在hive、Spark SQL中引入窗口函数
一、Hive中的分析函数
分析函数主要用于实现分组内所有和连续累积的统计。
分析函数的语法结构一般是:
分析函数名(参数) OVER (PARTITION BY子句 ORDER BY子句 ROWS/RANGE子句)。
即由以下三部分组成:
分析函数名:如sum、max、min、count、avg等聚集函数以及lead、lag行比较函数等;
over: 关键字,表示前面的函数是分析函数,不是普通的集合函数;
分析子句:over关键字后面括号内的内容;
分析子句又由下面三部分组成:
PARTITION BY :分组子句,表示分析函数的计算范围,不同的组互不相干;
ORDER BY: 排序子句,表示分组后,组内的排序方式;
ROWS/RANGE:窗口子句,是在分组(PARTITION BY)后,组内的子分组(也称窗口),此时分析函数的计算范围窗口,而不是PARTITON。窗口有两种,ROWS和RANGE;
下面分析rows与range窗口子句的用法,先看下面例子:
实例
1 WITH t AS
2 (SELECT (CASE
3 WHEN LEVEL IN (1, 2) THEN
4 1
5 WHEN LEVEL IN (4, 5) THEN
6 6
7 ELSE
8 LEVEL
9 END) ID
10 FROM dual
11 CONNECT BY LEVEL < 10)
12 SELECT id,
13 SUM(ID) over(ORDER BY ID) default_sum,
14 SUM(ID) over(ORDER BY ID RANGE BETWEEN unbounded preceding AND CURRENT ROW) range_unbound_sum,
15 SUM(ID) over(ORDER BY ID ROWS BETWEEN unbounded preceding AND CURRENT ROW) rows_unbound_sum,
16 SUM(ID) over(ORDER BY ID RANGE BETWEEN 1 preceding AND 2 following) range_sum,
17 SUM(ID) over(ORDER BY ID ROWS BETWEEN 1 preceding AND 2 following) rows_sum
18* FROM t
ID DEFAULT_SUM RANGE_UNBOUND_SUM ROWS_UNBOUND_SUM RANGE_SUM ROWS_SUM
1 2 2 1 5 5
1 2 2 2 5 11
3 5 5 5 3 16
6 23 23 11 33 21
6 23 23 17 33 25
6 23 23 23 33 27
7 30 30 30 42 30
8 38 38 38 24 24
9 47 47 47 17 17已选择9行。
从上面的例子可知:
1、窗口子句必须和order by 子句同时使用,且如果指定了order by 子句未指定窗口子句,则默认为RANGE BETWEEN unbounded preceding AND CURRENT ROW,如上例结果集中的defult_sum等于range_unbound_sum; 比较特殊。注意和
RANGE BETWEEN 【num】preceding AND 【num】 following的比较
2、如果分析函数没有指定ORDER BY子句,也就不存在ROWS/RANGE窗口的计算;
3、range是逻辑窗口,是指定当前行对应值(order by 字段)的范围取值,列数不固定,只要行值在范围内,对应列都包含在内,如上例中range_sum(即range 1 preceing and 2 following)例的分析结果:
当id=1时,是sum为1-1<=id<=1+2 的和,即sum=1+1+3=5(取id为1,1,3);
当id=3时,是sum为3-1<=id<=3+2 的和,即sum=3(取id为3);
当id=6时,是sum为6-1<=id<=6+2 的和,即sum=6+6+6+7+8=33(取id为6,6,6,7,8);
