SparkSQL简介
| 日期 |
版本 |
修订 |
审批 |
修订说明 |
| 2016.10.20 |
1.0 |
章鑫8 |
|
初始版本 |
|
|
|
|
|
|
1 简介
SparkSQL是Spark的一个组件,用于结构化数据的计算,SparkSQL提供了一个称为DataFrames的编程抽象,DataFrames可以充当分布式SQL查询引擎。
与SparkSQL紧密相关的组件是Shark和hive,其中Shark已经被开发者摒弃。
2 开发背景
2.1 Shark和hive
SparkSQL的前身是Shark,给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,Hive应运而生,它是当时唯一运行在Hadoop上的SQL-on-Hadoop工具。但是MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,降低的运行效率,为了提高SQL-on-Hadoop的效率,大量的SQL-on-Hadoop工具开始产生,其中表现较为突出的是:
Ø MapR的Drill
Ø Cloudera的Impala
Ø Shark
其中Shark是伯克利实验室Spark生态环境的组件之一,它修改了下图1所示的右下角的内存管理、物理计划、执行三个模块,并使之能运行在Spark引擎上,从而使得SQL查询的速度得到10-100倍的提升。
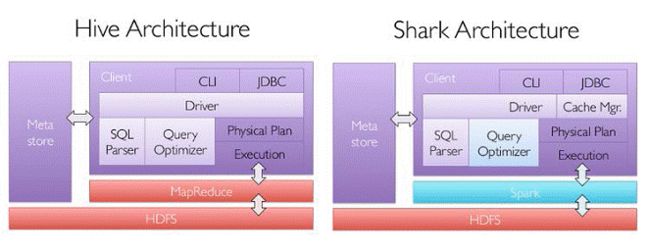
图1 hive和Shark框架
2.2 Shark和SparkSQL
随着Spark的发展,对于野心勃勃的Spark团队来说,Shark对于Hive的太多依赖(如
采用Hive的语法解析器、查询优化器等等),制约了Spark的One Stack Rule Them All的既定方针,制约了Spark各个组件的相互集成,所以提出了SparkSQL项目。SparkSQL抛弃原有Shark的代码,汲取了Shark的一些优点,如内存列存储(In-Memory ColumnarStorage)、Hive兼容性等,重新开发了SparkSQL代码;由于摆脱了对Hive的依赖性,SparkSQL无论在数据兼容、性能优化、组件扩展方面都得到了极大的方便。
Ø 数据兼容方面,不但兼容Hive,还可以从RDD、parquet文件、JSON文件中获取数据,未来版本甚至支持获取RDBMS数据以及cassandra等NOSQL数据;
Ø 性能优化方面,除了采取In-Memory ColumnarStorage、byte-codegeneration等优化技术外、将会引进CostModel对查询进行动态评估、获取最佳物理计划等等;
Ø 组件扩展方面,无论是SQL的语法解析器、分析器还是优化器都可以重新定义,进行扩展。
2014年6月1日Shark项目和SparkSQL项目的主持人Reynold Xin宣布:停止对Shark的开发,团队将所有资源放SparkSQL项目上,至此,Shark的发展画上了句话,但也因此发展出两个直线:SparkSQL和Hive on Spark。
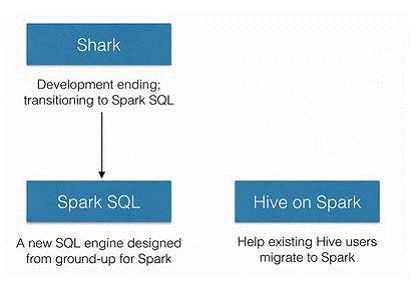
图2
其中SparkSQL作为Spark生态的一员继续发展,而不再受限于Hive,只是兼容Hive;而Hive on Spark是一个Hive的发展计划,该计划将Spark作为Hive的底层引擎之一,也就是说,Hive将不再受限于一个引擎,可以采用Map-Reduce、Tez、Spark等引擎。
3 技术概念
相比于Spark RDD API,Spark SQL包含了对结构化数据和在其上的运算的更多的信息,
Spark SQL使用这些信息进行了额外的优化,使对结构化数据的操作更加高效和方便。
有多种方式去使用SparkSQL,包括SQL、DataFrames API和Datasets API。但无论是哪种API或者是编程语言,它们都是基于同样的执行引擎,因此你可以在不同的API之间随意切换,它们各有各的特点。
.
