无人驾驶实战(二)——TensorFlow实现基于 LeNet5 网络的交通标志识别
引言:交通标志是道路基础设施的重要组成部分,它们为驾驶员及行人提供了道路行驶关键信息,并要求驾
驶员及时调整驾驶行为,以确保遵守道路安全规定。无人驾驶车辆同样必须遵守交通法规,因此它需要识
别和理解交通标志。一般来说,我们可以使用计算机视觉的方法来对交通标志进行检测和分类,但这需要
耗费相当多的时间来处理图像中的重要特征。而现在,我们可以引入深度学习技术来解决这个问题,我们
可以创建一个能够对交通标志进行分类的模型,并让模型自己学习识别这些交通标志中的最关键的特征。
内容:本博客内容来自Udacity无人驾驶纳米学位项目——交通标志的识别,旨在为无人驾驶车辆行驶中需要
识别和理解交通标志提供一种使用TensorFlow实现的基于 LeNet5 网络的交通标志识别深度学习模型。
实现过程:
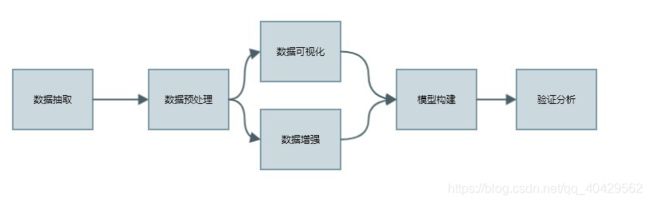
注意事项:
(1)本项目实现主要采用 CNN 卷积神经网络,具体的网络结构参考 Lecun 提出的 LeNet 结构。
(2)使用环境:win10 + python shell,图片显示有问题,请只关注图片灰暗程度和分辨率。
准备工作:
1、下载 “德国交通标志数据集——GTSRB交通信号数据集(包含43种交通信号)”

博客提供数据集下载,使用百度云盘即可获取资源,解压后得到数据集(测试集、训练集、验证集)。
链接:https://pan.baidu.com/s/1l5IHduQcJYU8eLFiht8JAw
提取码:1cb9
附加:交通标志与类别数对应 excel 文件。
链接:https://pan.baidu.com/s/1kOf8a5i5MA0QR_coXaXvzQ
提取码:8s11
(一)、导入需要用到的包
# importing some useful packages
import cv2
import csv
import os
import pickle
import random
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import tensorflow as tf
from tensorflow.contrib.layers import flatten
from sklearn.utils import shuffle
import skimage.morphology as morp
from skimage.filters import rank
from skimage import transform as transf
(二)、加载数据集、输出数据集信息
# Step 0: Load The Data
training_file = '../data/train.p'
validation_file='../data/valid.p'
testing_file = '../data/test.p'
with open(training_file, mode='rb') as f:
train = pickle.load(f)
with open(validation_file, mode='rb') as f:
valid = pickle.load(f)
with open(testing_file, mode='rb') as f:
test = pickle.load(f)
X_train, y_train = train['features'], train['labels']
X_valid, y_valid = valid['features'], valid['labels']
X_test, y_test = test['features'], test['labels']
# Step 1: Dataset information
n_train = len(X_train)
n_validation = len(X_valid)
n_test = len(X_test)
_,IMG_HEIGHT,IMG_WIDTH,IMG_DEPTH = X_train.shape
image_shape = (IMG_HEIGHT,IMG_WIDTH,IMG_DEPTH)
n_classes = len(np.unique(y_train))
with open('../data/signnames.csv','r') as sign_name:
reader = csv.reader(sign_name)
sign_names = list(reader)
sign_names = sign_names[1:] # The first one is:"['ClassId', 'SignName']", not counting
NUM_CLASSES = len(sign_names)
n_classes = len(np.unique(y_train))
assert (NUM_CLASSES == n_classes) ,'1 or more class(es) not represented in training set'
print("Number of training examples =", n_train)
print("Number of validation examples =", n_validation)
print("Number of testing examples =", n_test)
print("Image data shape =", image_shape)
print("Number of classes =", n_classes)
signs_ids = pd.read_csv('../data/signnames.csv')
signs_ids.head(10)
print(signs_ids.head(10))
结果展示:
(1)数据集大小、图片大小、图片类别数

分析:数据集信息:
数据集分为训练集、测试集和验证集,具有以下特点:
- 图像为32(宽)×32(高)×3(RGB彩色通道)
- 训练集由34799张图片组成
- 验证集由4410个图像组成
- 测试集由12630个图像组成
- 共有43个种类
(2)部分 excel 文件信息
(三)、图像处理
# Step 2: picture process
# plotting 20 traffic sign images
def plt_img(X, y):
fig, axs = plt.subplots(4,5, figsize = (16, 11))
fig.subplots_adjust(hspace = .5, wspace = 0.001)
axs = axs.ravel()
for i in range(20):
index = random.randint(0, len(X))
image = X[index]
axs[i].axis('off')
axs[i].set_title(y[index])
axs[i].imshow(image)
plt.show()
plt_img(X_train, y_train)
