MongoDB 4.0 事务实现解析
摘要: 云数据库 MongoDB 版 基于飞天分布式系统和高性能存储,提供三节点副本集的高可用架构,容灾切换,故障迁移完全透明化。
云数据库 MongoDB 版
基于飞天分布式系统和高性能存储,提供三节点副本集的高可用架构,容灾切换,故障迁移完全透明化。并提供专业的数据库在线扩容、备份回滚、性能优化等解决方案。
了解更多
上个月底 MongoDB Wolrd 宣布发布 MongoDB 4.0, 支持复制集多文档事务,阿里云数据库团队 研发工程师第一时间对事务功能的时间进行了源码分析,解析事务实现机制。
MongoDB 4.0 引入的事务功能,支持多文档ACID特性,例如使用 mongo shell 进行事务操作
> s = db.getMongo().startSession()
session { "id" : UUID("3bf55e90-5e88-44aa-a59e-a30f777f1d89") }
> s.startTransaction()
> db.coll01.insert({x: 1, y: 1})
WriteResult({ "nInserted" : 1 })
> db.coll02.insert({x: 1, y: 1})
WriteResult({ "nInserted" : 1 })
> s.commitTransaction() (或者 s.abortTransaction()回滚事务)
支持 MongoDB 4.0 的其他语言 Driver 也封装了事务相关接口,用户需要创建一个 Session,然后在 Session 上开启事务,提交事务。例如
python 版本
with client.start_session() as s:
s.start_transaction()
collection_one.insert_one(doc_one, session=s)
collection_two.insert_one(doc_two, session=s)
s.commit_transaction()
java 版本
try (ClientSession clientSession = client.startSession()) {
clientSession.startTransaction();
collection.insertOne(clientSession, docOne);
collection.insertOne(clientSession, docTwo);
clientSession.commitTransaction();
}
Session
Session 是 MongoDB 3.6 版本引入的概念,引入这个特性主要就是为实现多文档事务做准备。Session 本质上就是一个「上下文」。
在以前的版本,MongoDB 只管理单个操作的上下文,mongod 服务进程接收到一个请求,为该请求创建一个上下文 (源码里对应 OperationContext),然后在服务整个请求的过程中一直使用这个上下文,内容包括,请求耗时统计、请求占用的锁资源、请求使用的存储快照等信息。有了 Session之后,就可以让多个请求共享一个上下文,让多个请求产生关联,从而有能力支持多文档事务。
每个 Session 包含一个唯一的标识 lsid,在 4.0 版本里,用户的每个请求可以指定额外的扩展字段,主要包括:
- lsid: 请求所在 Session 的 ID, 也称 logic session id
- txnNmuber: 请求对应的事务号,事务号在一个 Session 内必须单调递增
- stmtIds: 对应请求里每个操作(以insert为例,一个insert命令可以插入多个文档)操作ID
实际上,用户在使用事务时,是不需要理解这些细节,MongoDB Driver 会自动处理,Driver 在创建 Session 时分配 lsid,接下来这个 Session 里的所以操作,Driver 会自动为这些操作加上 lsid,如果是事务操作,会自动带上 txnNumber。
值得一提的是,Session lsid 可以通过调用 startSession 命令让 server 端分配,也可以客户端自己分配,这样可以节省一次网络开销;而事务的标识,MongoDB 并没有提供一个单独的 startTransaction的命令,txnNumber 都是直接由 Driver 来分配的,Driver 只需保证一个 Session 内,txnNumber 是递增的,server 端收到新的事务请求时,会主动的开始一个新事务。
MongoDB 在 startSession 时,可以指定一系列的选项,用于控制 Session 的访问行为,主要包括:
- causalConsistency: 是否提供
causal consistency的语义,如果设置为true,不论从哪个节点读取,MongoDB 会保证 "read your own write" 的语义。参考 causal consistency - readConcern:参考 MongoDB readConcern 原理解析
- writeConcern:参考 MongoDB writeConcern 原理解析
- readPreference: 设置读取时选取节点的规则,参考 read preference
- retryWrites:如果设置为true,在复制集场景下,MongoDB 会自动重试发生重新选举的场景; 参考retryable write
ACID
Atomic
针对多文档的事务操作,MongoDB 提供 "All or nothing" 的原子语义保证。
Consistency
太难解释了,还有抛弃 Consistency 特性的数据库?
