git的学习心得和知识总结 (从小白到熟练)
文章目录
- 简介
- 学习目标
- SVN和Git这种的区别
- GitHub注册
- Windows上安装git
- 在CentOS上安装git
- git常用操作命令和原理
- git的各阶段代码修改回退撤销操作
- git提交代码冲突解决实践方案
- git创建本地分支
- 本地分支合并冲突 解决方案
- git远程分支管理
简介
Git 百度百科:
Git:是一个开源的分布式版本控制系统(分布式仓库:现在的团队管理、托管资料以及代码都是放在这里),它可以有效、高速的处理从很小到非常大的项目版本管理。 Git 是 Linus Torvalds 为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。Torvalds 开始着手开发 Git 是为了作为一种过渡方案来替代 BitKeeper,后者之前一直是 Linux 内核开发人员在全球使用的主要源代码工具。开放源码社区中的有些人觉得BitKeeper 的许可证并不适合开放源码社区的工作,因此 Torvalds 决定着手研究许可证更为灵活的版本控制系统。尽管最初 Git 的开发是为了辅助 Linux 内核开发的过程,但是我们已经发现在很多其他自由软件项目中也使用了 Git。
学习目标
此次学习git的目标:理解其原理和一些命令。
一个问题:在开发项目的过程中,如果直接在本地系统上维护源码目录,不使用托管方式。则经常性会碰见下面的问题,都比较难解决 很费时间精力的:
- 不小心把源代码的目录或文件删了,写了好久的代码没了!
- 按需求添加新功能,写了好多代码,但净是编译错误,改都改不完,想回到之前的版本,开始大面积删除或者屏蔽代码,很崩溃,如果此时有个代码版本管理工具,该多好!毕竟之前的版本代码都在上面有所记录,可以很方便敲上简单的命令就可以回退到之前的某个状态。
- 新功能添加完了,编译运行一切很顺利,功能也正常,但有时候运行会出现以前没见过的运行错误,非必现的、难以复现的。想查看和之前代码的差异(本功能的前后版本的代码进行肉眼比较),看看都在哪些源文件中修改了代码,该怎么办?维护不同版本的代码的工具:Git。
- 团队开发项目,但是项目成员都不在一起,各自写的代码该如何添加到一块,还能避免错误,不会出现谁把谁的代码给覆盖了?虽然不同的成员开发不同的模块,但是不同模块的代码是一个文件之中,若是都去修改这同一个文件,那么怎么才可以把都修改的代码合并到一个文件当中呢?会不会出现谁把谁的代码给覆盖了?以及最终由谁来进行这个合并工作。
鉴于上面的问题:也就出现了很多代码版本控制工具,而git则是目前世界上最先进的分布式版本控制系统(对比集中式版本控制系统SVN)。
SVN和Git这种的区别
集中式版本控制系统SVN和分布式版本控制系统的区别:
- 前者集中式版本控制系统SVN,所有的版本控制(维护了代码的所有版本)都是放在了 SVN server(SVN仓库)上的,同一个团队的开发成员作为一个个的SVN client必须和服务器组成一个网络,然后通过网络访问,访问SVN server,SVN client才可以得到整个项目的所有代码版本。集中式版本控制系统 没有网络(或者 网络不通),那是肯定不可以的。所以就是说,各个 SVN client开发代码、创建不同的版本代码、分支创建等都是在 SVN server上做的;SVN client只是在做请求而已。如下图所示:

- 分布式版本控制系统:相当于每一个 团队成员都有一个自己的本地仓库(记录了所有在本地发生的 代码修改、创建新的分支、创建新的版本等),也即:每一个人都可以直接在本地就看到这个项目版本代码了。成员之间 彼此不需要进行通信联网,不需要组成一个网络,每个人都可以在自己的这个本地仓库上 代码编写、创建新的分支、创建新的版本,然后都提交到本地仓库就行。类似于 每一个git的工作区都可以看做是一个独立的版本控制系统,所以这也就是分布式的缘由,可以进行单独工作。但是毕竟这些团队成员都是参与、共同开发一个项目,最终项目的代码是要合并到一起的。虽然是不同的模块,但是涉及的代码都是在同一个文件之中,修改同一个文件 最终代码是要合并的。这个文件是 只有一份的(不需要每个人都维护一份),所以就需要一个代码版本托管平台 GitHub(远程仓库)。然后每一个团队成员统一地把自己的本地仓库的代码都提交到这个GitHub上创建的 远程仓库中。这个时候就可以进行代码的合并。