以此类推下去,结果如上例中所示。
4、rows是物理窗口,即根据order by 子句排序后,取的前N行及后N行的数据计算(与当前行的值无关,只与排序后的行号相关),如上例中rows_sum例结果,是取前1行和后2行数据的求和,分析上例rows_sum的结果:
当id=1(第一个1时)时,前一行没数,后二行分别是1和3,sum=1+1+3=5;
当id=3时,前一行id=1,后二行id都为6,则sum=1+3+6+6=16;
以此类推下去,结果如上例所示。
注:行比较分析函数lead和lag无window(窗口)子句。
需要指定一个窗口的边界(ROWS/RANGE字句),语法是这样的:
ROWS between CURRENT ROW | UNBOUNDED PRECEDING | [num] PRECEDING AND UNBOUNDED FOLLOWING | [num] FOLLOWING| CURRENT ROW
或
RANGE between CURRENT ROW | UNBOUNDED PRECEDING | [num] PRECEDING AND UNBOUNDED FOLLOWING | [num] FOLLOWING| CURRENT ROW
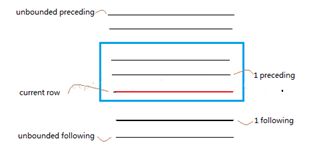
ROWS是物理窗口,从行数上控制窗口的尺寸的;
RANGE是逻辑窗口,从列值上控制窗口的尺寸。
结合order by子句使用,如果在order by子句后面没有指定窗口子句,则默认为:range between unbounded preceding and current row
客户表:
Create table customer
( customer string,
age int,
rank int,
income decimal(10,3),
ismarry string
)
comment 'This is a customer table'
row format delimited
fields terminated by '\t'
stored as textfile;
customer.txt
A 23 1 10000 S
B 29 3 20000 M
C 23 4 30000 S
D 27 5 40000 M
产品表
create table product(
customer string,
toubao_date date,
baodan string,
birthdate date,
ca_amount decimal(20,2),
ca_premium decimal(20,2),
P_Cp004_Total_Cpnst decimal(20,2),
term_code string,
relation string,
ca_jfperiod decimal(20,2),
jfperiod_unit string,
ca_bxperiod decimal(20,2),
bxperiod_unit decimal,
code string
)
comment 'This is a product table'
row format delimited
fields terminated by '\t'
stored as textfile;
product.txt
A 2000-7-1 两全寿险 1960-7-1 500 20 300 L M 12 M 11 Y 寿险
A 2000-8-1 长期健康险 1965-1-1 600 30 200 L M 3 M 3 G 健康险
A 2000-9-1 终身寿险 1980-4-1 700 40 500 L 其他(非M) 20 Y 33 M 寿险
A 2010-2-1 定期年金 1980-3-2 500 50 300 L M 5 Y 10 Y 年金
A 2018-5-1 账户型万能 1965-7-1 300 60 200 L 其他(非M) 6 G 20 M 万能险
B 2000-3-1 长期意外险 1970-2-7 300 70 120 L M 9 Y 30 Y 健康险
