cache原理介绍
对于这么经典的东西,我还是引用ARM工程师的书籍吧,免得误人子弟。
cache以及write buffer的介绍
A cache is a small, fast array of memory placed between the processor core and main
memory that stores portions of recently referenced main memory. The processor uses
cachememory instead ofmainmemory whenever possible to increase systemperformance.
The goal of a cache is to reduce the memory access bottleneck imposed on the processor
core by slow memory.
Often used with a cache is a write buffer—a very small ?rst-in-?rst-out (FIFO) memory
placed between the processor core and main memory. The purpose of a write buffer is to
free the processor core and cache memory from the slow write time associated with writing
to main memory.
cache是否有效以及使能等造成的后果
The basic unit of storage in a cache is the cache line. A cache line is said to be valid when it contains cached
data or instructions, and invalid when it does not. All cache lines in a cache are invalidated on reset. A cache
line becomes valid when data or instructions are loaded into it from memory.
When a cache line is valid, it contains up-to-date values for a block of consecutive main memory locations.
The length of a cache line is always a power of two, and is typically in the range of 16 to 64 bytes. If the
cache line length is 2L bytes, the block of main memory locations is always 2L-byte aligned. Because of this
alignment requirement, virtual address bits[31:L] are identical for all bytes in a cache line
cache所在的位置

——————————————————————————————————————————
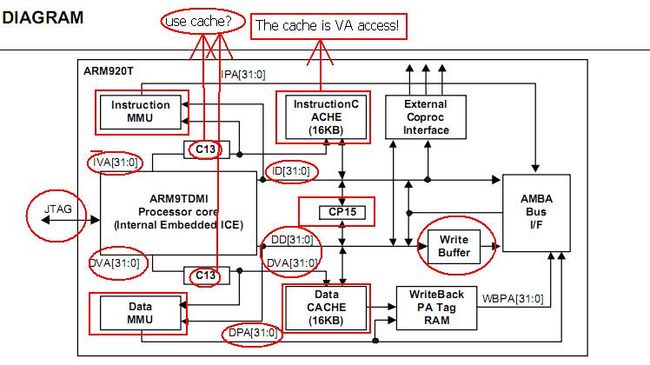
由此可知,cache是可以选择不同位置的,分为物理和虚拟/逻辑类型,但是对于2440是逻辑cache的,请看下图
++++++++++++++++++++++++++++++++++++++==========================================+++++++++++++++++
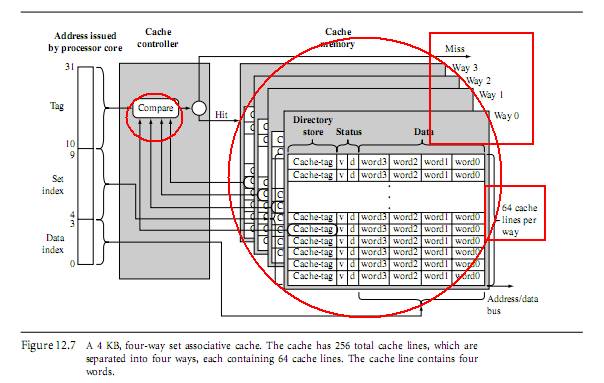
多路cache(单一cache效率很低,不做介绍)
____________________________________________________________________________________________
Tag对应内存中数据的位置,status有两位,一位是有效位(表示所在cache行是否有激活),另外一位
是脏位(判断cache中的内容和内存中的内容是否一致:注意不一致一定要想办法一致,否则后患无穷)
===================================================================================
现在来看看和2440靠谱的文档吧(ARM920T)
=====ICache=====
The ARM920T includes a 16KB ICache. The ICache has 512 lines of 32 bytes (8 words), arranged as a 64-way set-associative cache and uses MVAs, translated by CP15 register 13 (see Address translation on page 3-6), from the ARM9TDMI core.The ICache implements allocate-on-read-miss. Random or round-robin replacement can be selected under software control using the RR bit (CP15 register 1, bit 14). Random replacement is selected at reset.Instructions can also be locked in the ICache so that they cannot be overwritten by a linefill. This operates with a granularity of 1/64th of the cache, which is 64 words (256 bytes).All instruction accesses are subject to MMU permission and translation checks. Instruction fetches that are aborted by the MMU do not cause linefills or instruction fetches to appear on the AMBA ASB interface.
