论文笔记5 --(ReID)Diversity Regularized Spatiotemporal Attention for Video-based Person Re-id
《Diversity Regularized Spatiotemporal Attention for Video-based Person Re-identification》
论文:https://arxiv.org/pdf/1803.09882.pdf
这是一篇video base的Person Re-ID的工作。该论文主要集中在提取时空两个方向的attention。
输入一个视频序列,使用约束的随机采样策略选择一个子序列(6张图片,见实验部分),将子序列送入spatial attention模型生成多个判别性区域,然后使用temporal attention模型来加权池化这些判别性区域。最后将所有的时序特征连接起来送入全连接层。
论文使用spatial attention模型自动提取那些具有判别性区域的身体部位,并使用多样化的正则化项来保证各个spatial attention模型学习的身体部位不同。
Abstract
基于视频的person re-id匹配非重叠相机的行人的视频剪辑。大多数现有方法通过将每个视频帧整体编码并计算所有帧之间的聚合表示来解决这个问题。在实际应用中,行人经常存在部分遮挡,这会破坏所提取的特征。相反,我们提出一中新的spatiotemporal attention model,可以自动发现各种独特的身体部位。这允许从所有帧中提取有用的信息,而不必受限于遮挡和失准(occlusions and misalignments)。网络学习多个spatial attention模型,并采用多样性正则化项来确保多个模型不发现相同的身体部分。从局部图像区域提取的特征由spatial attention模型组织,并利用temporal attention进行组合。因此,网络使用来自整个视频序列的最佳可用图像块来学习面部、躯干和其他身体部位的潜在表示。对三个数据集的广泛评估表明,我们的框架在多个指标上超过了最先进的方法。
1. Introduction
person re-id将一个相机中的行人图像与另一个非重叠相机的行人图像进行匹配。近年来,这一任务由于其在监视[42]、活动分析[32]和跟踪[47]等应用中的重要性而日益受到关注。由于相机视点、人体姿态、光照、遮挡和背景杂波的复杂变化,这仍然是一个具有挑战性的问题。
本文研究了基于视频的person re-id问题,它是re-id任务的推广。算法必须匹配视频序列对(可能具有不同的持续时间),而不是匹配图像对。这种范例中的关键挑战是开发每个视频序列的良好的潜在特征表示。
现有的基于视频的person re-id方法将每个帧表示为特征向量,然后使用平均或最大池计算跨时间的聚合表示[52,28,46]。不幸的是,在应用于遮挡频繁的数据集时,有几个缺点(图1)。为每个图像生成的特征表示常常被遮挡物的视觉外观所破坏。然而,该行人的其余可见部分可以为re-id提供强有力的提示。从这些不同的瞥见中集合一个人的有效表示应该是可能的。然而,跨时间聚合特征并不简单。一个人的姿势会随着时间的推移而改变,这意味着在比较从不同帧提取的特征时,任何聚合方法都必须考虑空间错位(除了遮挡)。
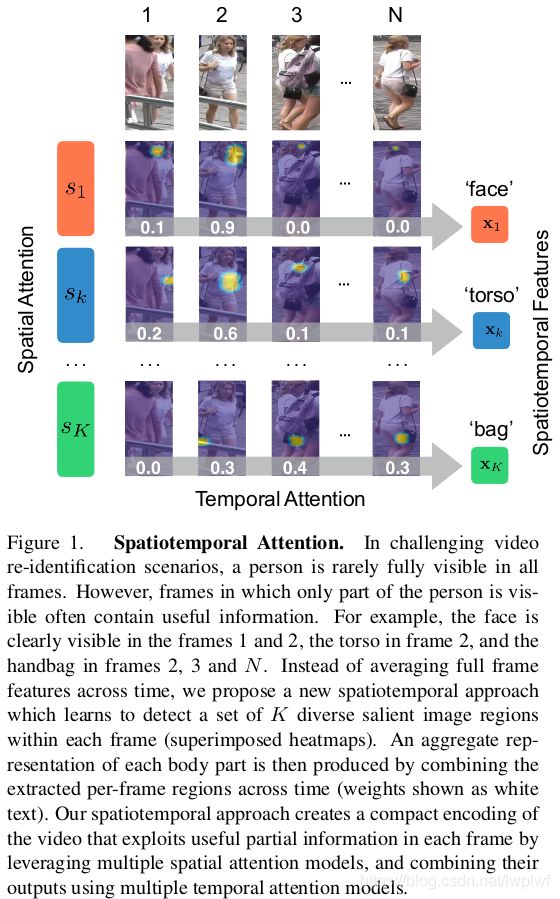