我们回头看一下这个分布式版本控制系统:开发的时候,每个人独立开发;最后合并的时候,往一起提交即可。把本地仓库代码同步到代码托管系统(远程仓库)当中,这样我们就可以通过网络来访问之前开发的各个代码版本了。而前面的集中式版本控制系统SVN在共同开发项目的时候, 则是需要在一个局域网中 开发:因为所有的代码版本控制都是发生在SVN server上面,最终提交的时候也只能去远程仓库提交。
GitHub注册
GitHub:一个免费的代码远程托管仓库 或者 代码版本托管系统。
git :团队每个开发人员的电脑上都可以看做是有一个代码管理仓库,但是团队协作的时候:最好是把这些代码都放到一个远程的代码托管仓库之中。

GitHub只是作为一个远程的代码托管仓库,作为开发人员 在开发的时候,需要在本地上的平台上进行开发,因此需要把这个CS_study这个远程仓库里面的代码 拉取到本地的系统之上。
而[email protected]:TsinghuaLucky912/CS_study.git 就相当于是这个拉取这个项目的地址,通过gitclone就可以拉去这个项目。
SSH 为 Secure Shell 的缩写,由 IETF 的网络工作小组(Network Working Group)所制定;SSH 为建立在应用层和传输层基础上的安全协议。SSH 是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议。利用 SSH 协议可以有效防止远程管理过程中的信息泄露问题。SSH最初是UNIX系统上的一个程序,后来又迅速扩展到其他操作平台。SSH在正确使用时可弥补网络中的漏洞。SSH客户端适用于多种平台。几乎所有UNIX平台-包括HP-UX、Linux、AIX、Solaris、Digital UNIX、Irix,以及其他平台,都可运行SSH。
Windows上安装git
git的本地客户端安装配置:
不解释了,自己学着安装吧!!!
安装成功之后,打开 Git bash(这相当于是Git的shell脚本编辑):git bash的目录管理实际上都是linux命令。我们可以给以后将要从远程仓库里面拉去的文件新建上一个目录:G:\github\git’s telefile
但是我们首先第一步要做的不是去拉取文件,而是git bash和git hub之间是通过ssh加密传输的,因此需要配置公钥。打开git bash,生成公私密钥,在git hub上进行公钥配置。
- ssh-keygen -t rsa -C “注册账号的邮箱名字” 生成SSH通信用的公私钥

- 生成完毕 公私密钥。在上面图片上标注的路径下,找到id_rsa.pub公钥文件,拷贝文件内容:

- 打开git bash,输入以下命令,测试和git hub是否能够通信成功,如下:
ssh -T [email protected]
这个命令:验证本地客户端通过ssh 公钥与远程的GitHub仓库,进行通信。以后就可以从远程仓库里面拉去文件 和 从本地推送文件。 - 配置邮箱和用户名,以后你在git hub上提交的任何代码文件,都会附带你的邮箱用户名信
息,然后告诉大家 这个功能是谁提交的 什么时候修改的。(相当于Git配置一下全局变量)如下:
以上就是这样了。
在Ubuntu上 配置这个基本上都是一样的,只不过需要第一步 安装Git 和 open-ssh。接下来Windows上一模一样(在本地现生成公钥文件,然后在GitHub上进行一个公钥文件的配置),配置成功就代表可以和一个客户端进行通信了。在此 劳资就不装了。OK 继续!
在CentOS上安装git
一句话:yum install perl openssh git OK(操作简单)
同理:但是我们首先第一步要做的不是去拉取文件,而是git bash和git hub之间是通过ssh加密传输的,因此需要配置公钥。打开git bash,生成公私密钥,在git hub上进行公钥配置。
- ssh-keygen -t rsa -C “注册账号的邮箱名字” 生成SSH通信用的公私钥
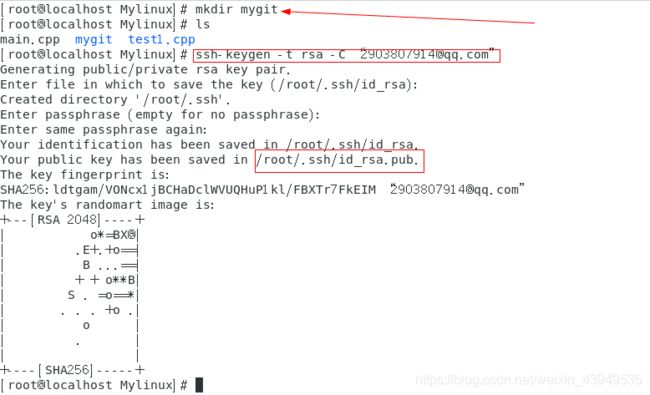
- 生成完毕 公私密钥。在上面图片上标注的路径下,找到id_rsa.pub公钥文件,拷贝文件内容:

- 打开centos ,输入以下命令,测试和git hub是否能够通信成功,如下:
ssh -T [email protected]