# Pre-process the Data Set (normalization, grayscale, etc.)
X_train, y_train = shuffle(X_train, y_train)
#convert to grayscale
def convert_to_gray(image):
return cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
gray_images = list(map(convert_to_gray, X_train))
plt_img(gray_images, y_train)
# local histogram equalization
def local_equal(image):
kernel = morp.disk(30)
img_local = rank.equalize(image, selem=kernel)
return img_local
equal_images = list(map(local_equal, gray_images))
plt_img(equal_images, y_train)
#image normalization to [0, 1] scale
def normalize(image):
image = np.divide(image, 255)
return image
# images after normalization
X_train_p = np.zeros((X_train.shape[0], X_train.shape[1], X_train.shape[2]))
for i, img in enumerate(equal_images):
X_train_p[i] = normalize(img)
plt_img(X_train_p , y_train)
X_train_p = X_train_p[..., None]
# preprocessing pipeline
def preprocess(data):
gray_images = list(map(convert_to_gray, data))
equal_images = list(map(local_equal, gray_images))
normal_images = np.zeros((data.shape[0], data.shape[1], data.shape[2]))
for i, img in enumerate(equal_images):
normal_images[i] = normalize(img)
normal_images = normal_images[..., None]
return normal_images
X_valid_p = X_valid.copy()
X_test_p = X_test.copy()
X_valid_p = preprocess(X_valid_p)
X_test_p = preprocess(X_test_p)
结果展示:
(1)训练集中的任意20张图片信息

(2)训练集灰度化后任意20张图片信息

(3)训练集局部直方图后任意20张图片信息
(4)训练集中归一化后任意20张图片信息

(四)、可视化数据集信息
# frequency of labels in train dataset
train_labels, n_train_labels = np.unique(y_train, return_counts=True)
plt.bar(train_labels, n_train_labels, align = 'center')
plt.xlabel('class')
plt.ylabel('Frequency')
plt.xlim([-1, 43])
plt.title("frequency of labels in train dataset")
plt.show()
# frequency of labels in validation dataset
valid_labels, n_valid_labels = np.unique(y_valid, return_counts = True)
plt.bar(valid_labels, n_valid_labels, align = 'center')
plt.xlabel('class')
plt.ylabel('Frequency')
plt.xlim([-1, 43])
plt.title("frequency of labels in validation dataset")
plt.show()
# frequency of labels in test dataset
test_labels, n_test_labels = np.unique(y_test, return_counts = True)
plt.bar(test_labels, n_test_labels, align = 'center')
plt.xlabel('class')
plt.ylabel('Frequency')
plt.xlim([-1, 43])
plt.title("frequency of labels in test dataset")
plt.show()
# Get the number of each class
def get_count_imgs_per_class(y):
num_classes = len(np.unique(y))
count_imgs_per_class = np.zeros( num_classes )
for this_class in range( num_classes ):
count_imgs_per_class[this_class] = np.sum(y == this_class )
return count_imgs_per_class
