mycat扩容报错(后端节点为阿里RDS):ERROR 1227:Access denied; you need (at least one of) the SUPER privilege(s)
本文是记一次mycat后端数据库为阿里云RDS的mycat扩容折腾过程:
背景是,mycat后端连接的是阿里RDS,原先有2个节点,现在需要扩大到10个节点。
这里简要介绍下扩容的官方步骤:(官方文档)
6.1 离线扩容缩容
工具目前从 mycat1.6 开始支持。
一、准备工作
1、mycat 所在环境安装 mysql 客户端程序
2、mycat 的 lib 目录下添加 mysql 的 jdbc 驱动包 3、对扩容缩容的表所有节点数据进行备份,以便迁移失败后的数据恢复
二、扩容缩容步骤
1、复制 schema.xml、rule.xml 并重命名为 newSchema.xml、newRule.xml 放于 conf 目录下
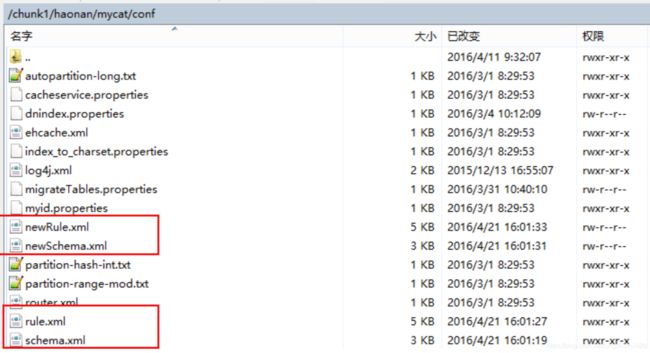
2、修改 newSchema.xml 和 newRule.xml 配置文件为扩容缩容后的 mycat 配置参数(表的节点数、 数据源、路由规则)
3、修改 conf 目录下的 migrateTables.properties 配置文件,告诉工具哪些表需要进行扩容或缩 容,没有出现在此配置文件的 schema 表不会进行数据迁移,格式: 
4、修改 bin 目录下的 dataMigrate.sh 脚本文件,参数如下:
tempFileDir 临时文件路径,目录不存在将自动创建
isAwaysUseMaster 默认 true:不论是否发生主备切换,都使用主数据源数据,false:使用当前数据源 mysqlBin:mysql bin 路径
cmdLength mysqldump 命令行长度限制 默认 110k 1101024。在 LINUX 操作系统有限制单条命令行的长度是 128KB,也就是 131072 字节,这个值可能不同操作系统不同内核都不一样,如果执行迁移时报 Cannot run program “sh”: error=7, Argument list too long 说明这个值设置大了,需要调小此值。
charset 导入导出数据所用字符集 默认 utf8
deleteTempFileDir 完成扩容缩容后是否删除临时文件 默认为 true
threadCount 并行线程数(涉及生成中间文件和导入导出数据)默认为迁移程序所在主机环境的 cpu 核数2 delThreadCount 每个数据库主机上清理冗余数据的并发线程数,默认为当前脚本程序所在主机 cpu 核数/2 queryPageSize 读取迁移节点全部数据时一次加载的数据量 默认 10w 条
5、停止 mycat 服务(如果可以确保扩容缩容过程中不会有写操作,也可以不停止 mycat 服务)
6、通过 crt 等工具进入 mycat 根目录,执行 bin/ dataMigrate.sh 脚本,开始扩容/缩容过程:
7、扩容缩容成功后,将 newSchema.xml 和 newRule.xml 重命名为 schema.xml 和 rule.xml 并替 换掉原文件,重启 mycat 服务,整个扩容缩容过程完成。
三、注意事项:
- 保证拆分表迁移数据前后路由规则一致
- 保证拆分表迁移数据前后拆分字段一致
- 全局表将被忽略
- 不要将非拆分表配置到migrateTables.properties文件中 5) 暂时只支持拆分表使用mysql作为数据源的扩容缩容
四、优化
dataMigrate.sh 脚本中影响数据迁移速度的有 4 个参数,正式迁移数据前可以先进行一次测 试,通过调整以下参数进行优化获得一个最快的参数组合
threadCount 脚本执行所在主机的并行线程数(涉及生成中间文件和导入导出数据)默认为迁移程序所在主机环境的 cpu 核数2 delThreadCount 每个数据库主机上清理冗余数据的并发线程数,默认为当前脚本程序所在主机 cpu 核数/2,同一主机上并发删
除数据操作线程数过多可能会导致性能严重下降,可以逐步提高并发数,获取执行最快的线程个数。
queryPageSize 读取迁移节点全部数据时一次加载的数据量 默认 10w 条
cmdLength mysqldump 命令行长度限制 默认 110k 1101024。尽量让这个值跟操作系统命令长度最大值一致,可以通过以下过程 确定操作系统命令行最大长度限制:
逐步减少 100000,直到不再报错
/bin/sh -c “/bin/true $(seq 1 100000)”
获取不报错的值,通过 wc –c 统计字节数,结果即操作系统命令行最大长度限制(可能稍微小一些)
下面介绍下出现的问题
刚开始跑的还算正常,到了最后一步的时候出现了如下图的报错:

什么鬼?居然冒出权限问题,需要超级权限!刚开始还天真找阿里要RDS的root权限,后面发现想多了。(这个方式是最简单能解决的办法,可惜行不通!)