这个命令:验证本地客户端通过ssh 公钥与远程的GitHub仓库,进行通信。以后就可以从远程仓库里面拉去文件 和 从本地推送文件。 - 配置邮箱和用户名,以后你在git hub上提交的任何代码文件,都会附带你的邮箱用户名信
息,然后告诉大家 这个功能是谁提交的 什么时候修改的。(相当于Git配置一下全局变量)如下:
证明centos下git客户端连接github成功,最后配置git提交内容的用户名和邮箱信息:

git常用操作命令和原理
【step 1】在团队开发新项目时,项目负责人(或者是团队专门负责维护代码仓库的人)先在公司私有的代码仓库上创建了一个项目(这里就直接拿我刚才上面新建的那个仓库为例),如下:
项目名称就是 下面的 CS_study,在 Branch master那个地方有项目当前所在的分支

【step 2】项目负责人把上面项目的地址(如下:我们这个项目的SSH地址:[email protected]:TsinghuaLucky912/CS_study.git)分享给组内其它成员,大家拿到git地址后,在本地通过git clone把远程仓库上的项目代码拉到本地。作为项目组成员,可以在本地新建一个目录,专门存放该项目代码,通过git clone拉取远程代码,(这个就是我上面新建上一个目录:G:\github\git’s telefile)如下:

这时 我把这个readme.md 打开就是OK了。拉取文件到本地来 OK!
在这个本地项目的目录里面 可以使用git log,来查看当前这个分支master的提交记录。

在这里也可以使用 git remote 来查看一下:远程仓库的名称叫做 origin。如下:

注:
在本地会有两个东西会自动创建:
(1)远程的仓库名称:origin。这个名称就比较重要。因为我以后要向远程的仓库里面提交 代码的时候,git命令上使用的都是这个 远程仓库名称 origin,而不是我们上面的项目名称CS_study。CS_study就是项目的主文件夹,在git本地 标识远程仓库默认使用的都是origin。当然这个名字是可以修改的,如下:在./git 下面的config里面修改

(2)git作为一个分布式的版本控制系统,还生成了本地仓库(通过仓库来维护从远程仓库上面拉去的文件)。也生成了一个默认的主干分支:master。追踪的就是远程仓库origin的master分支。如下:


这里的分支,可以看做是代码的版本就可以了
于是总结一下:git clone做了以下几件事情:
- 把远程仓库的代码拉到本地
- 在本地也生成一个仓库
- 给远程仓库起了 一个名字叫做:默认就叫做origin。
- 然后在本地仓库默认生成一个主干分支 master。主干分支master,第一次clone下来就直接 生成了。这个主干分支master 就对应追踪的就是远程的origin的master分支,这个对应的追踪关系就已经生成了。
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
首先 我们就要去进行代码修改了,在 我的这个客户端1上,要去操作了。
我们一般都是在本地的项目文件目录中,直接去修改代码。这个git client只是作为代码版本管理的。如下:我们在那个目录下,写上这里一个文件。

我们只是提供了这么一个框架,具体实现没做。
然后 客户端1 这家伙完成任务了,就把这个东西上传了。

注:从远程仓库上面拉下来的项目 CS_study 这整个目录可以看做是git 的工作区。
先用 git status查看一下,然后把修改的代码都添加到本地的暂存区当中去。
git add . 是添加所有修改的;git add main.cpp是添加指定main.cpp 。




在这里,git add做的事情有:
把工作区的代码改动,提交到暂存区当中。因为改动可能有很多,不会一下子直接提交到本地仓库上来的。
到此为止,就可以提交了,并作出说明。

这里的本地仓库和远程仓库其实是一样的,功能也是一样的。由本地仓库来维护不同的代码版本(代码分支)。
再用一下 git branch 来打印一下状态:


意思就是说:远程仓库的master分支里面还只是有一个初始文件。on branch master,在本地的master分支上:由于一个新的提交 main.cpp,于是超前了远程的master分支。本地的内容比远的那个更加的新,所以你可以把这个本地的内容推送到远程中去。
把本地的叫做master的推送到 远程仓库的叫做 origin的master分支上面。




上面右边所说的 origin仓库就是:在本地上标识的一个远程仓库 CS_study项目仓库的名字而已。在 git client上用origin标识就是可以的了。
工作区的代码改动 通过多次的git add 来添加到 暂存区当中,就是人家是知道你有这么多的改动,先没有提交而已。在改动添加完了,commit 提交,-m再来点改动说明。提交到本地的工作分支上,可以通过 git branch来查看一下(前面有个*)。
git pull 的作用就是:另一个客户端 把远程仓库上的更新的代码,就拉取下来。更新代码,拉取代码。(之前没有更新的代码 好像不需要再去拉取)。

假如 这个客户端2的作用就是 实现上面的算法。如下:



然后 我们还可以在客户端1(song)上面执行 git pull


看一下 谁写的代码:

git clone命令的作用是,可以把指定的远程仓库代码拉取到本地
git add 把git工作区的代码改动添加到暂存区
git commit -m “xxx” 把暂存区的代码提交到本地分支
git push 把本地分支的代码推送(提交)到远程分支上去
git pull 把远程代码拉取到本地
git status 查看当前操作的状态信息
git log 查看代码修改日志,查看修改的过程。
工作区:当前存放项目代码的目录
暂存区:git add把工作区修改的内容添加到暂存区当中
本地仓库:git commit把本地暂存区的修改提交到本地代码仓库分支中(不同分支代表不同的代
码版本)
远程仓库:通过git push把本地仓库的某一个分支上的代码推送到远程仓库的某个分支上
HEAD指针:本地仓库每一个分支上的代码修改都会生成一个commit id信息,HEAD指针指向最
近一次的commit提交,通过这个commit id可以进行版本回退。head指针在版本回退中非常重要!在一个本地仓库的某一个分支上,git log 就记录了所有的提交的信息。每次的提交都会生成这么一个信息,commint 后面一长串的数字被叫做 提交id。后面的head 指针就指向了当前分支 最后一次的修改的地方。于是我们可以通过改动这个head指针,让head指针指向不同的commit id来 相当于切换这个当前分支上 不同阶段的代码版本上。

git的各阶段代码修改回退撤销操作
看看我们上面学习的,主要有:如下

在这4个阶段上,如果发生了 问题,如何在已经发生git操作之后,回退到前一步的状态呢?

暂存区:保存的是 现在git add的 添加的修改,且尚没有提交的内容。我们可以通过 git add多次 将要提交的修改 都保存在 暂存区里面。然后再通过 git commit 将暂存区里面的修改 提交到本地仓库。(git是个分布式版本控制系统,每一台机子上面都有一个 本地仓库管理),然后本地仓库通过 git push将本地仓库上的某个分支 代码推送到 指定的远程仓库 的某个分支上去。
现在通过 git status 查看:当前主干分支和远程仓库主干分支上是一致的。没有文件要去
提交,干净的工作区。

假如说我现在要 修改这个main.cpp 了(我在这个文件里面加了一句打印),然后git status查看

这个时候 我只是简单的修改了一下main.cpp, 还没有加到 暂存区。突然间这个 修改的版本代码不想要了,那么怎么直接恢复到 之前尚未修改的代码版本呢?(劳资不想 再编辑,一个一个 回退)?
这是第一种情况:本地工作区的代码修改,劳资不想要了,就可以使用git checkout - - main.cpp 完成回退
做法如下:

git checkout – main.cpp
意思就是用 本地仓库的master分支上的main.cpp 把劳资刚才修改的main.cpp给 覆盖掉。完成了和之前代码一样的回退。毕竟本地仓库的是干净的,尚未修改的

第二种情况:我把工作区的修改 给 git add了,添加到 暂存区了,可是劳资突然间又想 反悔了,不想要了,怎么搞?如下:


我已经add到 暂存区了,这种情况该怎么返回?我们可以通过 git add 多次进行将工作区的修改增加到暂存区里面。做法如下:

直接回退到,你的工作区代码 修改的还在。也就是劳资 骂小日本的那个代码改动还在,只是还没有增加到暂存区的那个状态了。(把提交到暂存区的代码改动给删了,又回退到工作区的这个代码改动过 上面去了。)于是 你就又可以快乐的 选择继续回退?还是继续提交的了?

于是 我在这里,愉快的骂了一句 小日本。继续 提交!!!
如下:

于是 第三种情况出来了:我把代码修改版本 从暂存区提交到本地仓库里面了
看看 上面 git status:你的本地仓库的master 领先于你的远程仓库的master分支。(因为劳资刚才咱不是在本地仓库里面提交了一个 这个吗?)
下面那句话的英语:咱给各位翻译翻译:你可以使用git push 来发布你的本地提交。
来 咱们一起看一下 git log:
并没有提交到远程仓库当中。其他人就算是更新,也最多更新到 现在远程仓库里面的那个版本的。也就是说 在这个时候,反悔了 不应该提交到我的本地仓库的,怎么恢复呢?
注意:在 git log里面,每一次的修改都是有一个记录的,那一长串的 commitid.
在仓库的每一个分支上,把每一次的修改提交都串到一条时间线上了。每一个修改的节点,都对应于一个commitid,那个HEAD 指向的就是最新的修改。于是想回退到之前的本地仓库的样子,如下:
如上图所示: 回退是成功了 可是劳资回退的 好像有点远。

其实上面的这个回退操作,什么也没有删除。只是把head指针的指向进行了调整。实现了 本地仓库里面不想要的那个 给回退掉了。
那我现在就想知道 怎么恢复我刚才的那个 骂小日本的那个版本呢?如下:
使用 git reflog :
也就是说,那些回退 其实也没有删除,只是把head指针移动了一下:本地仓库 不记录你新提交的,还是记住之前的老版本。
于是我睁着大眼睛并开心的:把这句代码 从本地仓库推送到 远程仓库里面了。我靠,出大事了。这下全世界人民知道我骂人了。日本鬼子的特工要找我了,怎么搞?怎么撤回呢?
而且 在我没有修改这句话的时候,把这个版本代码传送到远程仓库。团队的同志们 还更新了代码,他们要骂我了。(所以,以后在公司 本地的代码和资料等,都要多检查一下 没有问题了再发送到远程仓库里面)如下:
解决办法1:从本地代码修改开始,重新写。然后git add commit push 等重新走一遍。给同志们准备一套更好的代码!!!重新推出一套新的代码!
解决办法2:

也即:回退到了这一层

这个时候:

但是 直接就又更新:


你不能用一个落后的去更新人家一个新的(他不知道那特么是你提交的)。而且在 我刚才的提交还是处于最新状态的时候,我可以通过 -f 去强制提交成功。
那先去看一下 你的错误版本是不是最新的:
这个时候,也就是说:你刚刚向远程仓库提交的那个 被你的之前的旧的版本给覆盖掉了。也就是远程仓库回到了 你提交之前的状态。也即:本地仓库的回退,然后再强制 push,用本地仓库的东西给远程仓库的东西给更新一下,相当于 远程仓库进行了一次回退。
但是这里面有一件非常重要的事情:你在回退之前,一定要去确保 你是最新的提交。如果在你的错误 版本提交之后,有别人的提交,则 你再强制提交就把那个老哥的提交给覆盖掉了。相当于你俩都没有提交。
git checkout – 在git add之前,把工作区的代码用版本库中的代码覆盖掉,注意命令中的–不能
去掉,否则成切换分支的命令了
git reset HEAD 把git add之后,暂存区的内容全部撤销
git reset --hard commitid 把提交到本地仓库中的代码改动进行回退
git reflog 查看HEAD指针的改动日志
git push -f 强制推送本地仓库代码到远程仓库
git diff HEAD – 查看工作区file文件和仓库中该文件最新版本的代码有什么区别
关于这节课的第四种 代码回退的过程,我重新走一下:
- 我客户端1 客户端2同时得到一份文件
- 客户端1修改一下,然后发送给远程仓库
- 客户端1 用本地仓库回退强行更新 远程仓库。再看一下 客户端1所做的修改内容还在不在?
- 客户端2 能不能接收到这两次的消息推送?
执行 客户端1修改文件,发送远程仓库。这个时候,我在文件里面写有数据。
然后用 git reset --hard 144 回退本地仓库,然后检查 刚才那个工作区的文件书写内容 没有了
再使用git reflog得到id号, 再git reset – hard 271 返回 。刚才那个工作区的文件书写内容 回来了
我的总结:
- 但凡是向远程仓库push过的 都会由一个id号进行标识,而且这个文件也会被保存(所有的提交都会保存下来)。即使 使用git reflog得到id号, 再git reset – hard @ @ 返回到某一个时期的文件版本。可能工作区的数据内容发生了改变(或后面创建的文件没有 或之后代码的修改也没有),但是再次切换回来的时候,工作区的数据也会自动恢复。
- 此外 假如客户端2 做了修改(其实是出错了的代码),此时客户端1 pull一下。然后客户端2 回退本地仓库,并强制更新远程仓库。客户端2 的工作区数据发生了改变,但此时客户端1 再次pull 一下,客户端1的工作区的数据依旧是之前客户端2提交的错误数据,并不发生改变。即使此时的远程仓库的错误提交已被回退,且数据已被客户端2 强行修改(因为是客户端2 回退,所以远程仓库和客户端2 保持一致)。
git提交代码冲突解决实践方案
在进行团队开发之前,最好先进行一下 git pull,获取远程仓库最新的代码到相应的本地的分支上来。
上图的大致意思就是:origin/master 是远程仓库的master分支。客户端1 客户端2都从这个分支上面获取了v1这个版本的代码,假如客户端1 基于v1版本代码,修改开发出v2。并在本地仓库之中进行了更新,此时客户端1 想把这个v2push到 远程仓库里面。理论上 还是基于远程仓库的v1版本进行的开发,可以成功的(因为客户端1的 git status 要ahead 远程仓库,所以这是没有问题的)。但是现在问题就是 在这个版本更新的过程之中,其他团队成员也把自己的基于v1版本的 代码进行了push了,那么这个肯定也是会成功的。于是此时客户端1的push 就不会成功了。 如下:

不行的原因分析:因为git 会检测出:v2是由v1开发来的,但是远程仓库里面放的现在是v3(这定是别人的版本),所以v2不是基于v3开发的 所以不能push成功(产生冲突)。
此时两个 都更新了远程仓库的代码:
客户端1给 main.cpp的主函数添加注释;并提交到本地仓库。如下:

本地仓库已经有了一个新的提交,远程仓库落后了

但是此时 客户端2 负责的给main.cpp的sort方法添加注释的任务完成,并更新了远程仓库。这个是直接基于远程仓库的版本进行的更新,当然直接push成功。如下: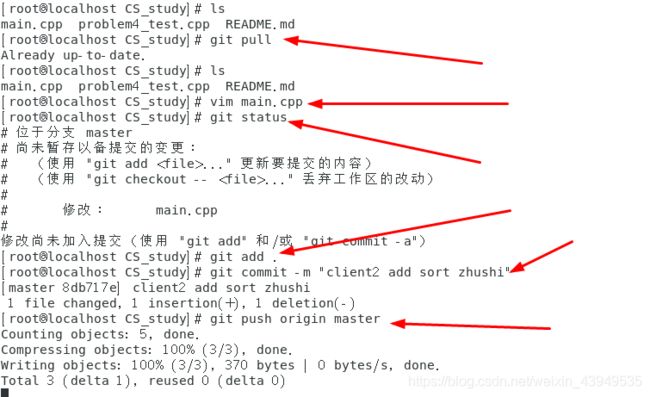
此时客户端1 去远程仓库传送数据了:如下
失败:本地仓库的这个是基于v1版本更新的,而现在远程仓库里面不是v1版本了,而是客户端2 提交的新版本了。
解决办法:再更新一下代码

我们来看一下:现在的main.cpp 。
因为这两处修改都不是在同一个地方,所以说在直接进行合并的时候 也不会出现冲突。两个人的工作也都被保存下来了。于是呢 此时客户端1 再重新push就可以了。
来,走去GitHub上面瞅一眼结果:

完美解决问题,然后我们去客户端2 再拉去一下文件 看看:

上面修改的不是同一个模块的,所以说不是一处,人家重新拉取的时候 可以完美进行merge,再次push 就可以解决问题了。但是如果俩人修改的是同一处地方呢?

并提交远程仓库:
此时客户端2 也在这处添加自己的内容:
如上 客户端2 再次提交就出错了。那我们试一下 上面的解决方法:先拉去新的,让它自动merge,然后再push。如下:
像这种情况:就只能去 自己手工修改了。先看一下文件:
head指向 当前客户端2本地分支最新的修改。后面的那个commitid 是客户端1 提交的id号。于是合并失败,只能把文件合成这个样子了。于是需要手工解决了:如下:
OK 解决问题:
git创建本地分支
使用git,最好是多建立分支,然后在分支上进行新功能的开发与测试。当开发结束,测试没问题的时候 再把这个开支上的新功能的代码给合并到指定的代码仓库之中。
git branch 查看的是本地的分支,git branch -r 则是查看远程的分支
如上图:本地分支前面的 * 表示 当前工作在本地仓库的 某个分支之上;远程的分支 也只有origin仓库里面的master分支。对应的就是GitHub上的CS_study这个项目的master分支。
git branch -a 则是两个一起查看。
git branch -vv 则是追踪着远程的origin/master

比如:需求:
之前代码的sort算法是一个冒泡排序,时间复杂度太高。变更成为快排
做法1就是:直接在本地的master分支上修改
做法2就是:不影响master的代码,再建立一个分支。在这个新分支上,不仅可以随便操作,而且不影响本地的master和远程仓库的分支的追踪关系。(git branch -vv 可以查看)只有当这个新分支的代码功能测试稳定之后,再往本地的master分支上 放,最后才push到远程仓库的master分支上。
在本地创建分支并切换到当前分支下面了。如下:

其实log内容并没有发生改变,但是head指向了新分支。

HEAD 指针指向的是当前分支最新更改的记录,也即head指向了新分支了。其实还是原来的代码,并没有发生改变。
我们想要去 拉取代码,可是人家并不知道该从哪里拉取。原因如下:

如上图所示:本地的master分支,追踪的是远程仓库 origin/master分支(所以在master分支上git pull的时候,人家是确切知道在远程仓库的哪个分支拉取的),而本地新创建的新分支并没有对应上远程仓库的某一个分支(它仅仅是本地仓库的一个分支,和其他的人没有任何关系 故而可以随便使用、增加、测试代码)。这一点也体现出git作为一个分布式托管系统的理念:在客户端的本地也可以维持一个git仓库(以提交用户所更改的代码,以及在合适的时候 可以完成从本地到远程仓库的push)。
我们切换回 master分支的做法:(注意看括号里面的内容)


再次创建,因为是已存在的分支,失败。
好了 ,我们开始在新的分支上面搞事情吧。

修改代码去:把冒泡 变成 快排
#include 

如上图所示:现在提交 只能提交到 本地的新分支newlocalbranch1 的仓库里面了。但是现在 push到master 上去,是不行的。原因如下:
在最开始git clone的时候,在本地仓库CS_study 创建起来之后,就有这么一个master分支去追踪了远程仓库的master分支上了。而新建的普通的分支不存在这种 追踪关系,也即没有任何的远程追踪仓库的分支(这个追踪关系也是可以创建的)。所以说 这里的git push 没有任何的意义

如上:现在根据这个新的分支开发的v5版本(也就是基于v4进行的开发),而master分支还是在v4版本上。
然后我们觉得这个新分支上代码可以了,然后切换到master上,进行操作 如下:

然后就需要在 本地的master分支上 进行merge操作,把新分支上的代码修改 merge到master分支上来。毕竟 看上面的那个图,我们的新分支代码版本毕竟也是从master分支的基础上开发的,所以此时切换到 master分支上 进行合并的时候 就是 直接让master分支 指向新分支代码版本上即可。如下:

我们去看一下现在 master下的工作区代码是不是我们刚写的那个快排?