3.1 SQL
使用SparkSQL的一种方式就是通过SQL语句来执行SQL查询。当在编程语言中使用
SQL时,其返回结果将被封装为一个DATAFrames。
3.2 DataFrame
DataFrame是一个分布式集合,其中数据被组织为命名的列。它概念上等价于关系数
据库中的表,但底层做了更多的优化。DataFrame可以从很多数据源构建,比如:已经存在的RDD、结构化的文件、外部数据库、Hive表等。
DataFrame的前身是SchemaRDD,从Spark 1.3.0开始SchemaRDD更名为DataFrame。与SchemaRDD的主要区别是:DataFrame不再直接继承自RDD,而是自己实现了RDD的绝大多数功能。你仍旧可以在DataFrame上调用.rdd方法将其转换为一个RDD。RDD可看做是分布式的对象的集合,Spark并不知道对象的详细信息,DataFrame可看做是分布式的Row对象的集合,其提供了由列组成的详细信息,使得SparkSQL可以进行某些形式的执行优化。DataFrame和普通的RDD的逻辑框架区别如下所示:
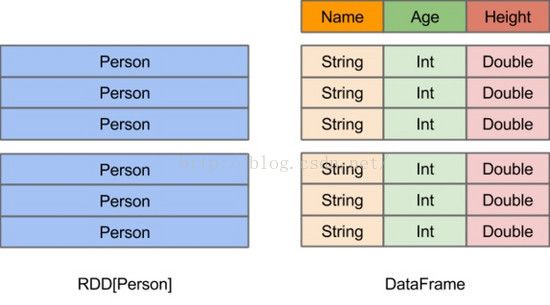
图3 RDD和DataFrame
DataFrame不仅比RDD有更加丰富的算子,更重要的是它可以进行执行计划优化(得益于CatalystSQL解析器),另外Tungsten项目给DataFrame的执行效率带来了很大提升(不过Tungsten优化也可能在后续开发中加入到RDD API中)。
但是在有些情况下RDD可以表达的逻辑用DataFrame无法表达,所以后续提出了Dataset API,Dataset结合了RDD和DataFrame的好处。
3.3 Dataset
Dataset是Spark 1.6新添加的一个实验性接口,其目的是想结合RDD的好处(强类
型(这意味着可以在编译时进行类型安全检查)、可以使用强大的lambada函数)和SparkSQL的优化执行引擎的好处。可以从JVM对象构造出Dataset,然后使用类似于RDD的函数式转换算子(map/flatMap/filter等)对其进行操作。
Dataset通过Encoder实现了自定义的序列化格式,使得某些操作可以在无需序列化的情况下直接进行。另外Dataset还进行了包括Tungsten优化在内的很多性能方面的优化。
实际上Dataset是包含了DataFrame的功能的,这样二者就出现了很大的冗余,故Spark 2.0将二者统一:保留Dataset API,把DataFrame表示为Dataset[Row],即Dataset的子集。
3.4 API进化
Spark在迅速的发展,从原始的RDD API,再到DataFrame API,再到Dataset的出现,
执行性能上有了很大的提升。
我们在使用API时,应该优先选择DataFrames和Dataset,因为这二者的性能很好,而且以后的优化它都可以享受到,但是为了兼容早期版本的程序,RDD API也会一直保留着。后续Spark上层的库将全部会用DataFrames和Dataset,比如MLlib、Streaming、Graphx等。
3.5 SparkSQL的数据源
SparkSQL支持通过SchemaRDD接口操作各种数据源。一个SchemaRDD能够作为一个
一般的RDD被操作,也可以被注册为一个临时的表。注册一个SchemaRDD为一个表就可以允许你在其数据上运行SQL查询。
加载数据为SchemaRDD的多种数据源,包括RDDs、parquet文件(列式存储)、JSON数据集、Hive表,以下主要介绍将RDDs转换为schemaRDD的两种方法。
(1) 利用反射推断模式
使用反射来推断包含特定对象类型的RDD的模式(schema)。适用于写Spark程序的同
时,已经知道了模式,使用反射可以使得代码简洁。结合样本的名字,通过反射读取,作为列的名字。这个RDD可以隐式转化为一个schemaRDD,然后注册为一个表。表可以在后续的sql语句中使用。
val sqlContext = new org.apache.spark.sql.SQLContext(sc) import sqlContext.implicits._ case class Person(name:String,age:Int) val people = sc.textFile("file:///home/hdfs/people.txt").map(_.split(",")).map(p => Person(p(0),p(1).trim.toInt)).toDF() people.registerTempTable("people") val teenagers = sqlContext.sql("SELECT name,age FROM people WHERE age>= 19 AND age <=30") teenagers.map(t => "Name:"+t(0)).collect().foreach(println) teenagers.map(t => "Name:" + t.getAs[String]("name")).collect().foreach(println) teenagers.map(_.getValueMap[Any](List("name","age"))).collect().foreach(println) |
(2)编程指定模式
通过一个编程接口构造模式来实现,然后可在存在的RDDs上使用它。适用于当前样本模式未知一个SchemaRDD可以通过三步来创建。
Ø 从原来的RDD创建一个行的RDD
Ø 创建由一个StructType表示的模式与第一步创建的RDD的行结构相匹配
Ø 在行RDD上通过applySchema方法应用模式
val people = sc.textFile("file:///home/hdfs/people.txt") val schemaString = "name age" import org.apache.spark.sql.Row; import org.apache.spark.sql.types.{StructType,StructField,StringType}; val schema = StructType(schemaString.split(" ").map(fieldName => StructField(fieldName,StringType,true))) val rowRDD = people.map(_.split(",")).map(p => Row(p(0),p(1).trim)) val peopleSchemaRDD = sqlContext.applySchema(rowRDD,schema) peopleSchemaRDD.registerTempTable("people") val results = sqlContext.sql("SELECT name FROM people") //DataFrame and support all the normal RDD operations results.map(t => "Name:"+t(0)).collect().foreach(println) |
结果输出:
Name:Andy