Isolation
MongoDB 提供 snapshot 隔离级别,在事务开始创建一个 WiredTiger snapshot,然后在整个事务过程中使用这个快照提供事务读。
Durability
事务使用 WriteConcern {j: ture} 时,MongoDB 一定会保证事务日志提交才返回,即使发生 crash,MongoDB 也能根据事务日志来恢复;而如果没有指定 {j: true} 级别,即使事务提交成功了,在 crash recovery 之后,事务的也可能被回滚掉。
事务与复制
复制集配置下,MongoDB 整个事务在提交时,会记录一条 oplog(oplog 是一个普通的文档,所以目前版本里事务的修改加起来不能超过文档大小 16MB的限制),包含事务里所有的操作,备节点拉取oplog,并在本地重放事务操作。
事务 oplog 示例,包含事务操作的 lsid,txnNumber,以及事务内所有的操作日志(applyOps字段)
"ts" : Timestamp(1530696933, 1), "t" : NumberLong(1), "h" : NumberLong("4217817601701821530"), "v" : 2, "op" : "c", "ns" : "admin.$cmd", "wall" : ISODate("2018-07-04T09:35:33.549Z"), "lsid" : { "id" : UUID("e675c046-d70b-44c2-ad8d-3f34f2019a7e"), "uid" : BinData(0,"47DEQpj8HBSa+/TImW+5JCeuQeRkm5NMpJWZG3hSuFU=") }, "txnNumber" : NumberLong(0), "stmtId" : 0, "prevOpTime" : { "ts" : Timestamp(0, 0), "t" : NumberLong(-1) }, "o" : { "applyOps" : [ { "op" : "i", "ns" : "test.coll2", "ui" : UUID("a49ccd80-6cfc-4896-9740-c5bff41e7cce"), "o" : { "_id" : ObjectId("5b3c94d4624d615ede6097ae"), "x" : 20000 } }, { "op" : "i", "ns" : "test.coll3", "ui" : UUID("31d7ae62-fe78-44f5-ba06-595ae3b871fc"), "o" : { "_id" : ObjectId("5b3c94d9624d615ede6097af"), "x" : 20000 } } ] } }
整个重放过程如下:
- 获取当前 Batch (后台不断拉取 oplog 放入 Batch)
- 设置
OplogTruncateAfterPoint时间戳为 Batch里第一条 oplog 时间戳 (存储在 local.replset.oplogTruncateAfterPoint 集合) - 写入 Batch 里所有的 oplog 到 local.oplog.rs 集合,根据 oplog 条数,如果数量较多,会并发写入加速
- 清理
OplogTruncateAfterPoint, 标识 oplog 完全成功写入;如果在本步骤完成前 crash,重启恢复时,发现oplogTruncateAfterPoint被设置,会将 oplog 截短到该时间戳,以恢复到一致的状态点。 - 将 oplog 划分到到多个线程并发重放,为了提升并发效率,事务产生的 oplog 包含的所有修改操作,跟一条普通单条操作的 oplog 一样,会据文档ID划分到多个线程。
- 更新
ApplyThrough时间戳为 Batch 里最后一条 oplog 时间戳,标识下一次重启后,从该位置重新同步,如果本步骤之前失败,重启恢复时,会从ApplyThrough上一次的值(上一个 Batch 最后一条 oplog)拉取 oplog。 - 更新 oplog 可见时间戳,如果有其他节点从该备节点同步,此时就能读到这部分新写入的 oplog
- 更新本地 Snapshot(时间戳),新的写入将对用户可见。
事务与存储引擎
事务时序统一
WiredTiger 很早就支持事务,在 3.x 版本里,MongoDB 就通过 WiredTiger 事务,来保证一条修改操作,对数据、索引、oplog 三者修改的原子性。但实际上 MongoDB 经过多个版本的迭代,才提供了事务接口,核心难点就是时序问题。
MongoDB 通过 oplog 时间戳来标识全局顺序,而 WiredTiger 通过内部的事务ID来标识全局顺序,在实现上,2者没有任何关联。这就导致在并发情况下, MongoDB 看到的事务提交顺序与 WiredTiger 看到的事务提交顺序不一致。
为解决这个问题,WiredTier 3.0 引入事务时间戳(transaction timestamp)机制,应用程序可以通过 WT_SESSION::timestamp_transaction 接口显式的给 WiredTiger 事务分配 commit timestmap,然后就可以实现指定时间戳读(read "as of" a timestamp)。有了 read "as of" a timestamp 特性后,在重放 oplog 时,备节点上的读就不会再跟重放 oplog 有冲突了,不会因重放 oplog 而阻塞读请求,这是4.0版本一个巨大的提升。
/*
* __wt_txn_visible --
* Can the current transaction see the given ID / timestamp?