Note
————————————————————
For clarity, the I bit (bit 12 in CP15 register 1) is called the Icr bit throughout the
following text. The C bit from the MMU translation table descriptor corresponding to
the address being accessed is called the Ctt bit.
ICache organization(ICache 操作)
——————————————————————————————————————————————————
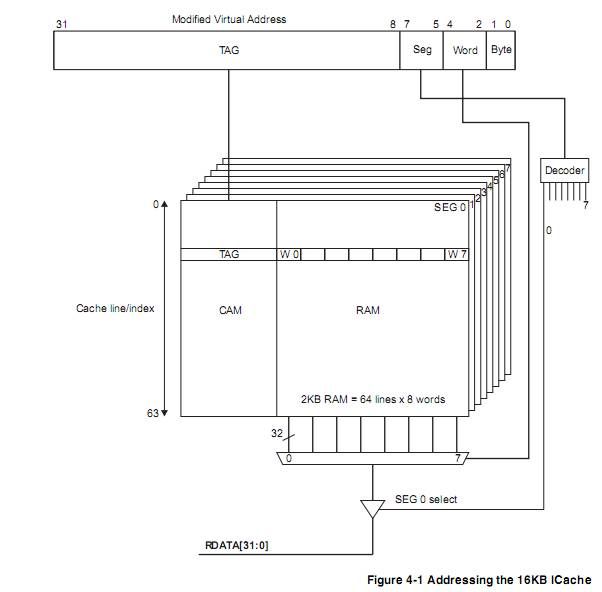
The ICache is organized as eight segments, each containing 64 lines, and each line
containing eight words. The position of the line within the segment is a number from 0
to 63. This is called the index. A line in the cache can be uniquely identified by its
segment and index. The index is independent of the MVA. The segment is selected by
bits [7:5] of the MVA.
————————————————
Bits [4:2] of the MVA specify the word within a cache line that is accessed. For
halfword operations, bit [1] of the MVA specifies the halfword that is accessed within
the word. For byte operations, bits [1:0] specify the byte within the word that is
accessed.
—————————————————
Bits [31:8] of the MVA of each cache line are called the TAG. The MVA TAG is store
in the cache, along with the 8-words of data, when the line is loaded by a linefill.——所有cache的读写原理都是一样的
—————————————————
Cache lookups compare bits [31:8] of the MVA of the access with the stored TAG to
determine whether the access is a hit or miss. The cache is therefore said to be virtually
addressed. The logical model of the 16KB ICache is shown in Figure 4-1 on page 4-5.
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
Enabling and disabling the ICache
————————————————
On reset, the ICache entries are all invalidated and the ICache is disabled.
You can enable the ICache by writing 1 to the Icr bit, and disable it by writing 0 to the
Icr bit.
When the ICache is disabled, the cache contents are ignored and all instruction fetches
appear on the AMBA ASB interface as separate nonsequential accesses. The ICache is
usually used with the MMU enabled. In this case the Ctt in the relevant MMU
translation table descriptor indicates whether an area of memory is cachable.
If the cache is disabled after having been enabled, all cache contents are ignored. All
instruction fetches appear on the AMBA ASB interface as separate nonsequential
accesses and the cache is not updated. If the cache is subsequently re-enabled its
contents are unchanged. If the contents are no longer coherent with main memory, you
must invalidate the ICache before you re-enable it (see Register 7, cache operations
register on page2-17).——主存和cache的内容不一致,在重新使能ICache之前必须清除ICache
————————————————————————————————————
If the cache is enabled with the MMU disabled, all instruction fetches are treated as
cachable. No protection checks are made, and the physical address is flat-mapped(?) to the
modified virtual address.(使能cache,但是禁用MMU,指令存取是cachable的,没有保护检查
物理地址等于虚拟地址。)
You can enable the MMU and ICache simultaneously(同时地) by writing a 1 to the M bit, a
1 to the Icr bit in CP15 register 1, with a single MCR instruction.