class_freq = get_count_imgs_per_class(y_train)
print('Highest count: {} (class {})'.format(np.max(class_freq), np.argmax(class_freq)))
print('Lowest count: {} (class {})'.format(np.min(class_freq), np.argmin(class_freq)))
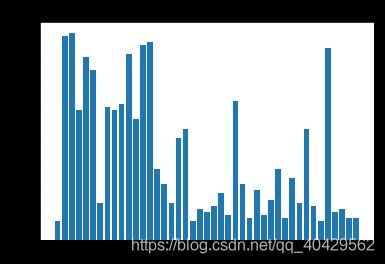
结果展示:
(1)数据集中交通标志类别数分布情况
训练集:
验证集:

测试集:

(2)训练集中分类最多与最少种类的数量:
![]()
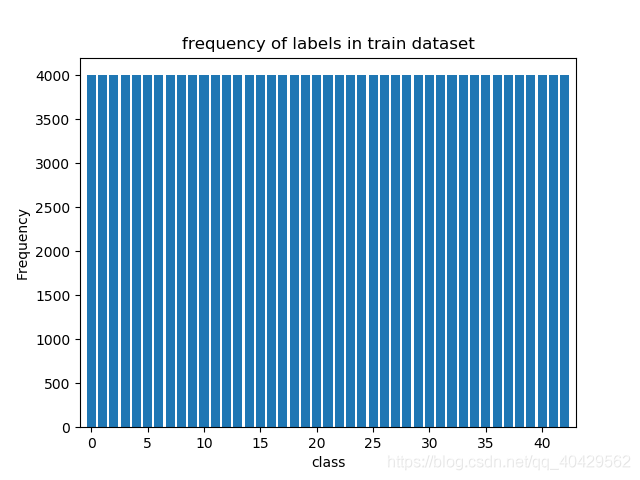
分析:通过分析上述直方图,我们发现训练集中各个种类图像的数量明显不平衡:某些种类的图片少于200张,而某些却超过2000张。这意味着我们的模型可能会偏向于代表性过高的种类,特别是当它的预测无法确定时,所以我们需要使用数据增强来缓解这个问题。
(五)、数据集增强
# step 3: dataset augmentation
def random_transform(img, angle_range=[-15,15], scale_range=[0.8,1.2], translation_range=[-2,2]):
img_height, img_width, img_depth = img.shape
# Generate random parameter values
angle_value = np.random.uniform(low = angle_range[0], high = angle_range[1], size = None)
scaleX = np.random.uniform(low = scale_range[0], high = scale_range[1], size = None)
scaleY = np.random.uniform(low = scale_range[0], high = scale_range[1], size = None)
translationX = np.random.randint(low = translation_range[0], high = translation_range[1], size = None)
translationY = np.random.randint(low = translation_range[0], high = translation_range[1], size = None)
center_shift = np.array([img_height, img_width])/2. - 0.5
transform_center = transf.SimilarityTransform(translation = -center_shift)
transform_uncenter = transf.SimilarityTransform(translation = center_shift)
transform_aug = transf.AffineTransform(rotation = np.deg2rad(angle_value),scale = (1/scaleY, 1/scaleX),translation = (translationY, translationX))
# Image transformation : includes rotation, shear, translation, zoom
full_tranform = transform_center + transform_aug + transform_uncenter
new_img = transf.warp(img, full_tranform, preserve_range = True)
return new_img.astype('uint8')
def data_augmentation(X_dataset, y_dataset, augm_nbr, keep_dist = True):
X_train_dtype = X_train_p
n_classes = len(np.unique(y_dataset))
_, img_height, img_width, img_depth = X_dataset.shape
class_freq = get_count_imgs_per_class(y_train)
if keep_dist:
extra_imgs_per_class = np.array([augm_nbr * x for x in get_count_imgs_per_class(y_dataset)])
else:
assert (augm_nbr > np.argmax(class_freq)),'augm_nbr must be larger than the height class count'
extra_imgs_per_class = augm_nbr - get_count_imgs_per_class(y_dataset)
total_extra_imgs = np.sum(extra_imgs_per_class)
# if extra data is needed -> run the data aumentation op
if total_extra_imgs > 0:
X_extra = np.zeros((int(total_extra_imgs), img_height, img_width, img_depth), dtype = X_train.dtype)
y_extra = np.zeros(int(total_extra_imgs))
start_idx = 0
print('start data augmentation.....')