本文提出了一种新的spatiotemporal attention方案,有效地解决了基于视频的person re-id的困难。我们不是直接编码整个图像(或预定义的分解,如网格),而是使用多个spatial attention模型来定位判别图像区域,并使用使用temporal attention将这些提取的局部特征汇集在一起。我们的方法有几个有用的特性:
- spatial attention明确地解决了图像之间的对齐问题,并避免特征被遮挡区域破坏。
- 虽然许多有区别的图像区域与身体部位相对应,但太阳镜、背包和帽子之类的配件很普遍,对re-id很有用。由于这些类别很难预先定义,我们采用无监督学习方法,并让神经网络自动发现一组判别对象部分检测器(spatial attention models)。
- 我们采用基于Hellinger距离的新的多样性正则化项,以确保多个spatial attention模型不会发现相同的身体部分。
- 我们使用temporal attention模型来计算由每个spatial attention模型提取的特征的聚合表示。然后将这些聚合表示连接成最终的特征向量,该特征向量表示整个视频中可用的所有信息。
我们在三个具有挑战性的re-id数据集上展示了该方法的有效性。我们的技术在多个评估指标下表现出了最先进的水平。
2. Related Work
person re-id首次被提出用于多摄像头跟踪[42,38]。Gheissari等人[11]设计了一个时空分割方法来提取视觉线索,并采用颜色和显著边缘进行前景检测。这项工作将基于图像的person re-id定义为特定的计算机视觉任务。
基于图像的person re-id主要集中于两方面:提取判别特征[13,9,33,19,43]和学习鲁棒度量[37,50,18,36,2]。近年来,研究人员提出了许多基于深度学习的方法[1,24,8,20,44]来处理这两个方面。Ahmed等人[1]将一对裁剪的行人图像输入到专门设计的CNN中用于person re-id,该CNN具有二进制验证损失函数。在[8]中,Ding等人在训练深层神经网络时,采用triplet loss使同一个人之间的特征距离最小化,使不同人之间的距离最大化。Xiao等[44]在单个CNN模型中联合训练行人检测和person re-id。他们提出了一种在线实例匹配损失函数,该函数能够更有效地学习大规模验证问题中的特征。
基于视频的person re-id[35,52,46,41,53,34]是基于图像的方法的扩展。送给学习算法的数据从一对图像变成了一对视频序列。在[46]中,You等人提出一种基于类内差异最小化的顶推式远程学习模型(top-push distance learning model accompanied by the minimization of intra-class variations),以优化高层次的匹配精度,实现person re-id。McLaughlin等[35]引入RNN模型对时间信息进行编码。利用时间池来选择每个特征维度上的最大激活,并计算两个视频的特征相似度。Wang等[41]从噪声/不完整图像序列中选择可靠的时空特征,同时学习视频ranking function。Ma等[34]对时空动态的多个粒度进行编码,以生成每个人的潜在表示。为了在不精确序列和不完整序列之间选择和匹配数据,导出了时移动态时间扭曲模型。