B 2011-2-1 终身年金 1987-1-1 800 80 800 L 其他(非M) 20 Y 10 Y 年金
B 2017-1-1 定期寿险 1988-1-3 200 91 100 L 其他(非M) 30 M 10 M 寿险
B 2012-2-1 万能险 1992-2-1 300 90 200 L M 90 D 20 Y 万能险
C 2013-6-1 两全寿险 1986-2-3 300 94 300 L 其他(非M) 120 M 90 D 寿险
C 2000-1-1 终身寿险 1977-3-2 400 92 400 L 其他(非M) 5 Y 120 D 寿险
D 2010-2-1 其他 1980-1-1 300 95 200 S 其他(非M) 1 D 7 D
C 2011-2-1 定期年金 1980-3-2 500 93 300 L M 5 Y 10 Y 年金
D 2012-1-1 定期年金 1980-3-2 500 96 300 L M 5 Y 10 Y 年金
指标计算:
截止到该客户基准时间点保费的总和
该客户基准时间点之前保费的总和。
保费+之前所有+最近一次:该客户基准时间点之前所有保单中最近一次的保费。
该客户基准时间点之前所有保单中长险保单的保费总和。
该客户基准时间点之前所有保单中属于家人保单的保费总和。
该产品类别下基准时间点之前1年时间内所有保单件数。
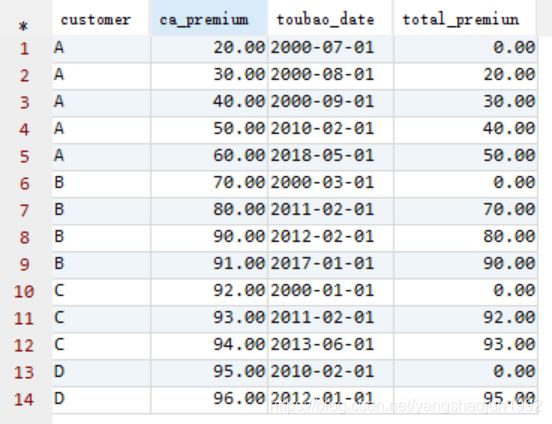
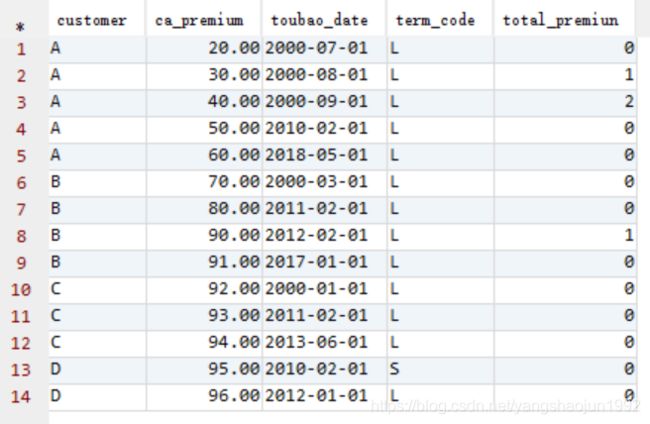
1)截止到该客户基准时间点保费的总和
select customer,ca_premium,toubao_date,sum(ca_premium) over(partition by customer order by toubao_date rows between unbounded preceding and current row) total_premiun
from (
select t2.*,t1.age,t1.rank,t1.income,t1.ismarry from customer t1 left join product t2 on t1.customer=t2.customer) t

2)该客户基准时间点之前保费的总和。
select customer,ca_premium,toubao_date,
sum(ca_premium) over(partition by customer order by toubao_date
rows between unbounded preceding and 1 preceding) total_premiun
from (select t2.*,t1.age,t1.rank,t1.INCOME,t1.ISMARRY from customer t1 left join product t2 on t1.customer=t2.customer) t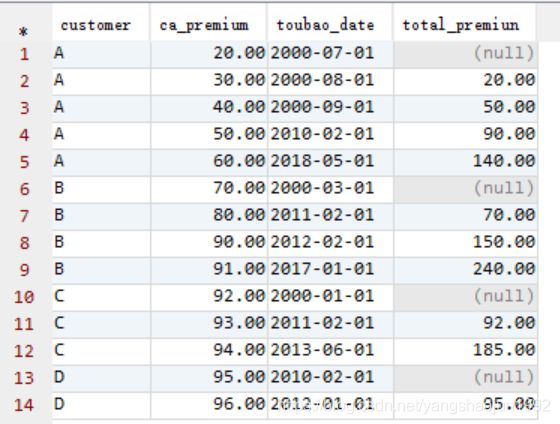
3)保费+之前所有+最近一次:该客户基准时间点之前所有保单中最近一次的保费。
select customer,ca_premium,toubao_date,
lag(ca_premium,1,0) over(partition by customer order by toubao_date ) total_premiun
from (select t2.*,t1.age,t1.rank,t1.INCOME,t1.ISMARRY from customer t1 left join product t2 on t1.customer=t2.customer) t
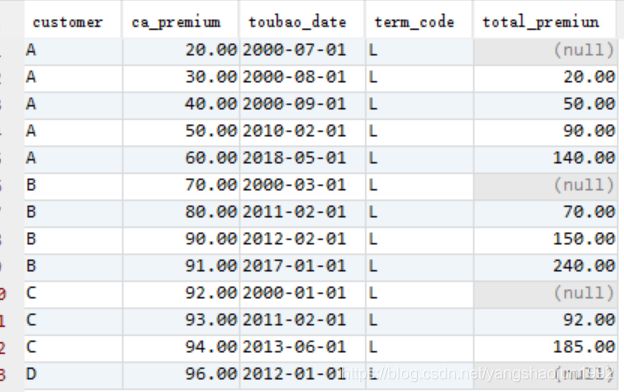
4)该客户基准时间点之前所有保单中长险保单的保费总和。
select customer,ca_premium,toubao_date, TERM_CODE,