for this_class in range(n_classes):
print('\t Class {}|Number of extra imgs{}'.format(this_class, int(extra_imgs_per_class[this_class])))
n_extra_imgs = extra_imgs_per_class[this_class]
end_idx = start_idx + n_extra_imgs
if n_extra_imgs > 0:
# get ids of all images belonging to this_class
all_imgs_id = np.argwhere(y_dataset == this_class)
new_imgs_x = np.zeros((int(n_extra_imgs), img_height, img_width, img_depth))
for k in range(int(n_extra_imgs)):
# randomly pick an original image belonging to this class
rand_id = np.random.choice(all_imgs_id[0], size = None, replace = True)
rand_img = X_train_p[rand_id]
# Transform image
new_img = random_transform(rand_img)
new_imgs_x[k, :, :, :] = new_img
# update tensors with new images and associated labels
X_extra[int(start_idx):int(end_idx)] = new_imgs_x
y_extra[int(start_idx):int(end_idx)] = np.ones((int(n_extra_imgs),)) * this_class
start_idx = end_idx
return [X_extra,y_extra]
else:
return [None,None]
# shuffle train dataset before augmentation
X_train_p, y_train = shuffle(X_train_p, y_train)
X_extra, y_extra = data_augmentation(X_train_p, y_train, augm_nbr = 4000, keep_dist = False)
if X_extra is not None:
X_train_p = np.concatenate((X_train_p, X_extra.astype('uint8')), axis=0)
y_train = np.concatenate((y_train, y_extra), axis=0)
del X_extra, y_extra
# frequency of labels in train dataset
train_labels, n_train_labels = np.unique(y_train, return_counts = True)
plt.bar(train_labels, n_train_labels, align = 'center')
plt.xlabel('class')
plt.ylabel('Frequency')
plt.xlim([-1, 43])
plt.title("frequency of labels in train dataset")
plt.show()
代码讲解:
旋转角度限制在[-15,15]度之间,因为如果旋转角度过大,有些交通标志的意思可能就会发生变化了;垂直移动范围限制在[-2,2]px之间;伸缩变换限制在[0.8,1.2]。
结果展示:
(1)、每个类增加了多少张变换后的图像
(2)‘、数据增强后的所有类数量均为4000
(五)、模型构建
# step 4: Model Architecture
epochs = 150
BATCH_SIZE = 100
def LeNet(x):
# Arguments used for tf.truncated_normal, randomly defines variables for the weights and biases for each layer
mu = 0
sigma = 0.1
# TODO: Layer 1: Convolutional. Input = 32x32x1. Output = 28x28x6.
conv1_W = tf.Variable(tf.truncated_normal(shape=(5, 5, 1, 6), mean = mu, stddev = sigma))
conv1_b = tf.Variable(tf.zeros(6))
conv1 = tf.nn.conv2d(x, conv1_W, strides=[1, 1, 1, 1], padding='VALID') + conv1_b
# TODO: Activation.
conv1 = tf.nn.relu(conv1)
# TODO: Pooling. Input = 28x28x6. Output = 14x14x6.
conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
# TODO: Layer 2: Convolutional. Output = 10x10x16.
conv2_W = tf.Variable(tf.truncated_normal(shape=(5, 5, 6, 16), mean = mu, stddev = sigma))
conv2_b = tf.Variable(tf.zeros(16))
conv2 = tf.nn.conv2d(conv1, conv2_W, strides=[1, 1, 1, 1], padding='VALID') + conv2_b
# TODO: Activation.
conv2 = tf.nn.relu(conv2)
# TODO: Pooling. Input = 10x10x16. Output = 5x5x16.
conv2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
# TODO: Flatten. Input = 5x5x16. Output = 400.
fc0 = flatten(conv2)
# TODO: Layer 3: Fully Connected. Input = 400. Output = 120.
fc1_W = tf.Variable(tf.truncated_normal(shape=(400, 120), mean = mu, stddev = sigma))
fc1_b = tf.Variable(tf.zeros(120))
fc1 = tf.matmul(fc0, fc1_W) + fc1_b
# TODO: Activation.
fc1 = tf.nn.relu(fc1)
#fc1 = tf.nn.dropout(fc1, keep_prob)
# TODO: Layer 4: Fully Connected. Input = 120. Output = 84.
fc2_W = tf.Variable(tf.truncated_normal(shape=(120, 84), mean = mu, stddev = sigma))
fc2_b = tf.Variable(tf.zeros(84))
fc2 = tf.matmul(fc1, fc2_W) + fc2_b
# TODO: Activation.
fc2 = tf.nn.relu(fc2)
#fc2 = tf.nn.dropout(fc2, keep_prob)