*/
static inline bool
__wt_txn_visible(
WT_SESSION_IMPL *session, uint64_t id, const wt_timestamp_t *timestamp)
{
if (!__txn_visible_id(session, id))
return (false);
/* Transactions read their writes, regardless of timestamps. */
if (F_ISSET(&session->txn, WT_TXN_HAS_ID) && id == session->txn.id)
return (true);
#ifdef HAVE_TIMESTAMPS
{
WT_TXN *txn = &session->txn;
/* Timestamp check. */
if (!F_ISSET(txn, WT_TXN_HAS_TS_READ) || timestamp == NULL)
return (true);
return (__wt_timestamp_cmp(timestamp, &txn->read_timestamp) <= 0);
}
#else
WT_UNUSED(timestamp);
return (true);
#endif
}
从上面的代码可以看到,再引入事务时间戳之后,在可见性判断时,还会额外检查时间戳,上层读取时指定了时间戳读,则只能看到该时间戳以前的数据。而 MongoDB 在提交事务时,会将 oplog 时间戳跟事务关联,从而达到 MongoDB Server 层时序与 WiredTiger 层时序一致的目的。
事务对 cache 的影响
WiredTiger(WT) 事务会打开一个快照,而快照的存在的 WiredTiger cache evict 是有影响的。一个 WT page 上,有N个版本的修改,如果这些修改没有全局可见(参考 __wt_txn_visible_all),这个 page 是不能 evict 的(参考 __wt_page_can_evict)。
在 3.x 版本里,一个写请求对数据、索引、oplog的修改会放到一个 WT 事务里,事务的提交由 MongoDB 自己控制,MongoDB 会尽可能快的提交事务,完成写清求;但 4.0 引入事务之后,事务的提交由应用程序控制,可能出现一个事务修改很多,并且很长时间不提交,这会给 WT cache evict 造成很大的影响,如果大量内存无法 evict,最终就会进入 cache stuck 状态。
为了尽量减小 WT cache 压力,MongoDB 4.0 事务功能有一些限制,但事务资源占用超过一定阈值时,会自动 abort 来释放资源。规则包括
- 事务的生命周期不能超过
transactionLifetimeLimitSeconds(默认60s),该配置可在线修改 - 事务修改的文档数不能超过 1000 ,不可修改
- 事务修改产生的 oplog 不能超过 16mb,这个主要是 MongoDB 文档大小的限制, oplog 也是一个普通的文档,也必须遵守这个约束。
Read as of a timestamp 与 oldest timestamp
Read as of a timestamp 依赖 WiredTiger 在内存里维护多版本,每个版本跟一个时间戳关联,只要 MongoDB 层可能需要读的版本,引擎层就必须维护这个版本的资源,如果保留的版本太多,也会对 WT cache 产生很大的压力。
WiredTiger 提供设置 oldest timestamp 的功能,允许由 MongoDB 来设置该时间戳,含义是Read as of a timestamp 不会提供更小的时间戳来进行一致性读,也就是说,WiredTiger 无需维护 oldest timestamp 之前的所有历史版本。MongoDB 层需要频繁(及时)更新 oldest timestamp,避免让 WT cache 压力太大。
引擎层 Rollback 与 stable timestamp
在 3.x 版本里,MongoDB 复制集的回滚动作是在 Server 层面完成,但节点需要回滚时,会根据要回滚的 oplog 不断应用相反的操作,或从回滚源上读取最新的版本,整个回滚操作效率很低。
4.0 版本实现了存储引擎层的回滚机制,当复制集节点需要回滚时,直接调用 WiredTiger 接口,将数据回滚到某个稳定版本(实际上就是一个 Checkpoint),这个稳定版本则依赖于 stable timestamp。WiredTiger 会确保 stable timestamp 之后的数据不会写到 Checkpoint里,MongoDB 根据复制集的同步状态,当数据已经同步到大多数节点时(Majority commited),会更新 stable timestamp,因为这些数据已经提交到大多数节点了,一定不会发生 ROLLBACK,这个时间戳之前的数据就都可以写到 Checkpoint 里了。
MongoDB 需要确保频繁(及时)的更新 stable timestamp,否则影响 WT Checkpoint 行为,导致很多内存无法释放。
分布式事务
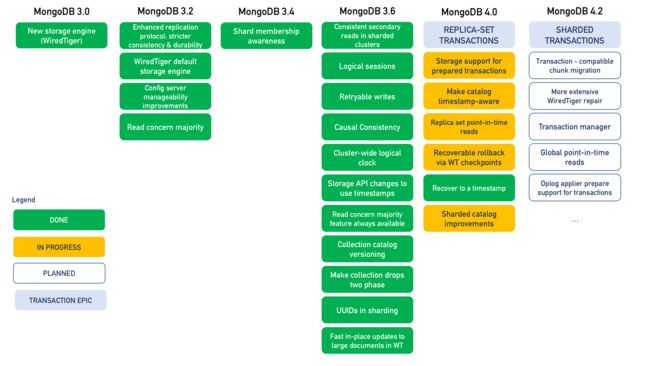
MongoDB 4.0 支持副本集多文档事务,并计划在 4.2 版本支持分片集群事务功能。下图是从 MongoDB 3.0 引入 WiredTiger 到 4.0 支持多文档事务的功能迭代图,可以发现一盘大棋即将上线,敬请期待。
云数据库 MongoDB 版
基于飞天分布式系统和高性能存储,提供三节点副本集的高可用架构,容灾切换,故障迁移完全透明化。并提供专业的数据库在线扩容、备份回滚、性能优化等解决方案。
了解更多
原文链接
本文为云栖社区原创内容,未经允许不得转载