新旧Java MapReduce API的差异
摘录自 Hadoop权威指南
1、版本区别
Hadoop在0.20.0版本中第一次使用新的API,部分早期的0.20.0版本不支持使用旧的API,但在接下来的1.x和2.x版本中新旧API都可以使用。
新旧API的差异主要有以下几点:
1. 新的API放在org.apache.hadoop.mapreduce包(和子包)中,旧的API放在org.apache.hadoop.mapred中。
2. 新API倾向于使用 抽象类,而不是接口,更有利于扩展。
3. 新API充分使用上下文对象context,允许用户能与MapReduce系统通信。例如,新的Context统一了旧API的JobConf、OutputCollector和Reporter的功能。
4. 键/值对记录在这两类API中都被推给mapper和reducer,除此之外,新的API通过重写run()方法允许mapper和reducer控制数据执行流程,允许数据按条处理或者分批处理。老的api只在map中允许。
5. 新的API中作业控制由Job类实现,而非旧API中的JobClient类,新的API中删除了JobClient类。
6. 新增的API实现了配置的统一。旧API通过一个特殊的JobConf对象配置作业,该对象是Hadoop配置对象的一个扩展。在新的API中,作业的配置由Configuration来完成。
7. 输出文件的命名方式稍有不同。在旧的API中map和reduce的输出被统一命名为part-nnmm,但在新的API中map的输出文件名为part-m-nnnnnn,而reduce的输出文件名为part-r-nnnnn(其中nnnnn是从0开始的表示分块序号的整数)。
8. 新API中的用户重载函数被声明为抛出异常java.lang.InterruptedException。这意味着可以用代码来实现中断响应。
9.在新的API中,reduce()传递的值是java.lang.Iterable类型的,而非旧API中传递的java.lang.Iterator类型。这一改变使我们更容易通过java的for-each循环结构来迭代这些值。
2、注意问题
如果基于hadoop1版本的打的jar包,在hadoop2下可能会报如下错误:
java.lang.IncompatibleClassChangeError: Found interface
org.apache.hadoop.mapreduce.TaskAttemptContext, but class was expected
只需要将代码用hadoop2的依赖重新编译打下jar包
3、新版版本代码区别示例
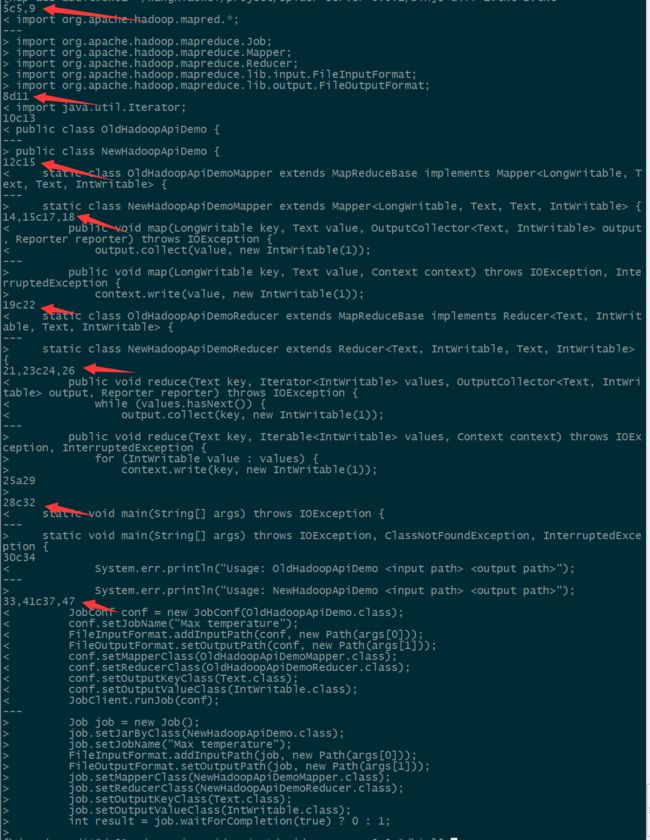
4、示例代码-老版API
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.*;
import java.io.IOException;
import java.util.Iterator;
public class OldHadoopApiDemo {
static class OldHadoopApiDemoMapper extends MapReduceBase implements Mapper
@Override
public void map(LongWritable key, Text value, OutputCollector
output.collect(value, new IntWritable(1));
}
}
static class OldHadoopApiDemoReducer extends MapReduceBase implements Reducer
@Override
public void reduce(Text key, Iterator
while (values.hasNext()) {
output.collect(key, new IntWritable(1));
}
}
}
static void main(String[] args) throws IOException {
if (args.length != 2) {
System.err.println("Usage: OldHadoopApiDemo
}
5、示例代码-新版API
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class NewHadoopApiDemo {
static class NewHadoopApiDemoMapper extends Mapper
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value, new IntWritable(1));
}
}
static class NewHadoopApiDemoReducer extends Reducer
@Override
public void reduce(Text key, Iterable
for (IntWritable value : values) {
context.write(key, new IntWritable(1));
}
}
}
static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
if (args.length != 2) {
System.err.println("Usage: NewHadoopApiDemo