————————————————————————————————————
If the ICache is disabled, each instruction fetch results in a separate nonsequential
memory access on the AMBA ASB interface, giving very low bus and memory
performance. Therefore, you must enable the ICache as soon as possible after reset.
————————————————————————————————————
Note
The Prefetch ICache Line operation uses MVA format, because address aliasing(混淆现象) is not
performed on the address in Rd. It is advisable for the associated TLB entry to be locked
into the TLB to avoid page table walks during execution of the locked code.
————————————————————————————————————
Enabling and disabling the DCache and write buffer
On reset, the DCache entries are invalidated and the DCache is disabled, and the write
buffer contents are discarded(放弃).
——————————————
There is no explicit(直接的,清楚的) write buffer enable bit implemented in ARM920T. The write buffer
is used in the following ways:
?You can enable the DCache by writing 1 to the Ccr bit, and disable it by writing
0 to the Ccr bit.
?You must only enable the DCache when the MMU is enabled. This is because the
MMU translation tables define the cache and write buffer configuration for each
memory region.
?If the DCache is disabled after having been enabled, the cache contents are
ignored and all data accesses appear on the AMBA ASB interface as separate
nonsequential accesses and the cache is not updated. If the cache is subsequently
re-enabled its contents are unchanged. Depending on the software system design,
you might have to clean the cache after it is disabled, and invalidate it before you
re-enable it. See Cache coherence on page4-16.
?You can enable or disable the MMU and DCache simultaneously with a single
MCR
that changes the M bit and the C bit in the control register (CP15 register 1).
————————————————————————————————————————————
for seg = 0 to 7
for index = 0 to 63
Rd = {seg,index}
MCR p15,0,Rd,c7,c10,2; Clean DCache single
; entry (using index)
or
MCR p15,0,Rd,c7,c14,2; Clean and Invalidate
; DCache single entry
; (using index)
next index
next seg
DCache, ICache, and memory coherence is generally achieved by:
?cleaning the DCache to ensure memory is up to date with all changes
?invalidating the ICache to ensure that the ICache is forced to re-fetch instructions
from memory.
————————————————————————————————————————————
Situations that necessitate cache cleaning and invalidating include:(需要清理和清除cache的情况)
参考资料:
作者:wogoyixikexie@gliet
——————————————————————————————————————————————
MMU的大名,早就听说了,可是一直不知道它是怎么工作的,前几月貌似看的模模糊糊,现在快年关了,来做个了结。在文中我会大量引用英文,并且不做翻译,因为俺觉得我的英文水平会误解别人。O(∩_∩)O哈哈~
One of the key services provided by an MMU is the ability to manage tasks as indepen-dent programs running in their own private memory space. A task written to run under the control of an operating system with an MMU does not need to know the memory
requirements of unrelated tasks. This simpli?es the design requirements of individual tasks running under the control of an operating system.
——给每个任务提供独立的运行空间。
The MMU simpli?es the programming of application tasks because it provides the resources needed to enable virtual memory—an additional memory space that is indepen-dent of the physical memory attached to the system. The MMU acts as a translator, which
converts the addresses of programs and data that are compiled to run in virtual memory to the actual physical addresses where the programs are stored in physical main memory.This translation process allows programs to run with the same virtual addresses while being
held in different locations in physical memory.——MMU作为一个转换器。程序可以运行在同一块虚拟内存,而各自存储在不同的物理内存。
We begin with a review of the protection features of an MPU and then present the additional features provided by an MMU. We introduce relocation registers, which hold the conversion data to translate virtual memory addresses to physical memory addresses,
and the Translation Lookaside Buffer (TLB), which is a cache of recent address relocations.We then explain the use of pages and page tables to con?gure the behavior of the relocation registers.