sum(ca_premium) over(partition by customer order by toubao_date rows between unbounded preceding and 1 preceding) total_premiun
from (select t2.*,t1.age,t1.rank,t1.INCOME,t1.ISMARRY from customer t1 left join product t2 on t1.customer=t2.customer) t
where TERM_CODE='L'
5) 该客户基准时间点之前所有保单中属于家人保单的保费总和。
select customer,ca_premium,toubao_date, TERM_CODE,
sum(ca_premium) over(partition by customer order by toubao_date rows between unbounded preceding and 1 preceding) total_premiun
from (select t2.*,t1.age,t1.rank,t1.INCOME,t1.ISMARRY from customer t1 left join product t2 on t1.customer=t2.customer) t
where RELATION='M';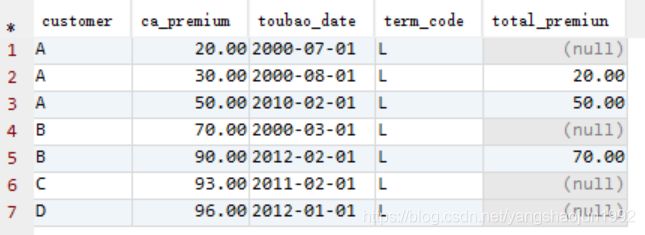
6) 该产品类别下基准时间点之前1年时间内所有保单件数。
select customer,ca_premium,toubao_date, TERM_CODE,
count(ca_premium) over(partition by customer order by unix_timestamp(toubao_date,"yyyy-MM-dd HH:mm:ss") range between 31536000 preceding and 1 preceding) total_premiun
from (select t2.*,t1.age,t1.rank,t1.INCOME,t1.ISMARRY from customer t1 left join product t2 on t1.customer=t2.customer) t
总结:
a) 如果不指定ORDER BY,则将分组内所有指定值累加;

b) 如果不指定窗口的字句默认为 RANGE BETWEEN unbounded preceding AND CURRENT ROW
c) 关键是理解 ROWS BETWEEN 和RANGES BETWEEN含义 也就是窗口字句
PRECEDING:往前
FOLLOWING:往后
CURRENT ROW:当前行
UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING:表示到后面的终点
上面我们已经学会了窗口函数的定义以及语法使用,下面我们继续继续介绍其他比较常用的窗口函数。
1) 窗口函数 Lag, Lead, First_value,Last_value
Lag, Lead、这两个函数为常用的窗口函数,可以返回上下数据行的数据.
LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值
LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值, 与LAG相反
-- 组内排序后,向后或向前偏移
-- 如果省略掉第三个参数,默认为NULL,否则补上。
select
dp_id,
mt,
payment,
LAG(mt,2) over(partition by dp_id order by mt) mt_new
from test2;
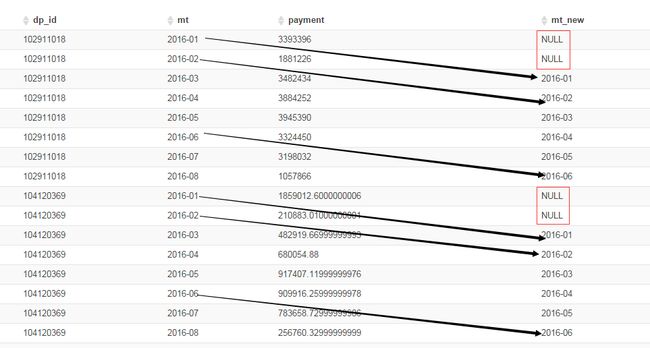
-- 组内排序后,向后或向前偏移
-- 如果省略掉第三个参数,默认为NULL,否则补上。
select dp_id, mt, payment, LEAD(mt,2,'1111-11') over(partition by dp_id order by mt) mt_new from test2;

