16S扩增子分析 | 02 去噪和聚类
读前须知
nohup 后台运行
nohup后台运行时,要将qiime2-2019.7环境激活,否则会报错!一定要记得激活!激活!激活!
nohup bash 01.sh &
nohup指不间断地运行,是no hang up的缩写。当运行一个进程的时候,不想让其在你退出账号时关闭,即可用nohup。nohup在不规定的情况下,所有输出内容会保存到nohup.out中。
后缀&是让程序后台运行,但注意,后台运行不代表不受SIGHUP信号影响,连接断开的话依然会终止任务。
代码解读
nohup python my.py >> /usr/local/python/xxf/my.log 2>&1 &
以python环境不间断的运行my.py这个脚本,并且将脚本的输出内容重定向输入my.log中(>>意为追加,如果用>会让其中的内容清空)
0 表示stdin标准输入,用户键盘输入的内容
1 表示stdout标准输出,输出到显示屏的内容
2 表示stderr标准错误,报错内容
my.py >> my.log 和 my.py 1>>my.log 相同,只是1(标准输入)被省略了,而后面的2>&1是一个整体,>左右不能有空格,即将错误内容重定向输入到标准输出中去,意思错误和标准内容都会输出到my.log中。
注:dada2,phylogeny,taxonomy,ancom,由于运行时间较长,都应该使用nohup后台提交。(99个样本-198个fastq文件,前三个运行一夜,最后一个运行x天。)
提交任务后,
jobs:查看当前任务,但jobs命令只看当前终端生效的,关闭终端后,在另一个终端jobs已经无法看到后台跑的程序。
top -u 用户名:查看当前用户提交的后台任务,在当前界面按c键,可查看具体操作内容command(PID-任务号;RES-数据量大小;TIME-运行时间)
kill -9 任务号:杀死程序
ll -l:查看当前目录下文件的所有信息,包括大小等
clear:清屏幕
shell 前代码
export LC_ALL=C.UTF-8
export LANG=C.UTF-8
conda activate qiime2-2019.7
可在每个shell代码前加入上面代码,以防止中英文乱码,同时激活qiime2环境。
在Linux中通过locale来设置程序运行的不同语言环境,C"是系统默认的locale,"POSIX"是"C"的别名。所以当我们新安装完一个系统时,默认的locale就是C或POSIX。locale的命名规则为<语言>_<地区>.<字符集编码>,如zh_CN.UTF-8,zh代表中文,CN代表大陆地区,“UTF-8” 是一种字符编码。即正常显示中文。
LC_ALL:它是一个宏,如果该值设置了,则该值会覆盖所有LC_*的设置值。注意,LANG的值不受该宏影响。LC_ALL=C 是为了去除所有本地化的设置,让命令能正确执行。
LANG(language):LC_*的默认值,是最低级别的设置,如果LC_*没有设置,则使用该值。类似于 LC_ALL。LANG=C:C对应ASCII编码,这也是很多shell脚本中喜欢设置该环境变量的原因,通常用于解决系统乱码问题。
去噪和聚类
常用插件:Deblur和DADA2(DATA2更为常用,优点见下:)
(1)分析之前无需进行质量过滤;
(2)无需进行内部嵌合体检查方法和丰度过滤;
(3)去噪期间自动对双端序列进行了合并;
(4)校正不确定序列中的错误;
(5)可直接产生 feature-table,即OTU表。
注:如果使用q2-debur或OTU聚类方法,则需要先使用q2-vsearch进行双端合并;deblur分析之前必须进行数据质量过滤;Deblur和DADA2都包含内部嵌合体检查方法和丰度过滤,因此不需要额外的过滤。