Name:Justin
Name:JohnSmith
Name:Bob
4 运行框架
类似于关系型数据库,SparkSQL也是语句也是由Projection(a1,a2,a3)、Data Source(tableA)、Filter(condition)组成,分别对应sql查询过程中的Result、Data Source、Operation,也就是说SQL语句按Result-->DataSource-->Operation的次序来描述的。
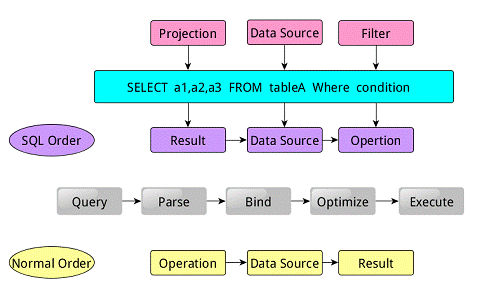
图4 SparkSQL运行顺序示意
当执行SparkSQL语句的顺序为:
1.对读入的SQL语句进行解析(Parse),分辨出SQL语句中哪些词是关键词(如SELECT、FROM、WHERE),哪些是表达式、哪些是Projection、哪些是Data Source等,从而判断SQL语句是否规范;
2.将SQL语句和数据库的数据字典(列、表、视图等等)进行绑定(Bind),如果相关的Projection、Data Source等都是存在的话,就表示这个SQL语句是可以执行的;
3.一般的数据库会提供几个执行计划,这些计划一般都有运行统计数据,数据库会在这些计划中选择一个最优计划(Optimize);
4.计划执行(Execute),按Operation-->DataSource-->Result的次序来进行的,在执行过程有时候甚至不需要读取物理表就可以返回结果,比如重新运行刚运行过的SQL语句,可能直接从数据库的缓冲池中获取返回结果。
4.1 tree和rule
SparkSQL对SQL语句的处理和关系型数据库对SQL语句的处理采用了类似的方法,首先会将SQL语句进行解析(Parse),然后形成一个Tree,在后续的如绑定、优化等处理过程都是对Tree的操作,而操作的方法是采用Rule,通过模式匹配,对不同类型的节点采用不同的操作。在整个sql语句的处理过程中,Tree和Rule相互配合,完成了解析、绑定(在SparkSQL中称为Analysis)、优化、物理计划等过程,最终生成可以执行的物理计划。
4.1.1 Tree
Tree的相关代码定义在sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees;
Logical Plans、Expressions、Physical Operators都可以使用Tree表示;
Tree的具体操作是通过TreeNode来实现的。
SparkSQL定义了catalyst.trees的日志,通过这个日志可以形象的表示出树的结构TreeNode可以使用scala的集合操作方法(如foreach, map, flatMap,collect等)进行操作有了TreeNode,通过Tree中各个TreeNode之间的关系,可以对Tree进行遍历操作,如使用transformDown、transformUp将Rule应用到给定的树段,然后用结果替代旧的树段;也可以使用transformChildrenDown、transformChildrenUp对一个给定的节点进行操作,通过迭代将Rule应用到该节点以及子节点。
TreeNode可以细分成三种类型的Node:
Ø UnaryNode 一元节点,即只有一个子节点。如Limit、Filter操作
Ø BinaryNode 二元节点,即有左右子节点的二叉节点。如Jion、Union操作
Ø LeafNode 叶子节点,没有子节点的节点。主要用户命令类操作,如SetCommand
4.1.2 Rule
Ø Rule的相关代码定义在sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/rules
Ø Rule在SparkSQL的Analyzer、Optimizer、SparkPlan等各个组件中都有应用到
Ø Rule是一个抽象类,具体的Rule实现是通过RuleExecutor完成
Ø Rule通过定义batch和batchs,可以简便的、模块化地对Tree进行transform操作
Ø Rule通过定义Once和FixedPoint,可以对Tree进行一次操作或多次操作(如对某些Tree进行多次迭代操作的时候,达到FixedPoint次数迭代或达到前后两次的树结构没变化才停止操作,具体参看RuleExecutor.apply)
4.2 Context运行过程
SparkSQL有两个分支,sqlContext和hiveContext,sqlContext现在只支持SQL语法解析器(SQL-92语法);hiveContext现在支持SQL语法解析器和hivesql语法解析器,默认为hiveSQL语法解析器,用户可以通过配置切换成SQL语法解析器,来运行hiveSQL不支持的语法。
4.2.1 sqlContext运行过程
sqlContext总的一个运行过程如下图4所示:
1.SQL语句经过SqlParse解析成UnresolvedLogicalPlan;
2.使用analyzer结合数据数据字典(catalog)进行绑定,生成resolvedLogicalPlan;
3.使用optimizer对resolvedLogicalPlan进行优化,生成optimizedLogicalPlan;
4.使用SparkPlan将LogicalPlan转换成PhysicalPlan;
5.使用prepareForExecution()将PhysicalPlan转换成可执行物理计划;
6.使用execute()执行可执行物理计划;
7.生成SchemaRDD。
在整个运行过程中涉及到多个SparkSQL的组件,如SqlParse、analyzer、optimizer、SparkPlan等等。
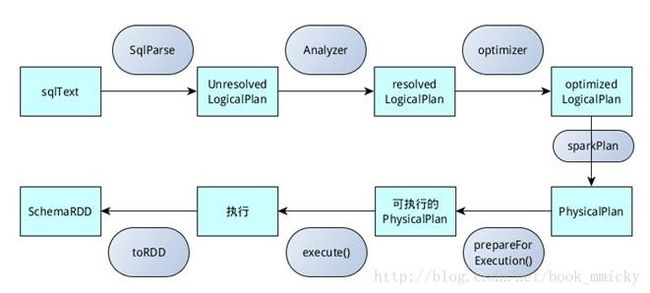
图5 sqlContext运行过程
4.2.2 hiveContext运行过程
hiveContext总的一个运行过程如下图5所示:
1.SQL语句经过HiveQl.parseSql解析成Unresolved LogicalPlan,在这个解析过程中对hiveql语句使用getAst()获取AST树,然后再进行解析;
2.使用analyzer结合数据hive源数据Metastore(新的catalog)进行绑定,生成resolved LogicalPlan;
3.使用optimizer对resolved LogicalPlan进行优化,生成optimized LogicalPlan,优化前使用了ExtractPythonUdfs(catalog.PreInsertionCasts(catalog.CreateTables(analyzed)))进行预处理;
4.使用hivePlanner将LogicalPlan转换成PhysicalPlan;
5.使用prepareForExecution()将PhysicalPlan转换成可执行物理计划;
6.使用execute()执行可执行物理计划;
7.执行后,使用map(_.copy)将结果导入SchemaRDD。
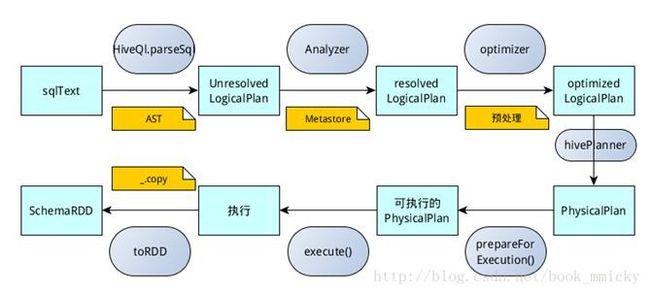
图6 hiveContext运行过程
4.3 Catalyst优化器