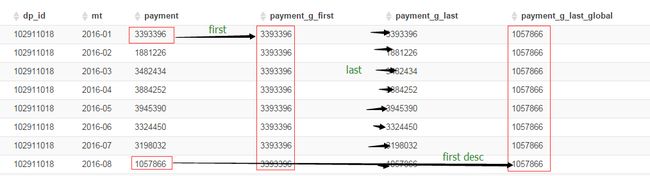
FIRST_VALUE, LAST_VALUE
first_value: 取分组内排序后,截止到当前行,第一个值
last_value: 取分组内排序后,截止到当前行,最后一个值
-- FIRST_VALUE 获得组内当前行往前的首个值 -- LAST_VALUE 获得组内当前行往前的最后一个值 -- FIRST_VALUE(DESC) 获得组内全局的最后一个值 select dp_id, mt, payment, FIRST_VALUE(payment) over(partition by dp_id order by mt) payment_g_first, LAST_VALUE(payment) over(partition by dp_id order by mt) payment_g_last, FIRST_VALUE(payment) over(partition by dp_id order by mt desc) payment_g_last_global from test2 ORDER BY dp_id,mt;
2)排名函数 Rank,Dense_Rank, Row_Number
R() over (partion by col1... order by col2... desc/asc)
select class1, score, rank() over(partition by class1 order by score desc) rk1, dense_rank() over(partition by class1 order by score desc) rk2, row_number() over(partition by class1 order by score desc) rk3 from zyy_test1;

如上图所示,rank 会对相同数值,输出相同的序号,而且下一个序号不间断;
dense_rank 会对相同数值,输出相同的序号,但下一个序号,间断
row_number 会对所有数值输出不同的序号,序号唯一连续;
二、SparkSQL窗口函数
在这篇博文中,我们介绍了Apache Spark 1.4中添加的新窗口功能。 窗口函数允许Spark SQL的用户计算结果,例如给定行的排名或输入行范围内的移动平均值。 它们显着提高了Spark的SQL和DataFrame API的表现力。
与聚集函数一样,窗口函数也针对定义的行集(组)执行聚集,但它不像聚集函数那样每组之返回一个值,窗口函数可以为每组返回多个值。实际上,DB2中称这种函数为联机分析处理OLAP函数,而Oracle把它们称为解析函数,但ISO SQL标准把它们称为窗口函数。窗口函数一般在OLAP分析、制作报表过程中会使用到。
什么是窗口功能?
在1.4之前,Spark SQL支持两种可用于计算单个返回值的函数。 内置函数或UDF(例如substr或round)将单行中的值作为输入,并为每个输入行生成单个返回值。 聚合函数(如SUM或MAX)对一组行进行操作,并为每个组计算单个返回值。
虽然这些在实践中都非常有用,但仍然存在许多单独使用这些类型的功能无法表达的操作。 具体来说,无法同时对一组行进行操作,同时仍为每个输入行返回单个值。 这种限制使得难以进行各种数据处理任务,例如计算移动平均值,计算累积和,或访问出现在当前行之前的行的值。 幸运的是,对于Spark SQL的用户来说,窗口函数填补了这个空白。
窗口函数的核心是根据一组行(称为Frame)计算表的每个输入行的返回值。 每个输入行都可以有一个与之关联的唯一帧。 窗口函数的这种特性使它们比其他函数更强大,并且允许用户表达各种数据处理任务,这些任务很难(如果不是不可能的话)在没有窗口函数的情况下以简洁的方式表达。 现在,我们来看看两个例子。
假设我们有一个productRevenue表,如下所示。
我们想回答两个问题:
每个类别中最畅销和第二畅销的产品是什么?
每种产品的收入与该产品同类产品中最畅销产品的收入之间有何差异?