没办法被逼着找其他办法!
根据错误提示和运行mycat迁移脚本生成的比对文件,百度、谷歌。
首先发现在比对文件里开头有下面2句语句:
SET @MYSQLDUMP_TEMP_LOG_BIN = @@SESSION.SQL_LOG_BIN;
SET @@SESSION.SQL_LOG_BIN= 0;
根据介绍和mycat迁移模块源码:
当源库使用了GTID模式时,在dump出来的文件中为了保持目标库和源库GTID值相同,增加了两个语句, SET@@SESSION.SQL_LOG_BIN= 0 和 SET @@GLOBAL.GTID_PURGED='xxxx'。
而实际上增加这两个语句会有诸多问题:
关闭binlog首先需要super权限,如果目标库只能使用普通账号,则会导致执行失败;
即使有super权限,也会导致这些操作不记录到binlog,会导致主备不一致。当然也可以说,这就要求同一份dump要restore到目标库的主库和所有备库才能保持主备一致;
SET @@GLOBAL.GTID_PURGED='xxxx'这个命令要求目标库的gtid_executed值是空。若非空,这个命令执行失败;
reset master可以清空gtid_executed值,也需要super权限。
因此在导出数据时,有两种可选方案:
1、在有目标库的super权限时,用默认dump参数,在导入到目标库之前,先执行reset master;这样需要在主库和所有备库都执行相同个导入动作。
2、mysqldump需要增加参数 –set-gtid-purged=off,这样不会生成上述两个语句,数据能够直接导入。但是目标库的gtid set就与源库不同。
需要根据业务需求选择。
阿里RDS绝对是开启了GTID模式,还有binglog,他又不给你root权限,那选择只有一个了。
现在就是怎么样把mycat迁移脚本里生成的比对文件里不让生成下面2个语句:
SET @MYSQLDUMP_TEMP_LOG_BIN = @@SESSION.SQL_LOG_BIN;
SET @@SESSION.SQL_LOG_BIN= 0;
在src/main/java/io/mycat/migrate/MigrateDumpRunner.java 里可以看到,mycat迁移操作,就是一个导出导入的动作。
@Override
public void run() {
try {
String mysqldump = "?mysqldump -h? -P? -u? -p? ? ? --single-transaction -q --default-character-set=utf8mb4 --hex-blob --where=\"?\" --master-data=1 -T \"?\" --fields-enclosed-by=\\\" --fields-terminated-by=, --lines-terminated-by=\\n --fields-escaped-by=\\\\ ";
PhysicalDBPool dbPool = MycatServer.getInstance().getConfig().getDataNodes().get(task.getFrom()).getDbPool();
PhysicalDatasource datasource = dbPool.getSources()[dbPool.getActivedIndex()];
DBHostConfig config = datasource.getConfig();
File file = null;
String spath = querySecurePath(config);
if (Strings.isNullOrEmpty(spath) || "NULL".equalsIgnoreCase(spath) || "empty".equalsIgnoreCase(spath)) {
file = new File(SystemConfig.getHomePath() + File.separator + "temp", "dump" + File.separator + task.getFrom() + "_" + task.getTo());
// task.getFrom() + "_" + task.getTo() + Thread.currentThread().getId() + System.currentTimeMillis() + "");
} else {
spath += Thread.currentThread().getId() + System.currentTimeMillis();
file = new File(spath);
}
file.mkdirs();
String encose = OperatingSystem.isWindows() ? "\\" : "";
String finalCmd = DataMigratorUtil
.paramsAssignment(mysqldump, "?", "", config.getIp(), String.valueOf(config.getPort()), config.getUser(),
config.getPassword(), MigrateUtils.getDatabaseFromDataNode(task.getFrom()), task.getTable(), makeWhere(task), file.getPath());
List args = Arrays.asList("mysqldump", "-h" + config.getIp(), "-P" + String.valueOf(config.getPort()), "-u" + config.getUser(),
!StringUtil.isEmpty(config.getPassword()) ? "-p" + config.getPassword() : "", MigrateUtils.getDatabaseFromDataNode(task.getFrom()), task.getTable(), "--single-transaction", "-q", "--default-character-set=utf8mb4", "--hex-blob", "--where=" + makeWhere(task), "--master-data=1", "-T" + file.getPath()