——这里介绍重定位寄存器,它保存转换虚拟地址到物理地址的数据;介绍旁路缓冲器(TLB),它是存放最近的的地址重定位信息的cache(高速缓存);介绍如是使用页和页表来重新配置重定位寄存器。
We then discuss how to create regions by con?guring blocks of pages in virtualmemory .We end the overview of the MMU and its support of virtual memory by showing how tomanipulate the MMU and page tables to support multitasking.
——讨论通过虚拟内存中的块页表来配置来创建区域。最后演示使用虚拟内存来支持和创建多任务操作系统
___________________________________________________________________________
现在来看看这个MMU到底有什么东西,有什么特备的硬件结构
—————————————————————————————————————
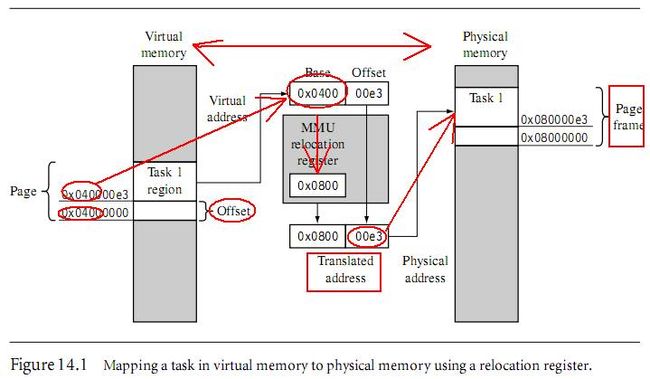
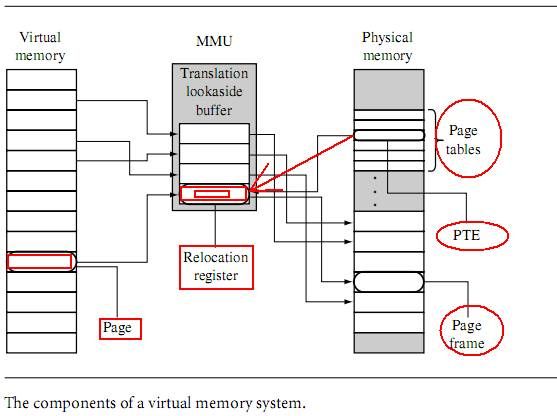
To permit tasks to have their own virtual memory map, the MMU hardware performs address relocation, translating the memory address output by the processor core before it reaches main memory. The easiest way to understand the translation process is to imagine
a relocation register located in the MMU between the core and main memory.——地址重定位寄存器,其实就是地址转换器
Figure 14.1 shows an example of a task compiled to run at a starting address of 0x4000000 in virtual memory. The relocation register translates the virtual addresses ofTask 1 to physical addresses starting at 0x8000000.
A second task compiled to run at the same virtual address, in this case 0x400000, can be placed in physical memory at any other multiple of 0x10000 (64 KB) and mapped to 0x400000 simply by changing the value in the relocation register.
——为什么一定要是64KB为倍数的的地址的物理存储器上?难道这个是MMU有什么特殊的硬件结构决定了?
———————————————————————————————————
A single relocation register can only translate a single area of memory, which is set by
the number of bits in the offset portion of the virtual address. This area of virtual memory
is known as a page. The area of physical memory pointed to by the translation process is
known as a page frame.——页和页帧
———————————————上面虚拟内存的转换过程了———————————————
The set of relocation registers that temporarily store the translations in an ARM MMU
are really a fully associative cache of 64 relocation registers. This cache is known as a
Translation Lookaside Buffer (TLB). The TLB caches translations of recently accessed pages.
——重定位寄存器是由64个重定位寄存器cache相连成的,这个cache被称为旁路缓冲器(TLB),它缓存最近访问页转换的数据。——我觉得是地址数据才对,因为ARM9是数据总线和地址总线分离的。
In addition to having relocation registers, theMMUuses tables inmainmemory to store
the data describing the virtualmemorymaps used in the system. These tables of translation
data are known as page tables. An entry in a page table represents all the information needed
to translate a page in virtual memory to a page frame in physical memory.
