阿里开源事件告警组件kube-eventer
阿里开源事件告警组件kube-eventer
- 阿里开源事件告警组件kube-eventer
-
- 背景
- 事件监控
- 阿里kube-eventer
- 项目地址
- 支持下列通知程序
- 钉钉通知实践
- 参考
阿里开源事件告警组件kube-eventer
[ ] 事件告警产生的背景
[ ] 阿里kube-event介绍、支持的通知程序
[ ] k8s1.15.7集群对接钉钉机器人实践
背景
监控是保障系统稳定性的重要组成部分,在Kubernetes开源生态中,资源类的监控工具与组件监控百花齐放。
cAdvisor:kubelet内置的cAdvisor,监控容器资源,如容器cpu、内存;
Kube-state-metrics:kube-state-metrics通过监听 API Server 生成有关资源对象的状态指标,主要关注元数据,比如 Deployment、Pod、副本状态等;
metrics-server:metrics-server 也是一个集群范围内的资源数据聚合工具,是 Heapster 的替代品,k8s的HPA组件就会从metrics-server中获取数据;
还有node-exporter、各个官方、非官方的exporter,使用 Prometheus 来抓取这些数据然后存储,告警,可视化。但这些还远远不够。
监控的实时性与准确性不足 大部分资源监控都是基于推或者拉的模式进行数据离线,因此通常数据是每隔一段时间采集一次,如果在时间间隔内出现一些毛刺或者异常,而在下一个采集点到达时恢复,大部分的采集系统会吞掉这个异常。而针对毛刺的场景,阶段的采集会自动削峰,从而造成准确性的降低。
监控的场景覆盖范围不足 部分监控场景是无法通过资源表述的,比如Pod的启动停止,是无法简单的用资源的利用率来计量的,因为当资源为0的时候,我们是不能区分这个状态产生的真实原因。
基于上述两个问题,Kubernetes是怎么解决的呢?
事件监控
在Kubernetes中,事件分为两种,一种是Warning事件,表示产生这个事件的状态转换是在非预期的状态之间产生的;另外一种是Normal事件,表示期望到达的状态,和目前达到的状态是一致的。我们用一个Pod的生命周期进行举例,当创建一个Pod的时候,首先Pod会进入Pending的状态,等待镜像的拉取,当镜像录取完毕并通过健康检查的时候,Pod的状态就变为Running。此时会生成Normal的事件。而如果在运行中,由于OOM或者其他原因造成Pod宕掉,进入Failed的状态,而这种状态是非预期的,那么此时会在Kubernetes中产生Warning的事件。那么针对这种场景而言,如果我们能够通过监控事件的产生就可以非常及时的查看到一些容易被资源监控忽略的问题。
一个标准的Kubernetes事件有如下几个重要的属性,通过这些属性可以更好地诊断和告警问题。
Namespace:产生事件的对象所在的命名空间。 Kind:绑定事件的对象的类型,例如:Node、Pod、Namespace、Componenet等等。 Timestamp:事件产生的时间等等。 Reason:产生这个事件的原因。 Message: 事件的具体描述。
[root@k8s-test-m1 ~]# kubectl get event --all-namespaces
NAMESPACE LAST SEEN TYPE REASON OBJECT MESSAGE
default 13m Normal Scheduled pod/web-nginx-69899cb7c7-sbfmz Successfully assigned default/web-nginx-69899cb7c7-
sbfmz to 1001tmall-test-w2default 13m Normal Pulling pod/web-nginx-69899cb7c7-sbfmz Pulling image "nginx:1.10"
default 94s Normal Pulled pod/web-nginx-69899cb7c7-sbfmz Successfully pulled image "nginx:1.10"