SparkSQL1.1总体上由四个模块组成:core、catalyst、hive、hive-Thriftserver:
Ø core处理数据的输入输出,从不同的数据源获取数据(RDD、Parquet、json等),将查询结果输出成schemaRDD;
Ø catalyst处理查询语句的整个处理过程,包括解析、绑定、优化、物理计划等,说其是优化器,还不如说是查询引擎;
Ø hive对hive数据的处理;
Ø hive-ThriftServer提供CLI和JDBC/ODBC接口。
在这四个模块中,catalyst处于最核心的部分,其性能优劣将影响整体的性能。由于发展时间尚短,还有很多不足的地方,但其插件式的设计,为未来的发展留下了很大的空间。图6是catalyst的一个设计图:
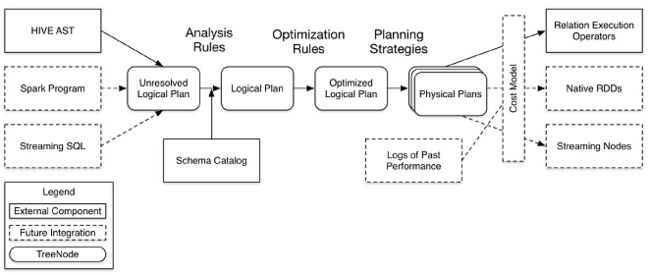
图7 catalyst示意图
4.4 SparkSQL CLI
CLI(Command-Line Interface,命令行界面)是指可在用户提示符下键入可执行指令的界面,它通常不支持鼠标,用户通过键盘输入指令,计算机接收到指令后予以执行。Spark CLI指的是使用命令界面直接输入SQL命令,然后发送到Spark集群进行执行,在界面中显示运行过程和最终的结果。
Spark1.1相较于Spark1.0最大的差别就在于Spark1.1增加了Spark SQL CLI和ThriftServer,使得Hive用户还有用惯了命令行的RDBMS数据库管理员较容易地上手,真正意义上进入了SQL时代。
5 使用方法
SparkSQL的具体用法可以分为种:
Ø 使用RDD编程的方式(spark-shell或者直接编写代码)
Ø SparkSQL提供的CLI(spark-sql)
5.1 编程方式
可以使用spark-shell的方式或者直接编写代码的方式来实现,二者的区别想必大家都应晓得,下面简单介绍一下这种方式。
编程语言支持java、scala、python和R,我们可以在spark的程序中使用SQL语句或者DataFrame API来对结构化的数据进行操作。
5.1.1 入口SQLContext
Spark SQL程序的主入口是SQLContext类或它的子类。创建一个基本的SQLContext,你只需要SparkContext,创建代码示例如下:
val val import sqlContext.implicits._ //this is to implicitly convert an RDD to a DataFrame |
除了基本的SQLContext,也可以创建HiveContext。SQLContext和HiveContext区别与联系为:
Ø SQLContext现在只支持SQL语法解析器(SQL-92语法)
Ø HiveContext现在支持SQL语法解析器和HiveSQL语法解析器,默认为HiveSQL语法解析器,用户可以通过配置切换成SQL语法解析器,来运行HiveSQL不支持的语法。
Ø 使用HiveContext可以使用Hive的UDF,读写Hive表数据等Hive操作。SQLContext不可以对Hive进行操作。
Ø Spark SQL未来的版本会不断丰富SQLContext的功能,做到SQLContext和HiveContext的功能容和,最终可能两者会统一成一个Context
HiveContext包装了Hive的依赖包,把HiveContext单独拿出来,可以在部署基本的Spark
的时候就不需要Hive的依赖包,需要使用HiveContext时再把Hive的各种依赖包加进来。
SQL的解析器可以通过配置spark.sql.dialect参数进行配置。在SQLContext中只能使用Spark SQL提供的”sql“解析器。在HiveContext中默认解析器为”hiveql“,也支持”sql“解析器。官方建议我们使用hiveql,因为它更全面,适用面更广。
在我们目前的环境中使用的是HDP提供的二进制包,默认已经在编译的时候将Hive和Hive的各种依赖都包含在内了,这个可以查看Spark的lib目录下是否有下列三个jar包以及Spark的conf目录下是否有hive-site.xml来判定:
| [root@node8 opt]# ls /usr/hdp/2.4.2.0-258/spark/lib/ datanucleus-api-jdo-3.2.6.jar hbase-server-1.1.2.2.4.2.0-258.jar datanucleus-core-3.2.10.jar hive-hbase-handler-1.2.1000.2.4.2.0-258.jar datanucleus-rdbms-3.2.9.jar htrace-core-3.1.0-incubating.jar guava-12.0.1.jar spark-1.6.1.2.4.2.0-258-yarn-shuffle.jar hbase-client-1.1.2.2.4.2.0-258.jar spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar hbase-common-1.1.2.2.4.2.0-258.jar spark-examples-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar hbase-common-1.1.2.2.4.2.0-258-tests.jar spark-hdp-assembly.jar hbase-protocol-1.1.2.2.4.2.0-258.jar |
| [root@node8 opt]# ls /usr/hdp/2.4.2.0-258/spark/conf/ core-site.xml fairscheduler.xml.template hive-site.xml metrics.properties spark-defaults.conf derby.log hbase-site.xml log4j.properties metrics.properties.template spark-defaults.conf.template docker.properties.template hdfs-site.xml log4j.properties.template slaves.template spark-env.sh |
我们在实际的Spark编程中如果使用了HiveContext只需要在build.sbt文件中的libraryDependencies ++依赖项上加上"org.apache.spark" %"spark-hive_2.10" % "1.6.1" % "provided"即可。
如果是自己使用Spark源码编译获得的Spark包,可能需要重新编译Spark加上Hive和Hive依赖了,编译命令:build/sbt–Phive –Phive-thriftserver assembly,这种方式没有进行实际测试过。
5.1.2 创建DataFrame
使用SQLContext,spark应用程序(Application)可以通过RDD、Hive表、JSON格式数据等数据源创建DataFrames。下面是基于JSON文件创建DataFrame的示例:
val sc: SparkContext // An existing SparkContext. val sqlContext = new org.apache.spark.sql.SQLContext(sc) val df = sqlContext.read.json("examples/src/main/resources/people.json") // Displays the content of the DataFrame to stdout df.show() |
5.1.3 DataFrame操作
DataFrames支持Scala、Java和Python的操作接口。下面是Scala和Java的几个操作示例:
val sc: SparkContext // An existing SparkContext. val sqlContext = new org.apache.spark.sql.SQLContext(sc) // Create the DataFrame val df = sqlContext.read.json("examples/src/main/resources/people.json") // Show the content of the DataFrame df.show() // age name // null Michael // 30 Andy // 19 Justin // Print the schema in a tree format df.printSchema() // root // |-- age: long (nullable = true) // |-- name: string (nullable = true) // Select only the "name" column df.select("name").show() // name // Michael // Andy // Justin |
详细的DataFrame API请参考 APIDocumentation。除了简单列引用和表达式,DataFrames还有丰富的library,功能包括string操作、date操作、常见数学操作等。详细内容请参考DataFrameFunction Reference。
5.1.4 运行SQL查询程序
SparkApplication可以使用SQLContext的sql()方法执行SQL查询操作,sql()方法返回的查询结果为DataFrame格式。代码如下:
val sqlContext = ... // An existing SQLContext val df = sqlContext.sql("SELECT * FROM table") |
关于编程的话还有其他许多内容,例如RDDs和DataFrames之间的转换,获取各种数据源、结果的保存和调优等内容,具体的可以查阅官网资料。
5.2 CLI方式
SparkSQL提供了CLI接口spark-sql,用户可以直接在cli上使用SQL语言或者HQL对database中的数据进行各种操作。这种方法的话目前本人测试过,利用hive或者spark-sql读取hbase数据的方法,下面就介绍一下这部分的内容。
5.2.1 外部表
Hbase中表T1内容(节选):
| hbase(main):003:0> scan 'T1' ROW COLUMN+CELL 000000000001 column=f:data, timestamp=1476927339446, value=6 000000000001 column=f:dst, timestamp=1476927339446, value=339005197502169411 000000000001 column=f:src, timestamp=1476927339446, value=330121197306198511 000000000002 column=f:data, timestamp=1476927339446, value=4 000000000002 column=f:dst, timestamp=1476927339446, value=339005199403297927 000000000002 column=f:src, timestamp=1476927339446, value=339005198607198512 000000000003 column=f:data, timestamp=1476927339446, value=3 000000000003 column=f:dst, timestamp=1476927339446, value=330903198802102510 000000000003 column=f:src, timestamp=1476927339446, value=330281198904252211 |
下面所做的工作就是在SparkSQL中创建一个外部表,与hbase中表对应,然后再SparkSQL中的操作结果会影响到hbase中的表。拷贝HBase的相关jar包到Spark节点上的$SPARK_HOME/lib目录下,清单如下:
| guava-14.0.1.jar htrace-core-3.1.0-incubating.jar hbase-common-1.1.2.2.4.2.0-258.jar hbase-common-1.1.2.2.4.2.0-258-tests.jar hbase-client-1.1.2.2.4.2.0-258.jar hbase-server-1.1.2.2.4.2.0-258.jar hbase-protocol-1.1.2.2.4.2.0-258.jar hive-hbase-handler-1.2.1000.2.4.2.0-258.jar |
在 ambari 上配置Spark节点的$SPARK_HOME/conf/spark-env.sh,将上面的jar包添加到SPARK_CLASSPATH,如下图:
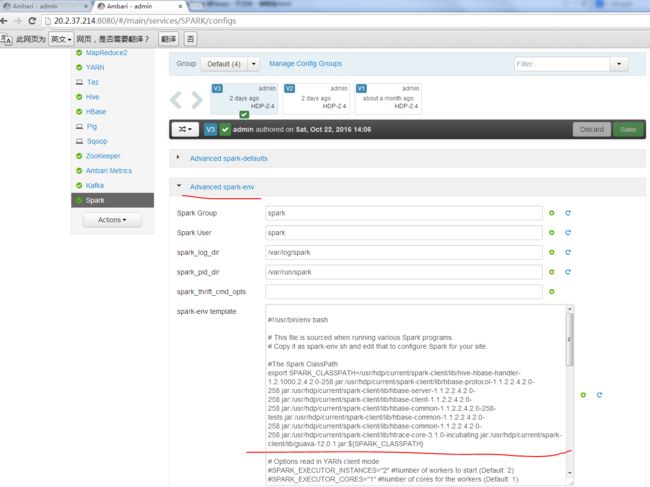
图8 spark依赖jar包配置
| #The Spark ClassPath export SPARK_CLASSPATH=/usr/hdp/current/spark-client/lib/hive-hbase-handler-1.2.1000.2.4.2.0-258.jar:/usr/hdp/current/spark-client/lib/hbase-protocol-1.1.2.2.4.2.0-258.jar:/usr/hdp/current/spark-client/lib/hbase-server-1.1.2.2.4.2.0-258.jar:/usr/hdp/current/spark-client/lib/hbase-client-1.1.2.2.4.2.0-258.jar:/usr/hdp/current/spark-client/lib/hbase-common-1.1.2.2.4.2.0-258-tests.jar:/usr/hdp/current/spark-client/lib/hbase-common-1.1.2.2.4.2.0-258.jar:/usr/hdp/current/spark-client/lib/hbase-common-1.1.2.2.4.2.0-258.jar:/usr/hdp/current/spark-client/lib/htrace-core-3.1.0-incubating.jar:/usr/hdp/current/spark-client/lib/guava-12.0.1.jar:${SPARK_CLASSPATH} |
