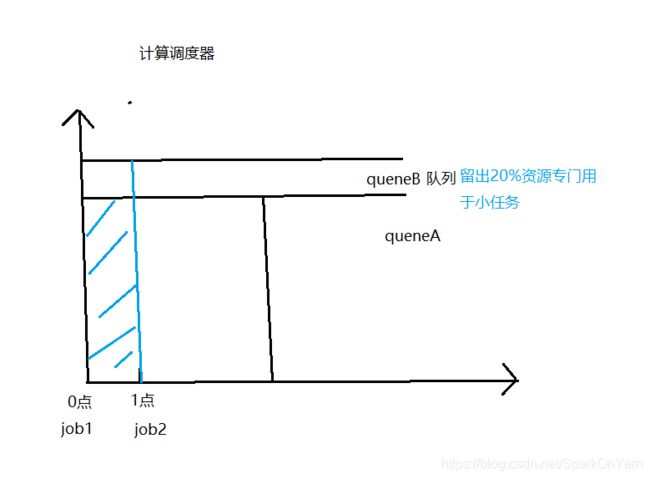
3、Fair:公平
- 还是如上的例子:0点提交大任务job1,1点提交小任务job2;job1是100%使用资源的,等某个container容器中的task完成后释放内存就开始运行job2,job2运行完成之后又会把资源还给job1
apache和cdh中的调度器:
apache默认的就是计算调度器,参数如下:
yarn.resourcemanager.scheduler.class org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
CDH默认的就是公平调度器
为什么CDH选择公平调度器:因为计算调度器不能释放所有资源,总是会有20%的内存被占据着。
动态资源池+放置规则在后期cdh课程中会出现。
2.4、Yarn中的常用命令
1、场景:你登录不了你管理的CDH集群的Web界面,或者程序崩溃了;在web界面上是可以直接进行kill的,但是你登录不了web页面,于是你就在linux终端上进行kill操作。
-
yarn application -kill
-
yarn logs
[hadoop@hadoop001 ~]$ yarn logs -applicationId application_1585204919350_0002
20/03/27 13:11:57 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
20/03/27 13:11:57 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
/tmp/logs/hadoop/logs/application_1585204919350_0002 does not exist.
Log aggregation has not completed or is not enabled.
//需要安装服务
木桶效应:
1、一个木桶存水量,取决于最短的那块板,我们在做计算的时候,数据是参差不齐的文件,就会有类似木桶效应的出现。
blocksize=128m
a1 130m 2个task 运行55s
a2 14m 1个task 运行5s
a3 20m 1个task 运行9s
job要跑4个task,也就是说作业的完成时间从来都不是取决于运行时间短的,取决于运行时间长的;如上的任务运行完成需要55s。
- 对于如上数据肯定是要做规整的,如何在linux下做合并和拆分,数据的理想状况如下:
blocksize还是128m,可以进行如下的拆分:消耗的时间就没有谁最长也没有谁最短
a1 130m --> 55m 1task
a2 14m --> 55m 1task
a3 20m --> 54m 1task
三、本次课程作业&&总结
1、yarn的资源调优参数如何分配 *****
2、调度器整理三种:每种的特性,cdh默认的调度器
总结:
linux命令:cd mkdir rm vi ls chown chmod tar
mysql的建表规范
hdfs架构设计 读写流程 副本放置策略 snn的机制
hadoop fs基础使用命令
MR wordcount流程图
Yarn的核心:生产调优参数详解
提交job yarn的流程图