要回答第一个问题“每个类别中哪些是畅销产品和第二畅销产品?”,我们需要根据产品收入对产品进行排名,并选择最畅销和第二畅销产品。 产品根据排名。 下面是用于通过使用窗口函数dense_rank来回答这个问题的SQL查询(我们将在下一节中解释使用窗口函数的语法)。

SELECT
product,
category,
revenue
FROM (
SELECT
product,
category,
revenue,
dense_rank() OVER (PARTITION BY category ORDER BY revenue DESC) as rank
FROM productRevenue) tmp
WHERE
rank <= 2此查询的结果如下所示。 在不使用窗口函数的情况下,很难用SQL表达查询,即使可以表达SQL查询,底层引擎也很难有效地评估查询。
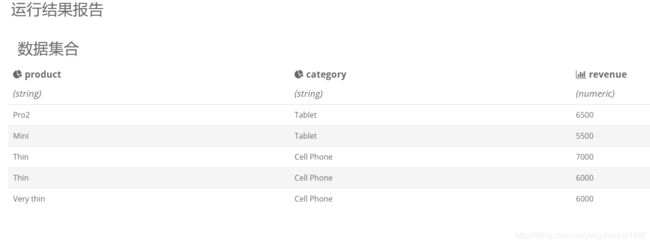
Note:这里category分组取top2的结果中,category为Cell Phone中有三条数据。
如果使用row_number() ;category为Cell Phone中只有二条数据。
先说明一下,row_number()开窗函数,它的作用是什么?
其实,就是给每个分组的数据,按照其排序顺序,打上一个分组内的行号!
如:有一个分组date=20160706,里面看有3数据,11211,11212,11213
那么对这个分组的每一行使用row_number()开窗函数以后,这个三行会打上一个组内的行号!!!
行号是从1开始递增!!! 比如最后结果就是 11211 1, 11212 2, 11213 3SELECT
product,
category,
revenue
FROM (
SELECT
product,
category,
revenue,
row_number() OVER (PARTITION BY category ORDER BY revenue DESC) as rank
FROM productRevenue) tmp
WHERE
rank <= 2
对于第二个问题“每个产品的收入与同类产品中最畅销产品的收入之间有什么区别?”,要计算产品的收入差异,我们需要找到每种产品的同类产品最高的收入值。 下面Python DataFrame程序可以解决此问题。
import sys
from pyspark.sql.window import Window
import pyspark.sql.functions as func
windowSpec = \
Window
.partitionBy(df['category']) \
.orderBy(df['revenue'].desc()) \
.rangeBetween(-sys.maxsize, sys.maxsize)
dataFrame = sqlContext.table("productRevenue")
revenue_difference = \
(func.max(dataFrame['revenue']).over(windowSpec) - dataFrame['revenue'])
dataFrame.select(
dataFrame['product'],
dataFrame['category'],
dataFrame['revenue'],
revenue_difference.alias("revenue_difference"))该程序的结果如下所示。 如果不使用窗口函数,用户必须找到所有类别的所有最高收入值,然后将此派生数据集与原始productRevenue表连接以计算收入差异。

不使用窗口函数实现方式
select t3.*,t3.max_revenue-t3.revenue as difference from (
select t1.*,t2.max_revenue from df t1 left join
(SELECT category,max(revenue) max_revenue FROM df group by category) t2
on t1.category=t2.category
) t3
使用窗口函数
Spark SQL支持三种窗口函数:排名函数,分析函数和聚合函数。 可用的排名函数和分析函数总结在下表中。 对于聚合函数,用户可以使用任何现有的聚合函数作为窗口函数。

要使用窗口函数,用户需要标记一个函数被用作窗口函数
在SQL中受支持的函数之后添加OVER子句,例如 avg(revenue)over(...); 要么
在DataFrame API中的受支持函数上调用over方法 rank().over(...).。
一旦将函数标记为窗口函数后,下一个关键步骤是定义与此函数关联的窗口规范。窗口规范定义哪些行包含在与给定输入行关联的frame中。窗口规范包括三个部分:
分区规范:控制在给定的行数据中,哪些行位于同一分区中。也就是说,用户希望在排序和frame之前确保将具有相同类别值的所有行收集到同一台机器上。如果没有给出分区规范,则必须将所有数据收集到一台机器上。(在分区的基础上排序)
排序规范:控制分区中行的排序方式,确定给定行在其分区中的位置。
frame规范:根据它们与当前行的相对位置,说明当前输入行的frame中将包含哪些行。例如,“当前行之前的三行到当前行”描述了包括当前输入行和当前行之前出现的三行的frame
在SQL中,PARTITION BY和ORDER BY关键字分别用于指定分区规范的分区表达式和排序规范的排序表达式。 SQL语法如下所示。
OVER (PARTITION BY ... ORDER BY ...)