将hbase-site.xml拷贝至${HADOOP_CONF_DIR},由于 spark-env.sh中配置了Hadoop配置文件目录${HADOOP_CONF_DIR},因此会将hbase-site.xml加载,另外将hive-site.xml拷贝至Spark的conf目录下,SparkSQL就能使用Hive数据仓库中的内容。
最后在ambari上重启修改配置后影响的组件。
在命令行上输入spark-sql(具体参数和用法可以通过spark-sql –help来查看),进入sparkSQL的cli接口,创建外部表:
| spark-sql> > create external table T1(id int, src string, data int, dst string) > STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' > WITH SERDEPROPERTIES("hbase.columns.mapping" = ":key,f:src,f:data,f:dst") > TBLPROPERTIES("hbase.table.name" = "T1"); OK Time taken: 2.164 seconds spark-sql>show tables; c_picrecord false gou false new_table false src false t1 false wenjf false Time taken: 0.076 seconds, Fetched 6 row(s) |
这里就建立了一个与hbase中表T1对应的外部t1。
注意spark中创建后的表名均为小写,使用的是hive的类org.apache.hadoop.hive.hbase.HBaseStorageHandler(这里稍后会做解释)。
对t1进行各种sql操作:
| > select * from t1; 1 330121197306198511 6 339005197502169411 2 339005198607198512 4 339005199403297927 3 330281198904252211 3 330903198802102510 ... 44 339005198803019411 1 413021198302102916 45 330121196604309115 1 339005199008209413 46 339005198108280378 1 433030196905291411 47 330121197209189410 1 339005199403297927 Time taken: 0.514 seconds, Fetched 47 row(s) |
其实t1表相当于hbase中T1的一个软链接,在hive的hdfs目录(/apps/hive/warehouse/t1)下并没有实际的内容,它的实际内容保存在hbase的对应hdfs目录上。
5.2.2 内部表
Spark-sql直接建表load本地文件系统(并不是hdfs)上的数据。
在/opt目录下有文本文件people.txt,具体内容如下:
| zhangxin 25 wanglong 28 wangjing 28 huangwenjin 30 wenjianfeng 26 wuchao 26 wendeyang 27 |
在sparksql中建立一个内部表,表的内容就是上面的文本文件。
| > create table people(name string, age int)row format delimited fields terminated by '\t' lines terminated by '\n' > stored as textfile ; OK Time taken: 1.009 seconds > load data local inpath '/opt/people.txt' overwrite into table people; OK Time taken: 1.009 seconds > show tables; c_picrecord false gou false new_table false people false src false t1 false wenjf false > select * from people; Zhangxin 25 Wangling 28 wangjing 28 huangwenjin 30 wenjianfeng 26 wuchao 26 wendeyang 27 Time taken: 0.228 seconds, Fetched 7 row(s) |
注意本地文件的格式(符合txt文件格式如‘\t’‘\n’等),这种方式建立的表是内部表。具体内容保存在hdfs上。
org.apache.hadoop.hive.ql.lockmgr.DummyTxnManager
5.2.3 Hive增删改
经过亲测,对于数据的增删改操作在hive的CLI上能够实现,SparkSQL的CLI上不知道是兼容性的问题还是语法的问题,暂时未能实现。
(1)配置
需要更改一些配置使得Hive支持增删改操作,也可以在hive的CLI中直接使用set操作赋值:
| Hive.support.concurrency=true Hive.enforce.bucketing=true Hive.exec.dynamic.partition.mode=nonstrict Hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager Hive.compactor.initiator.on=true Hive.compactor.worker.threads=1 |
上述配置在ambari的hive配置项中修改之后重启hive的metastore服务。
(2)插入数据
新建了一个空表,分区2个buckets,update/delete操作对表有限制需要分桶。
| hive> create table person(age int, name string) clustered by (age) into 2 buckets stored as orc tblproperties('transactional'='true'); OK Time taken: 0.624 seconds |
建表语句在sparkSQL的CLI上也可以正确运行。
(3)插入操作
插入1,“aaa”,MR操作。
| > insert into person values (1,'aaa'); Query ID = root_20161025113224_f4c66cec-9e0a-491a-bb00-430d823f703f Total jobs = 1 Launching Job 1 out of 1