default 94s Warning Failed pod/web-nginx-69899cb7c7-sbfmz Error: cannot find volume "default-token-v49v8" to
mount into container "nginx"default 13m Normal SuccessfulCreate replicaset/web-nginx-69899cb7c7 Created pod: web-nginx-69899cb7c7-sbfmz
default 13m Normal ScalingReplicaSet deployment/web-nginx Scaled up replica set web-nginx-69899cb7c7 to 1
阿里kube-eventer
针对Kubernetes的事件监控场景,Kuernetes社区在Heapter中提供了简单的事件离线能力,后来随着Heapster的废弃,相关的能力也一起被归档了。为了弥补事件监控场景的缺失,阿里云容器服务发布并开源了kubernetes事件离线工具kube-eventer。支持离线kubernetes事件到钉钉机器人、SLS日志服务、Kafka开源消息队列、InfluxDB时序数据库等等。
项目地址
阿里云容器服务kube-eventer
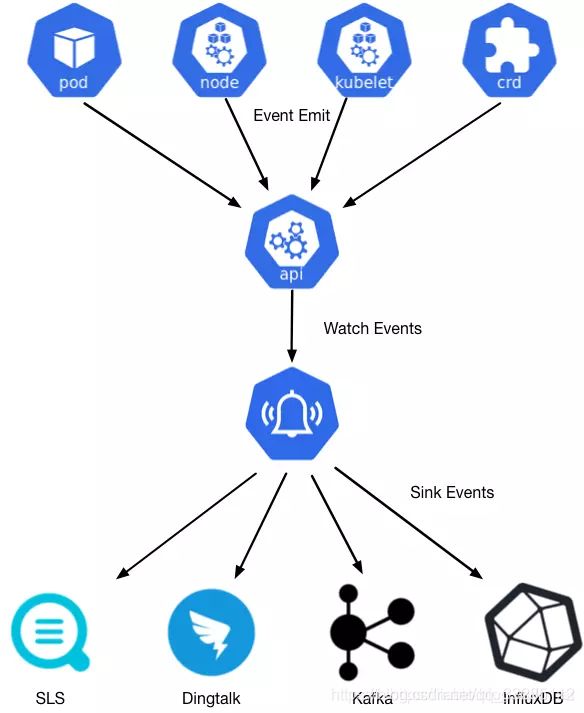
支持下列通知程序
| 程序名称 | 描述 |
|---|---|
| dingtalk | 钉钉机器人 |
| sls | 阿里云sls服务 |
| elasticsearch | elasticsearch 服务 |
| honeycomb | honeycomb 服务 |
| influxdb | influxdb数据库 |
| kafka | kafka数据库 |
| mysql | mysql数据库 |
| 微信 |
钉钉通知实践
接下来实践一下kube-events对接钉钉告警。
1、首先有一个群,自己要又管理权限,点击智能群助手
2、添加机器人

3、添加自定义(通过Webhook接入自定义服务)
4、填写机器人名称、安全设置等。
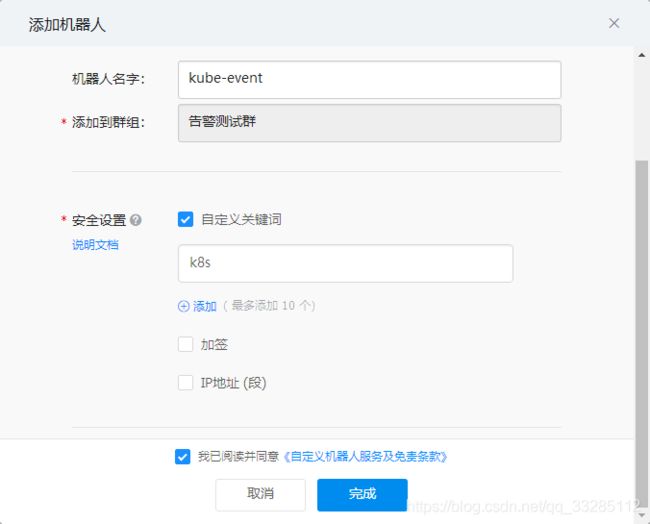
(1)自定义关键词,最多可以设置10个关键词,消息中至少包含其中1个关键词才可以发送成功。添加了一个自定义关键词:cluster1,则这个机器人所发送的消息,必须包含监控报警这个词,才能发送成功。 (2)加签,把timestamp+"\n"+密钥当做签名字符串,使用HmacSHA256算法计算签名,然后进行Base64 encode,最后再把签名参数再进行urlEncode,得到最终的签名(需要使用UTF-8字符集)。 (3)IP地址(段),设定后,只有来自IP地址范围内的请求才会被正常处理。支持两种设置方式:IP、IP段,暂不支持IPv6地址白名单
上面我用到的是自定义关键字的方式。关键字设置为cluster1,下面在创建yaml文件时需要修改
更多详细实例可以参考钉钉API对接文档
5、复制webhook url地址。
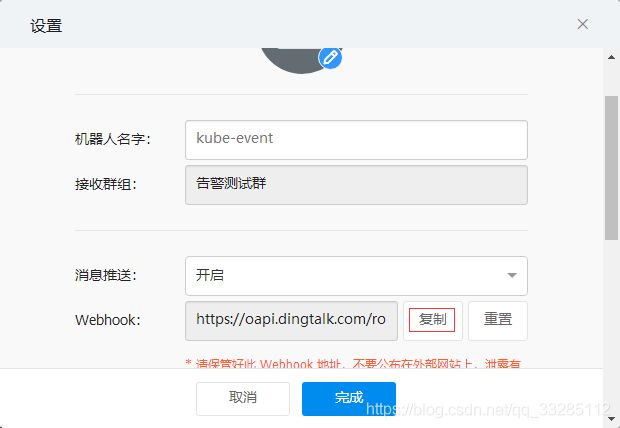
6、将以下yaml文件保存到kube-event.yaml文件中,修改启动参数中的–sink为自己刚才复制的webhook地址,label中写刚才自定义的关键字cluster1,level指定告警为Warning级别的事件。
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
name: kube-eventer
name: kube-eventer
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app: kube-eventer
template:
metadata:
labels:
app: kube-eventer