注:git diff 是查看工作区 和 本地仓库的代码的不同。
当我们在上面切换到 master分支的时候,使用了 git merge 就直接把新分支上的代码修改 merge到本地的master仓库上来了,此时工作区的代码和本地仓库master分支里面的代码是一样的。于是:
也就是:本地的master仓库还提前于远程仓库的master分支
此时:就可以进行向远程仓库的push


看上下这两个图:推到远程仓库上去 之后,HEAD就指向了 master。

其实这个操作 是和直接在master分支上 代码修改操作是一样的,只不过这样就不会影响master分支的代码了。作为分布式系统,在本地仓库可以任意的创建分支,且分支不对应远程仓库的任一个分支 ,于是就可以随意使用了。代码写错了 或者 分支不再使用了,直接进行删除就OK了。如下:
注意:如果这里基于master分支新建了一个分支,在这个分支上 修改了代码。再切换回master之后,如果没有把这个新分支的代码给合并到master分支上,-d是删除不了的(它会提示你:你的新分支上还有更新的代码,没有合并到当前分支来 不能直接删除。)劳资非要删除:- D,无论有没有合并 劳资不要了。
接下来:创建新分支 并切换到这个新分支上

修改了一下 :readme文件。
master分支被称为是 开发分支。
在刚才的做法上:在push远程仓库时,应该切换到本地的master分支,然后master分支更新一下新分支代码,接着才可以进行本地的master分支代码push到远程仓库的master分支。但是现在处于newlocalbranch2分支上 也是可以直接将代码 推送到远程 指定仓库的指定分支上。如下:将newlocalbranch2代码 推送到远程 指定仓库origin 的指定分支master分支上。

虽然这个普通的新分支没有追踪什么远程仓库的分支,但是可以直接将代码 推送到远程 指定仓库的指定分支上的(不指定不可以)。
于是:
然后更新一下:

这里 我删除新分支2 采用-d 的方式,大家猜一下 会不会成功?

本地分支合并冲突 解决方案
创建本地分支,在分支合并的时候产生冲突:类似于上上一节内容,解决冲突的最终方式:手工解决冲突,然后再进行push。在出现冲突的时候,需要了解代码的逻辑。然后在不同的版本下,把代码合并到一块,合并成正确的代码就可以。
本地分支合并冲突是什么:在本地创建分支,在新分支上进行开发、测试。最后切回开发分支上,把新分支的代码修改 合并到开发分支上,最后推送到远程仓库即可。(这个过程可以merge成功的原因:因为sortdev01分支在合并的时候,master分支没有做过任何改动)
在master分支上 直接创建本地新分支,这个新分支还是工作在原先的版本迭代过程中的,然后在新分支上 进行了开发。然后切回开发分支上,把新分支的代码修改 直接就可以合并到开发分支上(因为master分支没有做过任何改动)。这个合并也就相当于 master分支的代码也就变成了最新的代码修改,head指针指向master了 毕竟head指针指向了最新的修改。
但是实际上有可能发生这样的情况:
- 客户端1从master分支创建了一个本地新的分支sortdev01,进行代码开发测试,提交。此时客户端1 尚未进行新分支的代码修改 push到远程仓库(或者说 与本地master分支进行合并)。
- 客户端2率先更新了远程仓库的master分支上的代码
- 客户端1切换分支到master(原master版本上),合并代码前先git pull 一下,同步远程仓库master主干的最新代码,发现有变化。此时master也就不是原master了。也即:出现了下图的第2个 的冲突:此刻的master分支(已经发生了改动:有客户端2已经新添加的代码内容)和新分支sortdev01就是两个完全不同的更新了。
- 客户端1在直接git merge sortdev01,也即切回开发分支之后,想把新分支的代码修改 直接合并到开发分支上就发生冲突了。

解决方法:(此时的master分支处于sortdev01头上的那个)方法就是手工解决,然后由客户端1进行push远程仓库origin的master。(push之后的master分支处于sortdev01右边的那个最新的)
具体如下:在进行本地分支合并的时候,若是远程仓库有代码的更新,本地分支就会产生冲突。
这两步相当于:git branch -b sortdev