qiime dada2 denoise-paired \
--i-demultiplexed-seqs demux.qza \
--p-trunc-len-f 245 \
--p-trunc-len-r 245 \
--o-table table.qza \
--o-representative-sequences rep-seqs.qza \
--o-denoising-stats denoising-stats.qza \
--p-n-threads 24
用于质量过滤的参数:
–p-trim-left m,去除每个序列的前m个碱基(如引物、标签序列barcode)
–p-trunc-len n,在位置n截断每个序列
–p-trunc-len-f(正向序列)–p-trunc-len-r(反向序列)
简单来说,–p-trim-left 0 指去除左端 0 bp,有时用于切除低质量序列、barocde或引物;—p-trunc-len 120 序列切成 120 bp 长。
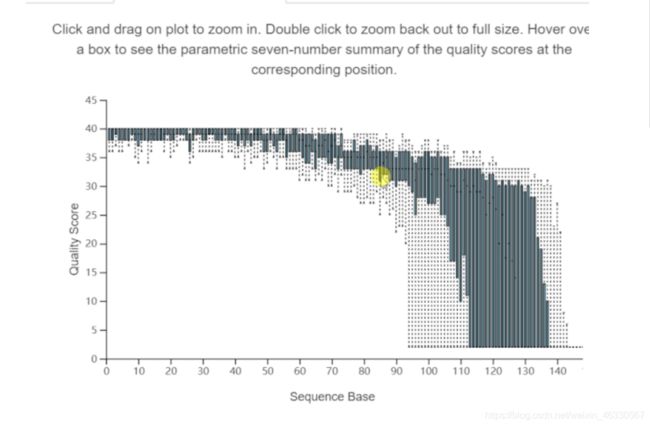
对于参数的选择,应参考demux.qzv文件中的交互质量图。
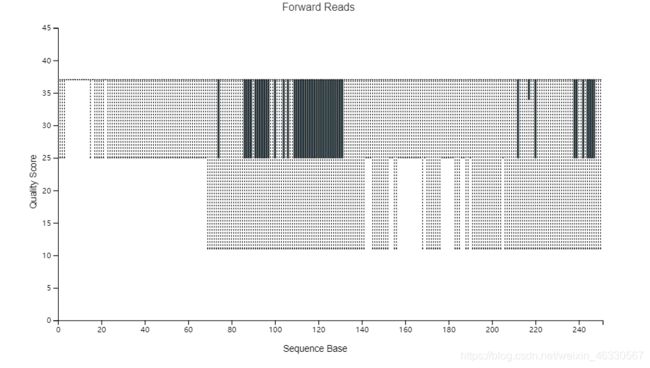
参考示例:
—p-trim-left 截取左端低质量序列,我们看上图中箱线图,左端质量都很高,无低质量区,设置为0;
—p-trunc-len 序列截取长度,也是为了去除右端低质量序列,我们看到大于120以后,质量下降极大,甚至中位数都下降至20以下,需要全部去除,综合考虑决定设置为120。
#去噪过程统计数据可视化
qiime metadata tabulate \
--m-input-file denoising-stats.qza \
--o-visualization stats.qzv
qiime tools extract \
--input-path stats.qzv \
--output-path stats
#查看feature表统计结果
qiime feature-table summarize \
--i-table table.qza \
--o-visualization table.qzv \
--m-sample-metadata-file metadata.tsv
#代表序列统计
qiime feature-table tabulate-seqs \
--i-data rep-seqs.qza \
--o-visualization rep-seqs.qzv
metadata.tsv这个文件是自己编辑的,采用复制粘贴的方式,而不是直接上传,否则会显示二进制文件无法查看。复制粘贴后第一行容易消失,注意检查。

输出结果
stats.qzv 去噪过程统计
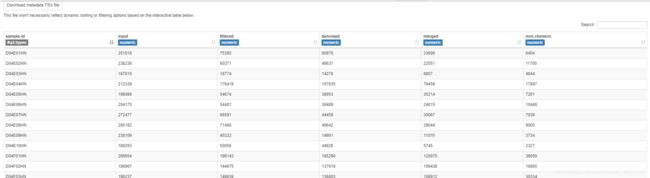
input 输入数据;filtered 过滤后的数据;denoised 去噪后的数据;non-chimeric 去除嵌合体后的数据
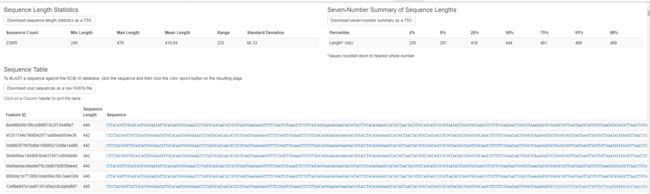
table.qzv 特征表
1. 特征表的统计结果
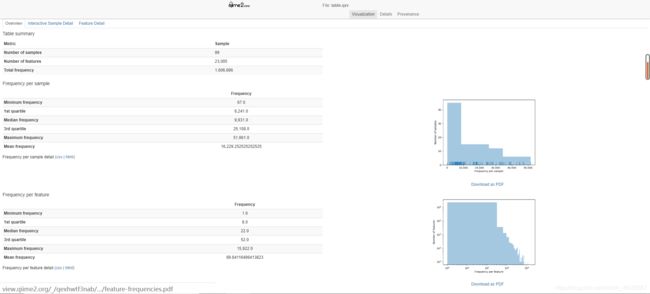
上方为摘要
中间为样本数据量分布表和图
下方为特征出现频率的统计表和图
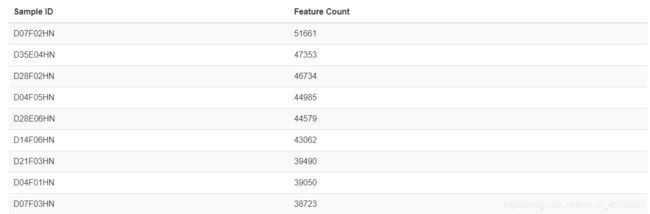
2. 交互式查看每组剩余特征量
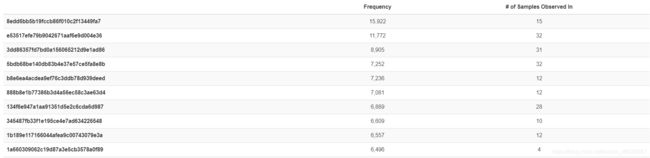
3. Feature Detail 进一步查看每个特征的频率和在样本中出现的次数
rep-seqs.qzv 代表序列