person re-id的attention models。attention models[45,22,21]自[45]以来越来越来受欢迎。Zhou等人[52]通过建立端到端深度神经网络来组合空间和时间(spatial and temporal)信息。attention models根据RNN的隐含状态为输入帧分配重要性分数。最后一个特征是RNN输出的时间平均池化(average pooling)。然而,如果以这种方式训练,attention models的不同时间步长的相应权重趋向于具有相同的值。Liu等人[30]提出了一种多向注意模块(multi-directional attention module),利用全局和局部内容进行基于图像的person re-id。但是,联合训练多个注意力可能导致模式崩溃。网络必须经过仔细的训练,以避免attention models集中在具有高冗余度的相似区域。本文将spatial and temporal attentions结合到spatiotemporal attention models中,以解决基于视频的person re-id问题。对于spatial attention,我们使用惩罚项来规范多个冗余注意。我们利用temporal attention在每帧的基础上对不同的显著区域分配权重,以充分利用判别图像区域。我们的方法展示了更好的经验性能,并分解为直观的网络体系结构。
3. Method
我们提出了一种新的深度学习架构(图2),通过自动将数据组织成一组一致的显著子区域来更好地处理视频re-id。给定输入视频序列,我们首先使用约束的随机采样策略来选择视频帧的子集(第3.1节)。然后将选择的帧送到multiregion spatial attention 模块(第3.2节),以产生一组不同的判别空间门控视觉特征(spatial gated visual features),每个特征大致对应于人的特定显著区域(第3.3节)。在视频的持续时间内,每个显著区域的整体表示都是使用temporal attention生成的(第3.4节)。最后,我们连接所有的时间门控特征,并将它们送到表示原始输入视频序列的潜在时空编码的全连接层。Xiao等人提出的OIM损失函数。[44],构建在FC层之上,以端到端的方式监督整个网络的训练。然而,也可以采用任何传统的损失函数(如softmax)。
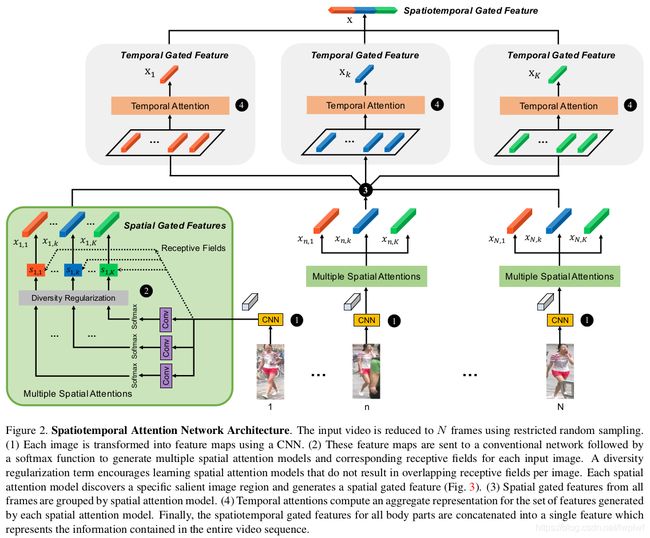
3.1. Restricted Random Sampling
以前的基于视频的person re-id方法[35,34,52]不对远程时间结构建模,因为输入的视频序列相对较短。在某种程度上,由于连续视频帧是高度相关的,并且从一个帧中提取的视觉特征在短序列过程中不会发生显著变化,因此这种范例仅比基于图像的重新识别稍微复杂一些。然而,当输入视频序列较长时,任何re-id方法都必须能够应对随时间的显著视觉变化,例如相对于相机的不同身体姿势和角度。
Wang等人[39]提出了一种时间片段网络来生成用于动作识别的视频片段。受其启发,我们提出一种约束的随机采样策略以期能够获得原始数据好的特征表达。该方法能够利用整个视频序列的视觉信息,同时避免连续帧之间的冗余。给定一个输入视频V,将其按照相等时间划分为N个块{Cn}n=1,N。从每个块Cn中随机地对图像In进行采样,即每个块中随机选择1张图片。然后,视频由有序的一组采样帧表示{In}n=1,N。
ps:
1、该方法是分块再随机采样,这过程中并没有考虑所选择图片的质量,如果刚好选择的图片质量都很差,那是否会有影响?