# TODO: Layer 5: Fully Connected. Input = 84. Output = 10.
fc3_W = tf.Variable(tf.truncated_normal(shape=(84, 43), mean = mu, stddev = sigma))
fc3_b = tf.Variable(tf.zeros(43))
logits = tf.matmul(fc2, fc3_W) + fc3_b
weights = [conv1_W, conv2_W, fc1_W, fc2_W, fc3_W]
return logits, weights
(六)、评估函数
# Step 5: Test a Model on New Images
# Train, Validate and Test the Model
x = tf.placeholder(tf.float32, (None, 32, 32, 1))
y = tf.placeholder(tf.int32, (None))
one_hot_y = tf.one_hot(y, 43)
keep_prob = tf.placeholder(tf.float32)
rate = 0.001
logits, weights = LeNet(x)
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=one_hot_y, logits=logits)
reg_loss = 0.0
for w in weights:
reg_loss += tf.nn.l2_loss(w)
L2_constant = 1e-6
loss_operation = tf.reduce_mean(cross_entropy) + L2_constant * reg_loss
optimizer = tf.train.AdamOptimizer(learning_rate = rate)
training_operation = optimizer.minimize(loss_operation)
# Model Evalution
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(one_hot_y, 1))
accuracy_operation = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
saver = tf.train.Saver()
def evaluate(X_data, y_data):
num_examples = len(X_data)
total_accuracy = 0
sess = tf.get_default_session()
for offset in range(0, num_examples, BATCH_SIZE):
batch_x, batch_y = X_data[offset:offset+BATCH_SIZE], y_data[offset:offset+BATCH_SIZE]
accuracy = sess.run(accuracy_operation, feed_dict={x: batch_x, y: batch_y, keep_prob: 0.1})
total_accuracy += (accuracy * len(batch_x))
return total_accuracy / num_examples
(七)、训练模型
# Train the Model
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
num_examples = len(X_train_p)
print("Training...")
print()
for i in range(epochs):
X_train_p, y_train = shuffle(X_train_p, y_train)
for offset in range(0, num_examples, BATCH_SIZE):
end = offset + BATCH_SIZE
batch_x, batch_y = X_train_p[offset:end], y_train[offset:end]
sess.run(training_operation, feed_dict={x: batch_x, y: batch_y, keep_prob: 0.5})
validation_accuracy = evaluate(X_valid_p, y_valid)
print("EPOCH {} ...".format(i+1))
print("Validation Accuracy = {:.3f}".format(validation_accuracy))
print()
saver.save(sess, './lenet')
print("Model saved")
结果展示:
(1)训练过程中随着epoch增加,正确率变化

(八)、验证模型
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
saver1 = tf.train.import_meta_graph('./lenet.meta')
saver1.restore(sess, "./lenet")
trai_accuracy = evaluate(X_train_p, y_train)
print("Train Set Accuracy = {:.3f}".format(trai_accuracy))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
saver2 = tf.train.import_meta_graph('./lenet.meta')
saver2.restore(sess, "./lenet")
test_accuracy = evaluate(X_test_p, y_test)
print("Test Set Accuracy = {:.3f}".format(test_accuracy))
web_images = []
path = './web_images/'
for image in os.listdir(path):
img = cv2.imread(path + image)
img = cv2.resize(img, (32,32))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
web_images.append(img)
signs = [3, 27, 14, 17, 13]
web_images_p = preprocess(np.asarray(web_images))
fig, axs = plt.subplots(1,5, figsize = (16, 11))
fig.subplots_adjust(hspace =.2, wspace = 0.001)
axs = axs.ravel()
for i in range(5):
image = web_images[i]
axs[i].axis('off')
axs[i].imshow(image)
axs[i].set_title(signs[i])
plt_img(web_images, signs)
web_images_p = preprocess(np.asarray(web_images))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
saver3 = tf.train.import_meta_graph('./lenet.meta')
saver3.restore(sess, "./lenet")
web_accuracy = evaluate(web_images_p, signs)
print("5 Web images Accuracy = {:.3f}".format(web_accuracy))
结果展示:
(1)最后的结果图,建议在Jupyter Notebook上跑,我在自己的电脑shell上跑。。。慢
![]()
![]()
![]()
本博客内容主要来自优达学城无人驾驶纳米学位,博客内容不得转载,不得作为他用,仅提供互相学习,谢谢。