Status: Running (Executing on YARN cluster with App id application_1474288351051_0380)
-------------------------------------------------------------------------------- VERTICES STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED -------------------------------------------------------------------------------- Map 1 .......... SUCCEEDED 1 1 0 0 0 0 Reducer 2 ...... SUCCEEDED 2 2 0 0 0 0 -------------------------------------------------------------------------------- VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 9.25 s -------------------------------------------------------------------------------- Loading data to table default.person Table default.person stats: [numFiles=2, numRows=1, totalSize=842, rawDataSize=0] OK Time taken: 11.366 seconds |
同样的插入语句在SparkSQL上无法运行:
| spark-sql> > insert into ppp values (1,'aaa'); 16/10/25 14:23:35 INFO ParseDriver: Parsing command: insert into ppp values (1,'aaa') 16/10/25 14:23:35 INFO ParseDriver: Parse Completed 16/10/25 14:23:35 INFO ParseDriver: Parsing command: insert into ppp values (1,'aaa') 16/10/25 14:23:35 INFO ParseDriver: Parse Completed Error in query: Unsupported language features in query: insert into ppp values (1,'aaa') TOK_QUERY 0, 0,12, 0 TOK_FROM 0, -1,12, 0 TOK_VIRTUAL_TABLE 0, -1,12, 0 TOK_VIRTUAL_TABREF 0, -1,-1, 0 TOK_ANONYMOUS 0, -1,-1, 0 TOK_VALUES_TABLE 1, 6,12, 24 TOK_VALUE_ROW 1, 8,12, 24 1 1, 9,9, 24 'aaa' 1, 11,11, 26 TOK_INSERT 1, 0,-1, 12 TOK_INSERT_INTO 1, 0,4, 12 TOK_TAB 1, 4,4, 12 TOK_TABNAME 1, 4,4, 12 ppp 1, 4,4, 12 TOK_SELECT 0, -1,-1, 0 TOK_SELEXPR 0, -1,-1, 0 TOK_ALLCOLREF 0, -1,-1, 0
scala.NotImplementedError: No parse rules for: TOK_VIRTUAL_TABLE 0, -1,12, 0 TOK_VIRTUAL_TABREF 0, -1,-1, 0 TOK_ANONYMOUS 0, -1,-1, 0 TOK_VALUES_TABLE 1, 6,12, 24 TOK_VALUE_ROW 1, 8,12, 24 1 1, 9,9, 24 'aaa' 1, 11,11, 26
org.apache.spark.sql.hive.HiveQl$.nodeToRelation(HiveQl.scala:1362) ; |
暂时没有深入研究,可能是不兼容的问题。
(4)更新操作
更新之前插入的那条记录的name域aaa=>bbb。
| > update person set name='bbb' where age=1; Query ID = root_20161025113323_b33608d6-2558-478b-a45c-4f7aa99e6c62 Total jobs = 1 Launching Job 1 out of 1
Status: Running (Executing on YARN cluster with App id application_1474288351051_0380)
-------------------------------------------------------------------------------- VERTICES STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED -------------------------------------------------------------------------------- Map 1 .......... SUCCEEDED 1 1 0 0 0 0 Reducer 2 ...... SUCCEEDED 2 2 0 0 0 0 -------------------------------------------------------------------------------- VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 10.50 s -------------------------------------------------------------------------------- Loading data to table default.person Table default.person stats: [numFiles=3, numRows=1, totalSize=1484, rawDataSize=0] OK Time taken: 13.886 seconds |
类似语句也无法在SparkSQL上的CLI运行。
(5)删除操作
删除表中的一条记录。
| hive> delete from person where age=1; Query ID = root_20161025135703_699772fe-fe6a-4272-8f93-31a8a3c95fe1 Total jobs = 1 Launching Job 1 out of 1 Tez session was closed. Reopening... Session re-established.