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
dnsPolicy: ClusterFirstWithHostNet
serviceAccount: kube-eventer
containers:
- image: registry.aliyuncs.com/acs/kube-eventer-amd64:v1.1.0-63e7f98-aliyun
name: kube-eventer
command:
- "/kube-eventer"
- "--source=kubernetes:https://kubernetes.default"
## .e.g,dingtalk sink demo
- --sink=dingtalk:https://oapi.dingtalk.com/robot/send?access_token=****************************************&label=k8s-test1001tmall&level=Warning env:
# If TZ is assigned, set the TZ value as the time zone
- name: TZ
value: Asia/Shanghai
volumeMounts:
- name: localtime
mountPath: /etc/localtime
readOnly: true
- name: zoneinfo
mountPath: /usr/share/zoneinfo
readOnly: true
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 500m
memory: 250Mi
volumes:
- name: localtime
hostPath:
path: /etc/localtime
- name: zoneinfo
hostPath:
path: /usr/share/zoneinfo
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kube-eventer
rules:
- apiGroups:
- ""
resources:
- events
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
annotations:
name: kube-eventer
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-eventer
subjects:
- kind: ServiceAccount
name: kube-eventer
namespace: kube-system
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-eventer
namespace: kube-system
7、执行kube-event.yaml
[root@k8s-test-m1 ~]# kubectl apply -f kube-event.yaml
deployment.apps/kube-eventer configured
clusterrole.rbac.authorization.k8s.io/kube-eventer unchanged
clusterrolebinding.rbac.authorization.k8s.io/kube-eventer unchanged
serviceaccount/kube-eventer unchanged
8、钉钉接收到报警通知
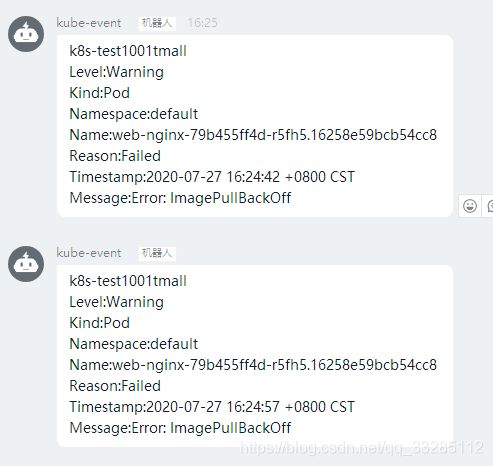
生 Pod因为 OOM 、拉取不到镜像、健康检查不通过等错误导致重启,集群管理员其实是不知道的,因为 Kubernetes 有自我修复机制,Pod宕掉,可以重新启动一个。有了事件告警,集群管理员就可以及时发现服务问题,进行修复。
参考
对接钉钉机器人说明 Kubernetes事件离线工具kube-eventer正式开源