AXI协议中的模棱两可的含义的解释
Cachable和bufferable
一个Master发出一个读写的request,中间要经过很多Buffer,最后才能送到memory。这些Buffer的添加是为了outstanding,timing,performance等。
bufferable
Buffer有两种类型:一种FIFO结构,仅仅就是保存发送Request给下一级或者返回Response给上一级。还有一种Buffer,在接受了上一级的Request之后立刻给上一级回response,告诉上一级这个操作已经做完了,而实际上这个操作并没有发到下一级Buffer,更没有被送到memory。有的人可能就问,write的时候这样可以,read的时候则无法这么做。其实read一样有bufferable,如果此处buffer的write data channel有此read需要的数据,就可以直接返回,而不用去访问memory,如果没有,则要把Request发到下一级。
总之,所以的访问都要经过这些buffer,是否bufferable在于何时由谁回response,在于是否要把request送到最终的memory。
Cacheable:
Interconnect其实只是一个路由的功能,内部有buffer,但并没有cache。而是在这个访问从Master发起request到送到最终的memory这个过程中,可能会经过一些cache,cacheable代表了是不是要去这个cache中查找自己需要的数据。要不要更新cache。
你说的利用cache来提高性能,有些操作是要求绝对non-cacheable的,比如device 内部寄存器的访问,这些都是MMR。只能使用non-cachable。
AXI 五个channel所有的信号,可以是Master-Interconnect,也可以是Interconnect-Slave,也可以直接是Master-Slave。
outstanding 乱序与穿插
简单讲,如果没有outstanding,或者说outstanding能力为1,则AXI Master的行为如下:
读操作:读地址命令->等待读数据返回->读地址命令->等待读数据返回->读地址命令->等待读数据返回。。。。。
写操作:写地址命令->写数据->等待写响应返回->写地址命令->写数据->等待写响应返回。。。。。(如果支持out-of-order,对于AXI3,写命令和写数据不一定有先后顺序且ID顺序不一定相同,AXI4因为已经没有WID信号,所以写数据的顺序要和写地址的顺序一样)
而如果outstanding能力为N>1的话,则:
读操作:可以连续发N个读地址命令,这期间如果读数据没有返回,则需要需要等待读数据返回,如果有读数据返回,则返回了几个,那么仍然可以接着发几个。也就是说,“在路上” 的读命令(或者读数据)最多可以是N。多说一点,可以看出,如果数据返回得比较慢,那么IP需要等待,效率就会比较低,因此,为了提高效率,有必要提高outstanding能力,以弥补”路上“(总线)引入的延时。但是也不能无限制地发,有可能会引起总线拥塞,把其他IP给堵住。
写操作:可以连续发出N组写地址(写数据)命令,这期间如果写响应没有返回,则必须等待写响应返回才能接着发写地址(写数据)命令,如果有写响应返回,则返回了几个,那么仍然可以接着发几组。也就是说,“在路上” 的写响应最多可以是N。
out of order 和interleave
乱序和间插是两个完全不同的概念。笼统的说,乱序指的是burst这个粒度,而间插指的是beat这个粒度。
简单说了,乱序是salve返回master请求的out of order特性,但这个slave可以是广义上的,一般总线会完成这个功能;而间插(interleave)是指写数据,或是读返回数据,按找不同ID交织出现。比如:ID0 ID1 ID0 ID1…。乱序和间插都有深度,一般乱序深度比间插大的多。上面那个例子就是间插深度为2的情况。
exclusive 和lock
- 首先,Lock在amba2.0中就有涉及,意思是,某个master 可以通过Lock 总线来实现独占。只有当该master完成传输后才释放出总线。这样的话,总线的效率会降低。 2. 相比Lock,AXI 中引入了exclusive操作,不需要将bus锁定给某个master。而是通过TAG ID以及slave 返回的response来判断当前的传输是否成功。过程如下:
1)mst 首先向slave的某个地址位置发起一个exclusive读操作。slave中的monitor会纪录下该mst的 ARID和 要访问的地址位置(返回EXOKEY)。
2)mst向同一地址区域发起一exclusive写操作。slave同样要记录该操作的mst的 AWID 和 要访问的地址位置。如果AWID==ARID && 该地址内容没有改变(没有 其他的mst访问过),这个写操作就是成功的。该地址就会更新,同时slv会返回EXOKEY. 否则,slv会返回OKEY.
由此看来,对于exclusive操作,总线其实允许其他mst同时来请求总线。比如,当其他mst要同时通过总线访问其他的slv时,上述2)就不满足,所以总线就不会被锁定
outstanding and out-of-order
Ordering model
AXI的控制和数据通道分离,可以带来很多好处。地址和控制信息相对数据的相位独立,可以先发地址,然后再是数据,这样自然而然的支持显著操作,也就是 outstanding 操作。Master访问slave的时候,可以不等需要的操作完成,就发出下一个操作。这样,可以让slave在控制流的处理上流水起来,达到提速的作 用。同时对于master,也许需要对不同的地址和slave就行访问,所以可以对不同的slave 连续操作。而这样的操作,由于slave 返回数据的先后可能不按照master 发出控制的先后进行,导致出现了乱序操作(out of order )。
先看下ordering model的几个概念:
Outstanding
The ability to issue multiple outstanding addresses means that masters can issue transaction addresses without waiting for earlier transactions to complete. This featurecan improve system performance because it enables parallel processing of transactions.