Status: Running (Executing on YARN cluster with App id application_1474288351051_0381)
-------------------------------------------------------------------------------- VERTICES STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED -------------------------------------------------------------------------------- Map 1 .......... SUCCEEDED 1 1 0 0 0 0 Reducer 2 ...... SUCCEEDED 2 2 0 0 0 0 -------------------------------------------------------------------------------- VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 10.85 s -------------------------------------------------------------------------------- Loading data to table default.person Table default.person stats: [numFiles=4, numRows=0, totalSize=2016, rawDataSize=0] OK Time taken: 20.584 seconds |
类似语句也无法在SparkSQL上的CLI运行。
5.2.4 总结
其实这上面运行的语句中很大一部分都是hive语句,在hive上面也能照常运行,在Sparksql上运行时调用的也是hive提供的方法,例如前面提到的org.apache.hadoop.hive.hbase.HBaseStorageHandler和下面红字标注的部分:
| > load data local inpath '/opt/people.txt' overwrite into table people; 16/10/24 16:52:54 INFO ParseDriver: Parsing command: load data local inpath '/opt/people.txt' overwrite into table people 16/10/24 16:52:54 INFO ParseDriver: Parse Completed 16/10/24 16:52:54 INFO PerfLogger: 16/10/24 16:52:54 INFO PerfLogger: 16/10/24 16:52:54 INFO PerfLogger: 16/10/24 16:52:54 INFO PerfLogger: 16/10/24 16:52:54 INFO ParseDriver: Parsing command: load data local inpath '/opt/people.txt' overwrite into table people 16/10/24 16:52:54 INFO ParseDriver: Parse Completed |
以上说明sparkSQL与hive可以相互共存,SparkSQL兼容了Hive的许多功能,SparkSQL可以直接构建在Hive数据仓库之上。但是二者实际使用中的性能表现有着较大的区别,这里举个很简单的例子,具体如下:
在同一个数据仓库下(其他环境也都相同)使用sql语句的对比:
| Hive: hive> select min(data) from gou; Query ID = root_20161024195350_0cc8b723-3f06-41d8-ab3a-c874df38c4ec Total jobs = 1 Launching Job 1 out of 1
Status: Running (Executing on YARN cluster with App id application_1474288351051_0378)
-------------------------------------------------------------------------------- VERTICES STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED -------------------------------------------------------------------------------- Map 1 .......... SUCCEEDED 1 1 0 0 0 0 Reducer 2 ...... SUCCEEDED 1 1 0 0 0 0 -------------------------------------------------------------------------------- VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 6.71 s -------------------------------------------------------------------------------- OK 11 Time taken: 9.392 seconds, Fetched: 1 row(s) |
以上是hive的运行结果,它在yarn集群上使用mapreduce来实现。
| SparkSQL: > select min(data) from gou; 11 Time taken: 0.568 seconds, Fetched 1 row(s) |
SparkSQL使用Spark作为运算的引擎,本例的话是采用local的模式运行的,在性能上比Hive优秀。
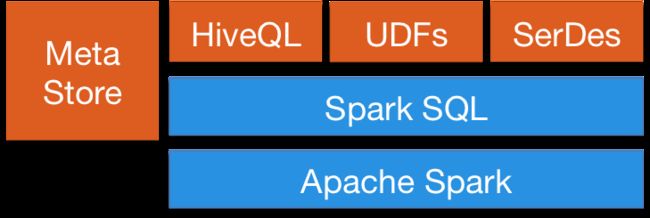
图9 SparkSQL与HiveQL
由图8可知,SparkSQL可以直接使用环境中已有的Hive MetaStore、UDFs和SerDes数据。
6 附录
参考资料:
Spark入门实战系列--6.SparkSQL(上)--SparkSQL简介 - shishanyuan - 博客园
Spark SQL 官方文档-中文翻译 - BYRans - 博客园
Hive 数据导入HBase的2种方法详解 - 王建奎Jerrick的个人页面 - 开源中国社区