此时 咱们去修改readme文件(在当前本地仓库的sortdev分支上 修改成为新版本)
(如果客户端2 没有进行新提交,客户端1就算是 git pull 也没有更新)那我们就直接:
但是他更新了,继续

这个时候 尚未进行切换master, 然后本地分支代码的合并。
客户端2 进行修改,然后还push远程仓库了。
然后客户端1 要进行一个git pull,把master分支代码更新一下:(你的master落后于 远程仓库的master一个提交)理应在最新的代码之上进行更新。

确实 客户端2进行的修改提交:
此时要进行 merge,肯定会出错(因为两个人修改的是同一块地方)如下:
上图中:head指向的是 从远程仓库里面更新来的客户端2进行的修改内容,而本地自己的sortdev分支修改的是111111.
(若是不同模块的修改,自动合并 可以正常进行)整个过程如下:
这个冲突 其实和上上节的一样 :需要手工解决了。重新合并(合并成一个最终版本),然后再推送到远程仓库。

走 我们去看一下 客户端2有没有问题:
一切OK

这就是手动解决,重新提交:在创建本地分支,进行本地分支合并的时候。由于其他人又更新了 开发分支上的代码(新的提交)。在切换本地 开发分支,将其他分支代码合并过来的时候,发生的冲突。
git远程分支管理
一个项目的工程量是很大的,不可能一下子完成,而是迭代开发。根据上一代的经验教训,以及更加新的项目需求 来进行一代又一代的功能开发。在开发新一代功能的时候,上一代产品毕竟是经过了 长期开发、测试、发布 上线,不可能直接在这个已经稳定的代码上 做修改或增加。(不能够去影响原来的版本代码)也就是不可能在只有一个 分支上进行迭代开发的,这不现实。
所以在进行不同时期的功能迭代的时候,项目负责人会 关闭一期的master分支(可以查看,不可以再进行上传),然后以之前的master 主干分支为基础,新创建一个开发分支dev。不同时期的开发就可以创建不同的新的开发分支进行操作,新分支的代码修改,并不会影响之前分支的运行(就可以保证之前分支的功能稳定性)。
其实也是可以在本地的客户端上,通过命令来创建这么一个远程分支。(不过在公司,你的权限也还不够的)所以就在项目负责人创建新分支之后,进行pull 拉取,如下:

远程仓库的名字就是那个 origin,新的分支dev。
查看分支:远程有两个分支。
本地分支和远程仓库分支的映射关系 如上:本地的master分支 追踪着远程的origin/master。
废话不多说了,二期的开发开始了!!!!如下:(将在dev分支上进行开发)

就不能够在master上开发了(追踪的是origin/master,包括pull的时候还是从master上拉取的),于是就得创建一个新的分支了。如下: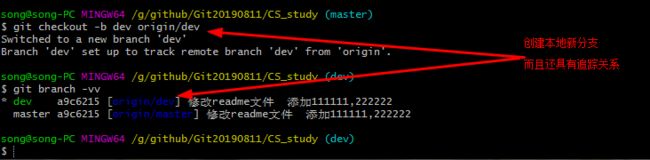
这里创建新分支的时候(最好和远程的新分支名字一样,这样以后用起来方便,且少写很多命令),并且将这个追踪关系进行绑定。如上图所示:
此时本地仓库的dev分支(创建之后就切换了),追踪的是远程仓库的dev分支。这个git pull就没有问题了,(若是创建分支,但是没有这个追踪关系,它不知道从远程仓库的哪个分支去给这个新创建的本地分支更新代码。)

最后的push :就是将本地分支dev上面的代码 推送到远程的dev分支上。如果是你起的名字和远程分支不一样,操作就得如下:

现在我们创建的名字相同,于是就把上面的那个localdev这个给去掉了,当然我们也没有这个东西嘛。
此时我们可以回头看一下 上一期的master分支:看看内容变了没有?应该是不变的

因为现在远程仓库里面有两个分支,于是项目的不同的迭代的代码版本,就可以放到不同的仓库里面。
创建远程分支和删除远程分支一般员工是没有权限的,所以此处的命令就不罗列了,大家感兴趣
可以在网上查阅,这个操作只能由管理员来执行。如果是搭建自己的git私服代码托管,那就可以
随便折腾了
- 查看远程仓库名称:git remote 一般远程仓库默认的名字是origin
- 查看本地分支名称:git branch
- 查看远程分支名称:git branch -r
- 查看本地分支和远程分支的追踪关系:git branch -vv
- 创建本地分支并指定追踪哪个远程分支:git checkout -b <本地分支名> <远程仓库名>/<远程分支名>
- 设置已经存在的本地分支追踪哪个远程分支:git branch -u <远程仓库名>/<远程分支名>
第6点演示如下:
总结:如果遇到不会的,多使用一下CSDN等知名博客 自行查找,也增加自己的动手能力!!!

常见常用的命令基本上 如上。OK,本次 git的使用学习与分享到此OK。