2、论文中是对视频分了6个块,再从每个块中随机选择1张图片,那这6张图应该还是具有时序信息的啊。
3.2. Multiple Spatial Attention Models
我们使用多个spatial attention模型自动发现对re-id有用的具有判别性的区域(身体部位或配饰)。我们的方法不是预先定义输入图像的刚性空间分解(例如网格结构),而是自动识别在多个训练视频中始终出现的每个图像中多个不相交的显著区域。因为网络学习识别和定位这些区域(例如,自动发现一组对象部分检测器),所以我们的方法减轻了由姿态变化、尺度变化和遮挡引起的配准问题。我们的方法不限于检测人体部位。它可以集中于任何信息丰富的图像区域,如帽子、袋子和在re-id数据集中经常发现的其他配饰。直接从整个图像生成的特征表示很容易错过细粒度的视觉信息(图1)。另一方面,多种多样的spatial attention模型能够同时发现有区别的视觉特征,同时减少背景内容和遮挡的干扰。虽然spatial attention不是一个新概念,但据我们所知,这是首次设计一个网络来自动发现跨多个视频一致的图像帧内的不同attention集合。
如图2所示,我们采用ResNet-50 CNN结构[14]作为基础模型,用于从每个采样图像中提取特征。CNN前面有一个卷积层(命名为conv1),后面是四个残差块。使用res5c提取的特征为8×4网格的特征向量{fn,l}l=1,L,其中L=32=8×4是网格单元的数量,每个特征是D=2048维向量。
特征向量经过两次线性变换和一个ReLU激活产生en,k,l。对于第k个模型,单元l的特征向量产生的spatial attentionsn,k,l的数量由en,k,l确定。
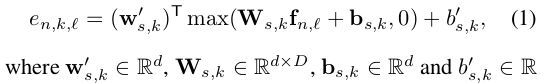
经过第一次线性变换将原始数据投影到d=256维空间,而第二次变换对于每个cell产生一个标量值。最后的attention值通过softmax计算为:
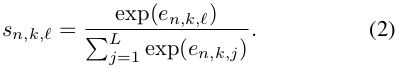
集合Sn,k=[Sn,k,1,...,Sn,k,L]表示第k个spatial attention model在图像In上的感受野区域的权值。根据定义,每个感受野是一个概率质量函数:
![]()
对于每个图像In,通过attention权值加权平均可以得到K个空间门(spatial gated)视觉特征{xn,k}k=1,K
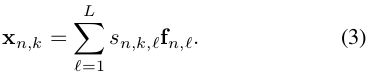
每个门特征表示输入图片的一个显著性区域(图3),由上面的式子可以发现,作者得到的区域Xn,k是将所有的cell做加权平均计算得到的,这样的方式很难获取具体的位置信息,并且作者认为这样对齐的区域也是粗糙的。

因此作者使用了类似于fine-grained的目标识别方法[26],使用了一个增强变量 。增强函数E()遵循了二阶池化(second-order pooling)的工作[5]。有关详细信息,请参阅补充材料。
![]()
3.3. Diversity Regularization
由3.2中的推导可以发现,不同的attention model并没有约束,这样它们很可能产生同样的判别性区域。在实际中,我们需要确保不同的spatial attention models去关注给定图像的不同区域。
由于每个感受野Sn,k具有概率解释,因此一种解决方案是使用Kullback-Leibler散度来评价一个给定图像的感受野的多样性。
定义矩阵Sn
![]()
为K个spatial attention模型为图像In生成的感受野的集合
![]()
作者实验证明,在softmax()函数之后,attention矩阵的许多值接近于零,并且当通过Kullback-Leibler发散中的log()操作时,这些小值急剧下降,这表明训练过程是不稳定的[27]。
为了使得不同的spatial attention模型关注于不同的显著区域,作者设计了一个惩罚项,用来衡量不同感受野之间的重叠,作者计算来两个attention向量sn,i和sn,j的重叠区域,利用海林格(Hellinger)距离[4]来计算sn,i和sn,j的相似性。定义为:
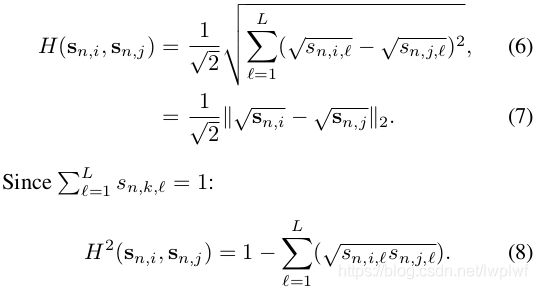
为了确保感受野的多样性,需要最大化sn,i和sn,j之间的距离,这相当于最小化
![]()
记Rn
![]()
每个图像的感受野冗余的正则项是:
![]()
其中||.||F表示矩阵的Frobenius范数,I是K维单位矩阵。该正则项Q将乘以一个系数,并添加到原始OIM loss中。
关于多样性正则化的变体(用于使用递归网络(recurrent networks)的文本嵌入[27]):
![]()
虽然Q和Q’有相似的表达式,但正则化效果非常不同。区别在于Q是基于
![]()
概率密度分布的推导,而Q’适用于所有矩阵。Q’倾向于使Sn变得稀疏–使得非零元素都在Sn的对角线上。虽然Q’也能强制要求感受野不重叠,但它更聚焦于单个cell上。而Q则允许出现像“上身”这样大的显著区域。在第4.3节中,我们比较了两个正则化项Q和Q’的性能。
3.4. Temporal Attention
回想一下,每个帧In由K个增强的空间选通特征的集合
![]()
表示,每个特征由K个spatial attention模型之一生成。现在我们考虑如何最好地组合从各个帧中提取的这些特征,以产生整个输入视频的紧凑表示。
不少基于视频的论文都是对序列中的帧计算一个质量权值,而本文认为因为遮挡原因,使用权值平均是不够鲁棒的。
但是,实际上现在做平均的很多都是只提取身体的部位再进行平均。
作者在前面也提到,为什么选择使用spatial attention找到显著部位而不是精细设计的各个身体的部分。
作者应用多个temporal attention权重{tn, 1, ...tn, K}到每个帧每个空间分量。这样temporal attention模型能够基于不同显著区域的优点来评估帧的重要性。仅对整个帧特征进行操作的temporal attention模型很容易在具有中等遮挡的帧中丢失细粒度信息。
类似地,基本的时间聚合(temporal aggregation)技术(与temporal attention模型相比),average pooling或max pooling通常会削弱或过分强调判别特征的贡献(无论是按帧还是按区域)。在作者的实验中,作者在基于区域的基础上利用average或max pooling,发现max pooling效果更好。
与spatial attention相似,关于图片n的第k个空间成分的temporal attention tn,k定义为:
![]()
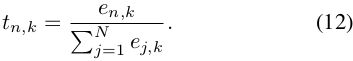
然后,通过加权平均,使用temporal attentions基于每个分量对增强的空间特征进行门控:

最终的判别性的区域的特征为:

最终的特征将上述时序门特征连接起来:
![]()
3.5. Re-Identification Loss
本文采用在线实例匹配损失函数(Online Instance Matching loss,OIM)[44]。通常,re-id使用多类softmax作为目标损失。因为batch中样本数量远小于训练数据集中的id数量,因此网络参数更新可能存在偏差。
在OIM中,使用了一个查找表来存储所有训练id的特征。在前向传播中,计算分类概率时,mini-batch会与所有id进行比较。
这种损失函数在训练re-id网络时比softmax更有效。
4. Experiments
4.1. Datasets
4.2. Implementation details and evaluation metrics
4.3. Component Analysis of the Proposed Model
4.4. Comparison with the State-of-the-art Methods
5. Summary
Reference
https://zhuanlan.zhihu.com/p/35460367
https://zhuanlan.zhihu.com/p/36379467