——除了使用重定位寄存器外,MMU还使用在主存中的表来存放描述虚拟内存映射的数据,这个表被称为页表。
而页表的每个子表存储了一个页转换到物理存储器的一个页帧所需要的信息。
—————————————————————————————————
Apage table entry (PTE) in a page table contains the following information about a virtual
page: the physical base address used to translate the virtual page to the physical page frame,
the access permission assigned to the page, and the cache and write buffer con?guration for
the page. If you refer to Table 14.1, you can see that most of the region con?guration data
in an MPU is now held in a page table entry. This means access permission and cache and
write buffer behavior are controlled at a granularity(粒度) of the page size, which provides ?ner
control over the use of memory. Regions in an MMU are created in software by grouping
blocks of virtual pages in memory.——MMU区域由在内存中的虚拟页的块群以软件方法创建
___________________________________________________________________
Since a page in virtual memory has a corresponding (连续的)entry (条目)in a page table, a block of
virtual memory pages map to a set of sequential entries in a page table. Thus, a region can
be de?ned as a sequential set of page table entries. The location and size of a region can be
held in a software data structure while the actual translation data and attribute information
is held in the page tables.
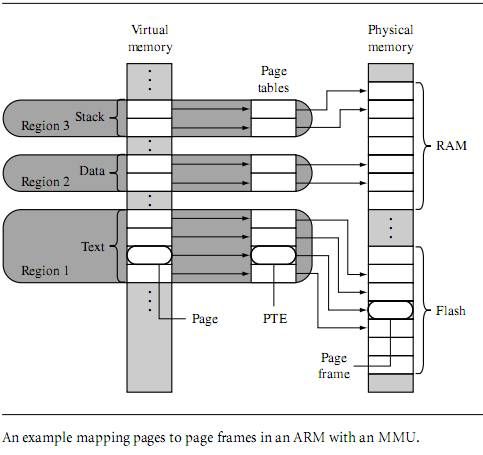
Figure 14.3 shows an example of a single task that has three regions: one for text, one
for data, and a third to support the task stack. Each region in virtual memory is mapped
to different areas in physical memory. In the ?gure, the executable code is located in ?ash
memory, and the data and stack areas are located in RAM. This use of regions is typical of
operating systems that support sharing code between tasks.——操作系统就是这么设计的?
With the exception of the master level 1 (L1) page table, all page tables represent 1 MB
areas of virtual memory. If a region’s size is greater than 1 MB or crosses over the 1 MB
boundary addresses that separate page tables, then the description of a region must also
include a list of page tables. The page tables for a region will always be derived from
sequential page table entries in the master L1 page table. However, the locations of the L2
page tables in physical memory do not need to be located sequentially. Page table levels are
explained more fully in Section 14.4.
——难道在wince中的OEMAddresstable中的虚拟内存大小都是1M的倍数,且是连续
的是由此而来?(其实wince可以使用不连续的,不过要使用特殊技巧才行)
在物理内存中的页表可以是非连续的。——优龙的bootloader就有此见证!
看看下图
————————————————————————————————————————
MMU是如何实现多任务调度的?
——————————————
Page tables can reside inmemory and not bemapped toMMU hardware. One way to build
amultitasking system is to create separate sets of page tables, each mapping a unique virtual
memory space for a task. To activate a task, the set of page tables for the speci?c task and
its virtual memory space are mapped into use by theMMU. The other sets of inactive page
tables represent dormant tasks. This approach allows all tasks to remain resident in physical
memory and still be available immediately when a context switch occurs to activate it.
——页表可以驻留在内存中,不必映射到MMU硬件。构建多任务的一种方法是创建一批
独立的页表,每个映射到唯一的任务空间。为了激活某个任务,对应这个任务的那组页表
和其虚拟内存空间由MMU使用,没有激活的页表代表睡眠的任务。这种方法使所有的任务
可以驻留在内存中,当发生上下文切换的时候可以立即使用。
By activating different page tables during a context switch, it is possible to execute
multiple tasks with overlapping virtual addresses. The MMU can relocate the execution
address of a task without the need to move it in physical memory. The task’s physical
memory is simply mapped into virtual memory by activating and deactivating page tables.
