hadoop完全分布式集群搭建
序:相关软件
一、前期准备
二、jdk,hadoop安装、配置
2.1、jdk、hadoop安装
2.2、配置jdk、hadoop环境变量
三、编写集群分发脚本,完成其他服务器的jdk、hadoop安装与配置
四、集群配置规划
五、完全分布式属性配置
5.1、core-site.xml
5.2、hdfs-site.xml
5.3、yarn-site.xml
5.4、mapred-site.xml
5.5、workers
5.6、集群配置同步
六、ssh无密登录配置
七、集群启动和停止脚本编写及测试
7.1、官方启动脚本
7.2、自定义启动脚本
7.3、自定义进程查询脚本
7.4、测试。
八、web端访问
8.1、hdfs信息查询:hadoop102:9780
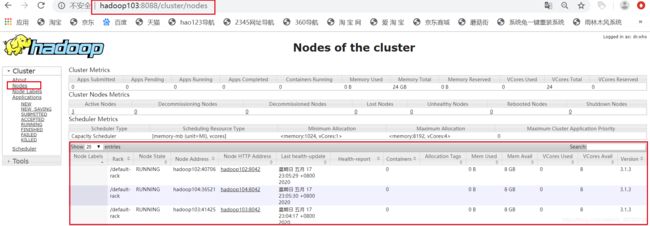
8.2、yarn信息查询:hadoop103:8088
8.3、历史服务器查询:hadoop102:19888
序:相关软件
- VMware:VMware-15.5.1
- Linux:CentOS-7.5-x86_64-DVD-1804.iso
- JDK:jdk-8u212-linux-x64.tar.gz
- Hadoop:hadoop-3.1.3.tar.gz
- xshell
- xftp
一、前期准备
- 准备三台服务器
- 服务器静态ip创建
- 服务器关闭防火墙
- 服务器创建新用户user,给user root权限
- 在/opt/目录下创建两个目录:module,software,并将module、software目录转给user
- 配置好xshell远程访问
二、jdk,hadoop安装、配置
操作思想:以hadoop102为主操作服务器,完成软件安装及配置再分发到集群其他服务器
2.1、jdk、hadoop安装
文件从本地传输到服务器:使用软件xshell,xftp。软件存放位置:/opt/software/。完成后在服务器上查看。

[atguigu@hadoop102 software]$ pwd
/opt/software
[atguigu@hadoop102 software]$ ll
总用量 520608
-rw-rw-r--. 1 user user 338075860 5月 15 21:45 hadoop-3.1.3.tar.gz
-rw-rw-r--. 1 user user 195013152 5月 15 21:45 jdk-8u212-linux-x64.tar.gzjdk、hadoop软件解压(解压后就可使用,无需安装),解压位置:/opt/module/。完成后服务器查看。
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/[user@hadoop102 module]$ pwd
/opt/module
[user@hadoop102 module]$ ll
总用量 8
drwxr-xr-x. 11 user user 4096 5月 15 23:52 hadoop-3.1.3
drwxr-xr-x. 7 user user 4096 4月 2 2019 jdk1.8.0_2122.2、配置jdk、hadoop环境变量
在/etc/profile.d/目录下,创建环境变量配置文件,文件名为:my_env.sh,文件内容如下:
#JAVA_HOME
JAVA_HOME=/opt/module/jdk1.8.0_212
#HADOOP_HOME
HADOOP_HOME=/opt/module/hadoop-3.1.3
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export PATH JAVA_HOME HADOOP_HOME配置/opt/module/hadoop 3.1.3/etc/hadoop/hadoop-env.sh
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
# export JAVA_HOME=
# 增加以下内容
export JAVA_HOME=/opt/module/jdk1.8.0_212三、编写集群分发脚本,完成其他服务器的jdk、hadoop安装与配置
shell脚本编写,脚本存放位置为:/home/user/bin/。此路径在系统path中,故可以在任意位置执行脚本。脚本名xsync,脚本完成后,需给当前用户增加操作权限。
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
jdk、hadoop及属性文件集群同步
xsync /opt/module/*
xsync /etc/profile.d/my_env.sh在集群其他服务器上重新加载下系统配置,将jdk、hadoop环境变量加载,并测试是否成功。
source /etc/profile
[user@hadoop103 module]$ java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mod
[user@hadoop102 module]$ hadoop version
Hadoop 3.1.3
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579
Compiled by ztang on 2019-09-12T02:47Z
Compiled with protoc 2.5.0
From source with checksum ec785077c385118ac91aadde5ec9799
This command was run using /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar
至此,hadoop103、hadoop104的jdk、hadoop安装与环境变量配置完成。
四、集群配置规划
由于只有三台服务器,在完全分布式运行环境中,namenode,resoucemanager,secondarynamenode的资源占比较大,故在配置时,将三者分别布置在不同的服务器上。datanode和nodemanager在三个服务器上都进行配置。具体如下:
| hadoop102 | namenode | datanode | nodemanager |
| hadoop103 | resourcemanager | datanode | nodemanager |
| hadoop104 | secondarynamenode | datanode | nodemanager |