, "--fields-enclosed-by=" + encose + "\"", "--fields-terminated-by=,", "--lines-terminated-by=\\n", "--fields-escaped-by=\\\\");
LOGGER.info("migrate 中 mysqldump准备执行命令,如果超长时间没有响应则可能出错");
LOGGER.info(args.toString());
String result = ProcessUtil.execReturnString(args);
int logIndex = result.indexOf("MASTER_LOG_FILE='");
int logPosIndex = result.indexOf("MASTER_LOG_POS=");
String logFile = result.substring(logIndex + 17, logIndex + 17 + result.substring(logIndex + 17).indexOf("'"));
String logPos = result.substring(logPosIndex + 15, logPosIndex + 15 + result.substring(logPosIndex + 15).indexOf(";"));
task.setBinlogFile(logFile);
task.setPos(Integer.parseInt(logPos));
File dataFile = new File(file, task.getTable() + ".txt");
File sqlFile = new File(file, task.getTable() + ".sql");
if (!sqlFile.exists()) {
LOGGER.debug(sqlFile.getAbsolutePath() + "not exists");
}
List createTable = Files.readLines(sqlFile, Charset.forName("UTF-8"));
LOGGER.info("migrate 中 准备自动创建新的table:"+createTable);
exeCreateTableToDn(extractCreateSql(createTable), task.getTo(), task.getTable());
if (dataFile.length() > 0) {
loaddataToDn(dataFile, task.getTo(), task.getTable());
}
pushMsgToZK(task.getZkpath(), task.getFrom() + "-" + task.getTo(), 1, "sucess", logFile, logPos);
DataMigratorUtil.deleteDir(file);
sucessTask.getAndIncrement();
} catch (Exception e) {
try {
pushMsgToZK(task.getZkpath(), task.getFrom() + "-" + task.getTo(), 0, e.getLocalizedMessage(), "", "");
} catch (Exception e1) {
}
LOGGER.error("error:", e);
} finally {
latch.countDown();
}
}
开始在以上代码处args = Arrays.asList("mysqldump后加上 –set-gtid-purged=off参数,重新打包程序。再次部署,然后执行迁移操作。然而,还是报同样的错,同样在比对文件里还是有那2个语句。
应该是没有改对地方,参数没有生效。
又重新查看了源代码,最终在该迁移模块的作者上传的代码下找到了源码类如下:
src/main/java/io/mycat/util/dataMigrator/dataIOImpl/MysqlDataIO.java
package io.mycat.util.dataMigrator.dataIOImpl;
import java.io.BufferedReader;
import java.io.File;
import java.io.IOException;
import java.io.InputStreamReader;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import io.mycat.util.dataMigrator.DataIO;
import io.mycat.util.dataMigrator.DataMigrator;
import io.mycat.util.dataMigrator.DataMigratorUtil;
import io.mycat.util.dataMigrator.DataNode;
import io.mycat.util.dataMigrator.TableMigrateInfo;
import io.mycat.util.exception.DataMigratorException;
/**
* mysql导入导出实现类
* @author haonan108
*
*/
public class MysqlDataIO implements DataIO{
private static final Logger LOGGER = LoggerFactory.getLogger(MysqlDataIO.class);
private String mysqlBin;
private int cmdLength;
private String charset;
private Runtime runtime = Runtime.getRuntime();
public MysqlDataIO(){
cmdLength = DataMigrator.margs.getCmdLength();
charset = DataMigrator.margs.getCharSet();
mysqlBin = DataMigrator.margs.getMysqlBin();
}
@Override
public void importData(TableMigrateInfo table,DataNode dn,String tableName, File file) throws IOException, InterruptedException {
String ip = dn.getIp();
int port = dn.getPort();