——在上下文切换时候通过激活不同的页表,使得在重叠的虚拟地址执行多任务
成为可能。MMU可以通过重定位任务地址而不需要移动在内存中的任务。任务的
物理内存只是简单的通过激活与不激活页表来实现映射到虚拟内存
——My GOD!明白MMU的工作原理了!!!!!!!!!
——————————————————————————————————————
When the page tables are activated or deactivated, the virtual-to-physical address map-
pings change. Thus, accessing an address in virtual memory may suddenly translate to a
different address in physical memory after the activation of a page table. As mentioned in
Chapter 12, the ARM processor cores have a logical cache and store cached data in virtual
memory. When this translation occurs, the caches will likely contain invalid virtual data
from the old page table mapping. To ensure memory coherency, the caches may need
cleaning and ?ushing. The TLB may also need ?ushing because it will have cached old
translation data.——注意清理和清除cache哦
————————————————————
The effect of cleaning and ?ushing the caches and the TLB will slow system operation.
However, cleaning and ?ushing stale (陈旧的,过时的)code or data from cache and stale translated physical
addresses from the TLB keep the system from using invalid data and breaking.
——虽然清理和清除cache和TLB会导致系统运行变慢,但是清理和清除cache中过时的代码数据,
或者过时的物理地址,可以避免系统使用无效的数据而崩溃。
———————————————————————————————
During a context switch, page table data is not moved in physical memory; only pointers
to the locations of the page tables change.——任务切换如下步骤。
To switch between tasks requires the following steps:
1. Save the active task context and place the task in a dormant state.
2. Flush the caches; possibly clean the D-cache if using a writeback policy.
3. Flush the TLB to remove translations for the retiring task.
4. Con?gure the MMU to use new page tables translating the virtual memory execution
area to the awakening task’s location in physical memory.
5. Restore the context of the awakening task.
6. Resume execution of the restored task.
Note: to reduce the time it takes to perform a context switch, a writethrough cache
policy can be used in the ARM9 family. Cleaning the data cache can require hundreds of
writes to CP15 registers. By con?guring the data cache to use a writethrough policy, there is
no need to clean the data cache during a context switch, which will provide better context
switch performance. Using a writethrough policy distributes these writes over the life of
the task. Although a writeback policy will provide better overall performance, it is simply
easier to write code for small embedded systems using a writethrough policy.
——使用文件系统的应该使用会写策略,这样效率较高。
++++++++++++++++++++++为什么虚拟内存和物理内存映射是要固定的?===========
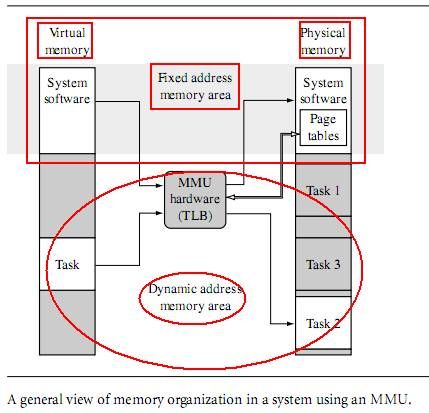
Typically, page tables reside in an area of main memory where the virtual-to-physical
address mapping is ?xed. By “?xed,” we mean data in a page table doesn’t change during
normal operation, as shown in Figure 14.5. This ?xed area of memory also contains the
operating system kernel and other processes. The MMU, which includes the TLB shown
in Figure 14.5, is hardware that operates outside the virtual or physical memory space; its
function is to translate addresses between the two memory spaces.
——在运行系统时候不能改变两者的映射,否则很容易出错,wince是这样的,
不知道linux是怎么样的了,ADS 下的bootloader也是这样的。
————————————————方框的是固定映射————————————