需配置文件位置:/opt/module/hadoop3.1.3/etc/hadoop/。需要配置的文件如下:
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
五、完全分布式属性配置
5.1、core-site.xml
fs.defaultFS
hdfs://hadoop102:9820
hadoop.data.dir
/opt/module/hadoop-3.1.3/data
5.2、hdfs-site.xml
dfs.namenode.name.dir
file://${hadoop.data.dir}/name
dfs.datanode.data.dir
file://${hadoop.data.dir}/data
dfs.namenode.checkpoint.dir
file://${hadoop.data.dir}/namesecondary
dfs.replication
3
dfs.client.datanode-restart.timeout
30s
dfs.namenode.http-address
hadoop102:9870
dfs.namenode.secondary.http-address
hadoop104:9868
5.3、yarn-site.xml
yarn.nodemanager.vmem-check-enabled
false
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop103
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,
CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
yarn.log-aggregation-enable
true
yarn.log.server.url
http://hadoop102:19888/jobhistory/logs
yarn.log-aggregation.retain-seconds
604800
5.4、mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
hadoop102:10020
mapreduce.jobhistory.webapp.address
hadoop102:19888
5.5、 workers
vim /opt/module/hadoop-3.1.3/etc/hadoop/workers删除原内容,并在该文件中增加如下内容。注意:文件中添加的内容结尾不允许有空格,文件中不允许有空行。
hadoop102
hadoop103
hadoop1045.6、集群配置同步
按照以上配置进行,具体每条配置的作用已经注释,如有其它的配置要求,可再添加。所有配置完成后进行集群属性同步。使用先前编写的集群同步脚本xsync。
xsync /opt/module/hadoop-3.1.3/etc/hadoop/*六、ssh无密登录配置
小伙伴在进行集群数据同步时,是否存在每往一台服务器上传输数据,从需要进行确认及密码登录,是否特别不变,想想若是上千节点,不光记不住,更是输到手抽筋。下边就给大家演示下如何实现无密登录。
无密登录的原理是在一个服务器上创建一对秘钥,分别为公钥,私钥。私钥放在自己的服务器,公钥放到你想免密登录的服务器。如此,当你想要登录该服务器时,会进行公钥和私钥的配对,配对成功即可免密登录。具体实现方式为,输入以下命令,回车4次即可。其他服务器也需要进行相同操作。
ssh-keygen -t rsaGenerating public/private rsa key pair.
Enter file in which to save the key (/home/atguigu/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/atguigu/.ssh/id_rsa.
Your public key has been saved in /home/atguigu/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:rksrZWaYPgfTY6s509NKQGRwZrGDeMCYmrWjQ19L+gQ atguigu@hadoop101
The key's randomart image is:
+---[RSA 2048]----+
|+...B. |
|o+.B . |
|ooo.+ |
|oooE + |
|....*+. S |
|o o=+O. |
| . .oXo+. |
| *==o. |
| oB=+ |
+----[SHA256]-----+
集群公钥的传输到免密登录的服务器上,传输完成后可在各服务器上查看秘钥情况。秘钥位置:~/.ssh(隐藏文件,需ls -a)
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104
[user@hadoop102 ~]$ cd .ssh
[user@hadoop102 .ssh]$ ll
总用量 16
-rw-------. 1 user user 1197 5月 16 10:10 authorized_keys
-rw-------. 1 user user 1679 5月 16 10:06 id_rsa
-rw-r--r--. 1 user user 399 5月 16 10:06 id_rsa.pub
-rw-r--r--. 1 user user 561 5月 15 22:23 known_hosts文件解释
| known_hosts |
记录ssh访问过计算机的公钥(public key) |
| id_rsa |
生成的私钥 |
| id_rsa.pub |
生成的公钥 |
| authorized_keys |
存放授权过的无密登录服务器公钥 |
完成以上配置,再进行集群文件同步时,就可以实现无密登录。
七、集群启动和停止脚本编写及测试
7.1、官方启动脚本
在hadoop的官方文件中内置了集群启动的脚本,脚本位置为:/opt/module/hadoop 3.1.3/sbin/。
| start-all.sh | 启动集群所有模块 |
| stop-all.sh | 关闭集群所有模块 |
| start-dfs.sh | 启动dnfs存储模块 |
| stop-dfs.sh | 关闭dnfs存储模块 |
| start-yarn.sh | 启动集群资源管理及配置模块 |
| stop-yarn.sh | 关闭集群资源管理及配置模块 |
-rwxr-xr-x. 1 user user 2221 9月 12 2019 start-all.sh