在DataFrame API中,我们提供实用程序函数来定义窗口规范。 以Python为例,用户可以指定分区表达式和排序表达式,如下所示。
from pyspark.sql.window import Window
windowSpec = \
Window \
.partitionBy(...) \
.orderBy(...)除了排序和分区之外,用户还需要定义frame的起始边界,frame的结束边界和frame的类型,它们是frame规范的三个组成部分。
有五种类型的边界,它们是
UNBOUNDED PRECEDING,UNBOUNDED FOLLOWING,CURRENT ROW,
对于其他三种类型的边界,它们指定与当前输入行的位置的偏移量,并且它们的具体含义是基于frame的类型定义的。 有两种类型的frame,ROW frame和RANGE frame。
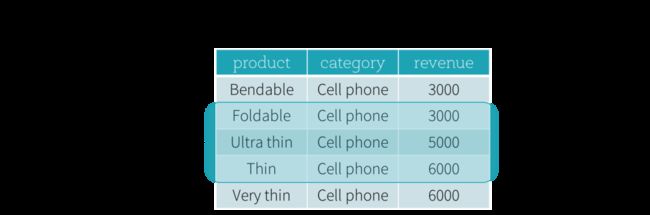
Row Frame
ROW Frame基于当前输入行位置的物理偏移,这意味着CURRENT ROW,
如果CURRENT ROW用作边界,则表示当前输入行。
range Frame
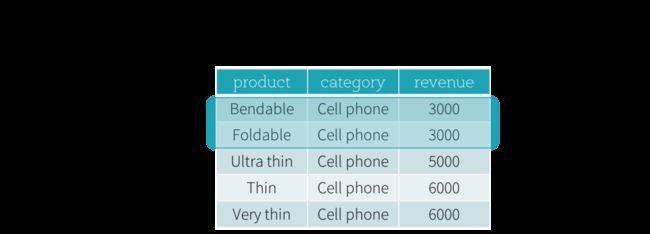
RANGE Frame基于来自当前输入行的位置的逻辑偏移,并且具有与ROW Frame类似的语法。逻辑偏移是当前输入行的排序表达式的值与Frame的边界行的相同表达式的值之间的差。由于此定义,当使用RANGE Frame时,仅允许单个排序表达式。此外,对于RANGE Frame,就边界计算而言,具有与当前输入行的排序表达式的相同值的所有行被认为是相同的行。
现在,我们来看一个例子。在此示例中,排序表达式是收入;起始边界是2000 PRECEDING;结束边界为1000 FOLLOWING(此Frame在SQL语法中定义为2000 PRECEDING和1000 FOLLOWING范围)。以下五个图说明了如何使用当前输入行的更新来更新 Frame。基本上,对于每个当前输入行,根据收入的价值,我们计算收入范围[当前收入值 - 2000,当前收入值+ 1000]。收入值落在此范围内的所有行都位于当前输入行的Frame中。




总之,要定义窗口规范,用户可以在SQL中使用以下语法。
OVER(PARTITION BY ... ORDER BY ... frame_type BETWEEN start AND end)
这里,frame_type可以是ROWS(对于ROW Frame)或RANGE(对于RANGE Frame); start可以是UNBOUNDED PRECEDING,CURRENT ROW,
在Python DataFrame API中,用户可以按如下方式定义窗口规范。
下一步是什么?
自Spark 1.4发布以来,我们一直积极与社区成员合作进行优化,以提高性能并减少操作员评估窗口函数的内存消耗。其中一些将在Spark 1.5中添加,其他将在我们的未来版本中添加。除了性能改进工作之外,我们将在不久的将来添加两个功能,以使Spark SQL中的窗口功能支持更加强大。首先,我们一直致力于为Date和Timestamp数据类型添加Interval数据类型支持(SPARK-8943)。使用Interval数据类型,用户可以将间隔用作