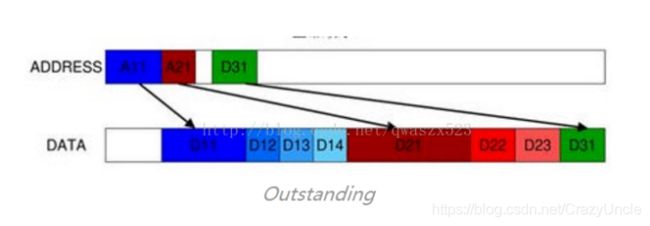
发出A11的addr后,在完成D11~D14的transfer之前,发出A21叫做outstanding。
Out-of-order : The ability to complete transactions out of order means that transactions to faster memory regions can complete without waiting for earlier transactions to slower memory regions. This feature can also improve system performance because it reducesthe effect of transaction latency.
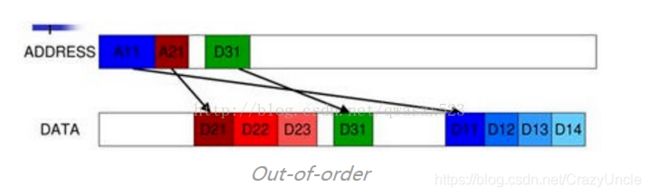
地址的顺序是A11,A21,A31,而数据顺序则可能是D2?,D3?,D1?,这个过程叫做Out-of-order
Interleaving: Write data interleaving enables a slave interface to accept interleaved write data withdifferent AWID values. The slave declares a write data interleaving depth that indicatesif the interface can accept interleaved write data from sources with different AWIDvalues.
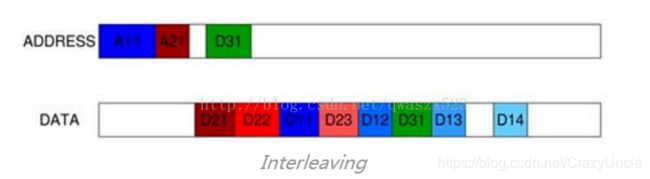
D11和D12之间插入D23,叫做interleaving。
简单而言,outsatanding是对地址而言,一次burst还没结束,就可以发送下一相地址。而out-of-order和interleaving则是相对于 transaction,out-of-order说的是发送transaction和接收的cmd之间的顺序没有关系,如先接到A的cmd,再接到B的cmd,则可以先发B的data,再发A的data;interleaving指的是A的data和B的data可以交错,如A1 B1 A2 B2 B3……
举个例子,从master和slave两个角色分别来看:
对于AXI master,先看写操作。如果分别发出WCMD1和WCMD2两个写命令给两个不同的slave,假设这两个写命令都是四拍的数据分别记为WDATA1_0,WDATA1_1,WDATA1_2,WDATA1_3,以及WDATA2_0,WDATA2_1,WDATA2_2,WDATA2_3。如果master在自己的写数据总线上,依次发出WDATA2_0,WDATA2_1,WDATA2_2,WDATA2_3,WDATA1_0,WDATA1_1,WDATA1_2,WDATA1_3,这就叫写out of order;如果master在自己的写数据总线上,依次发出WDATA2_0,WDATA1_0,WDATA2_1,WDATA1_1,WDATA2_2,WDATA2_3,WDATA1_2,WDATA1_3,这就叫写out of order且interleave;注意,不论是out of order还是interleave,同一个命令对应的四拍数据在内部必须是顺序的,不能乱序。比如,不允许出现WDATA2_1,WDATA1_0,WDATA2_0,WDATA1_1,WDATA2_2,WDATA2_3,WDATA1_2,WDATA1_3这样的。显然,你自己设计master时,如果是写操作,你不会主动发出out of oder和interleave的操作,因为这个明显增加了复杂度且没带来master自己的效率提高。再看master读,同样发出RCMD1和RCMD2两个读命令给不同的slave,由于不同slave的响应速度不同,就可能出现RCMD2对应的读数据先返回到master的情况;再考虑到复杂系统的总线设计,master依次接收到RDATA2_0,RDATA1_0,RDATA1_1,RDATA1_2,RDATA2_1,RDATA2_2,RDATA1_3,RDATA2_3这样的数据是有可能的,这就是读的out of order且interleave。所以,对于master,不建议发出out of order与interleave的写数据,但是必须支持out of order与interleave的读操作!同理,可以分析,对于slave,必须支持out of order与interleave的写操作,不建议返回out of order与interleave的读数据。在一个系统中,interleave会明显增加设计复杂度,其实可以约定master,slave以及连接总线都不要使用interleave,(另外可以配置depth ==1,达到不支持interleaving的目的)这样可以降低复杂度,但out of order是AXI特性,这个功能必须支持。