-rwxr-xr-x. 1 user user 5170 9月 12 2019 start-dfs.sh
-rwxr-xr-x. 1 user user 3342 9月 12 2019 start-yarn.sh
-rwxr-xr-x. 1 user user 2166 9月 12 2019 stop-all.sh
-rwxr-xr-x. 1 user user 3898 9月 12 2019 stop-dfs.sh
-rwxr-xr-x. 1 user user 3083 9月 12 2019 stop-yarn.sh7.2、自定义启动脚本
当然,大家可以选择自带脚本进行启停,也可以自己编写脚本,有脚本的话会更加灵活,选择自己需要的模块开启。不论采取哪种方式,要注意的是start-dfs.sh \stop-dfs.sh只能在布置namenode的服务器上启停;start-yarn.sh\stop-yarn.sh只能在布置resourcemanager的服务器上启停。以下是一个实现启停dnfs、yarn、历史服务器和日志的脚本。脚本名mycluster,位置:/home/user/bin/。
#!/bin/bash
if [ $# -lt 1 ]
then
echo "NO PARAMETER INPUT"
fi
case $1 in
"start")
echo "-----------------------start hdfs--------------------------"
ssh hadoop102 /opt/module/hadoop-3.1.3/sbin/start-dfs.sh
echo "-----------------------start yarn--------------------------"
ssh hadoop103 /opt/module/hadoop-3.1.3/sbin/start-yarn.sh
echo "------------------start historyserver----------------------"
ssh hadoop102 /opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver
;;
"stop")
echo "-----------------------stop yarn---------------------------"
ssh hadoop103 /opt/module/hadoop-3.1.3/sbin/stop-yarn.sh
echo "------------------stop historyserver-----------------------"
ssh hadoop102 /opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver
echo "-----------------------stop hdfs---------------------------"
ssh hadoop102 /opt/module/hadoop-3.1.3/sbin/stop-dfs.sh
;;
*)
echo "input parameter error"
;;
esac7.3、自定义进程查询脚本
为了方便在启动后快速查询进程,需要编写一个进程查询脚本,脚本名:myjps。位置:/home/user/bin。给当前用户增加执行权限。脚本内容如下:
#!/bin/bash
for i in hadoop102 hadoop103 hadoop104
do
echo "--------------------$i jps----------------------"
ssh $i /opt/module/jdk1.8.0_212/bin/jps
done7.4、测试。
输入mycluster+ 参数(start、stop)
mycluster start
-----------------------start hdfs--------------------------
Starting namenodes on [hadoop102]
Starting datanodes
Starting secondary namenodes [hadoop104]
-----------------------start yarn--------------------------
Starting resourcemanager
Starting nodemanagers
------------------start historyserver----------------------
输入myjps 查询进程,与第四节的集群配置比较,确认是否启动成功。
myjps
--------------------hadoop102 jps----------------------
4737 NameNode
5347 JobHistoryServer
4901 DataNode
5480 Jps
5212 NodeManager
--------------------hadoop103 jps----------------------
13249 NodeManager
12914 DataNode
13652 Jps
13110 ResourceManager
--------------------hadoop104 jps----------------------
7617 SecondaryNameNode
7527 DataNode
7916 Jps
7741 NodeManager
关闭集群。命令:mycluster stop
mycluster stop
-----------------------stop yarn---------------------------
Stopping nodemanagers
Stopping resourcemanager
------------------stop historyserver-----------------------
-----------------------stop hdfs---------------------------
Stopping namenodes on [hadoop102]
Stopping datanodes
Stopping secondary namenodes [hadoop104]八、web端访问
8.1、hdfs信息查询:hadoop102:9780

8.2、yarn信息查询:hadoop103:8088
8.3、历史服务器查询:hadoop102:19888