String user = dn.getUserName();
String pwd = dn.getPwd();
String db = dn.getDb();
String loadData ="?mysql -h? -P? -u? -p? -D? --local-infile=1 -e \"load data local infile '?' replace into table ? CHARACTER SET '?' FIELDS TERMINATED BY ',' LINES TERMINATED BY '\\r\\n'\"";
loadData = DataMigratorUtil.paramsAssignment(loadData,mysqlBin,ip,port,user,pwd,db,file.getAbsolutePath(),tableName,charset);
LOGGER.debug(table.getSchemaAndTableName()+" "+loadData);
Process process = runtime.exec((new String[]{"sh","-c",loadData}));
//获取错误信息
InputStreamReader in = new InputStreamReader(process.getErrorStream());
BufferedReader br = new BufferedReader(in);
String errMessage = null;
while ((errMessage = br.readLine()) != null) {
if(!errMessage.startsWith("Warning")){
System.out.println(errMessage+" -> "+loadData);
}
}
process.waitFor();
}
@Override
public File exportData(TableMigrateInfo table,DataNode dn, String tableName, File export, File condition) throws IOException, InterruptedException {
String ip = dn.getIp();
int port = dn.getPort();
String user = dn.getUserName();
String pwd = dn.getPwd();
String db = dn.getDb();
String mysqlDump = "?mysqldump -h? -P? -u? -p? ? ? --no-create-info --default-character-set=? "
+ "--add-locks=false --tab='?' --fields-terminated-by=',' --lines-terminated-by='\\r\\n' --where='? in(?)'";
String fileName = condition.getName();
File exportPath = new File(export,fileName.substring(0, fileName.indexOf(".txt")));
if(!exportPath.exists()){
exportPath.mkdirs();
}
//拼接mysqldump命令,不拼接where条件:--where=id in(?)
mysqlDump = DataMigratorUtil.paramsAssignment(mysqlDump,mysqlBin,ip,port,user,pwd,db,tableName,charset,exportPath,table.getColumn());
String data = "";
//由于操作系统对命令行长度的限制,导出过程被拆分成多次,最后需要将导出的数据文件合并
File mergedFile = new File(exportPath,tableName.toLowerCase()+".sql");
if(!mergedFile.exists()){
mergedFile.createNewFile();
}
int offset = 0;
while((data=DataMigratorUtil.readData(condition,offset,cmdLength)).length()>0){
offset += data.getBytes().length;
if(data.startsWith(",")){
data = data.substring(1, data.length());
}
if(data.endsWith(",")){
data = data.substring(0,data.length()-1);
}
String mysqlDumpCmd = DataMigratorUtil.paramsAssignment(mysqlDump,data);
Process process = runtime.exec((new String[]{"sh","-c",mysqlDumpCmd}));
//获取错误信息
InputStreamReader in = new InputStreamReader(process.getErrorStream());
BufferedReader br = new BufferedReader(in);
String errMessage = null;
while ((errMessage = br.readLine()) != null) {
if(!errMessage.startsWith("Warning")){
LOGGER.error("err data->"+data);
System.out.println(errMessage+" -> "+mysqlDump);
}
}
process.waitFor();
//查找导出的文件
File[] files = exportPath.listFiles();
File exportFile = null;
for(int i=0;i在下图位置加上参数。
 加完参数自己打包,重新部署运行程序。
加完参数自己打包,重新部署运行程序。
导入没有问题 OK!搞定! (注意,如果数据量大的话,需要看下mycat服务器磁盘性能是否能承载。)
另外,还有最原始的方式,就是将各个节点的数据导出,然后直接导入,让mycat自己重新hash。