为什麽我们一般会在自增列或交易时间列上建立聚集索引?
到新公司上班也有一段时间了,感觉现在的自己才开始慢慢学习SQL~
看这篇文章之前,大家可以先看一下我之前写的一篇文章
聚集索引表插入数据和删除数据的方式是怎样的
一般的交易系统里面我们都会以自增列或交易时间列作为聚集索引列,因为一般这些系统都是写多读少
每天的交易数据会不停的插入到数据库,但是读取数据就没有数据插入那么频繁
因为这些系统一般是写多读少,所以我们会选择在自增列或交易时间列上建立聚集索引
测试
测试环境:SQLSERVER2012 SP1 WINDOWS7 64位
我们来做一个测试,测试脚本如下:

1 --测试脚本 插入性能 2 USE [test] 3 GO 4 --建表 以transtime为聚集索引列 5 CREATE TABLE transtable(tranid INT ,transtime DATETIME) 6 GO 7 CREATE CLUSTERED INDEX CIX_transtable ON [dbo].[transtable]([transtime]) 8 GO 9 10 --建表 以tranid为聚集索引列 11 CREATE TABLE transtable2(tranid INT ,transtime DATETIME) 12 GO 13 CREATE CLUSTERED INDEX CIX_transtable2 ON [dbo].[transtable2]([tranid]) 14 GO 15 16 17 ---------------------------------------------------------- 18 --先插入测试数据,插入的tranid都为基数 19 DECLARE @i INT 20 SET @i = 1 21 WHILE @i <= 1000000 22 BEGIN 23 INSERT INTO [dbo].[transtable] 24 SELECT @i , GETDATE() 25 SET @i = @i + 2 26 END 27 -------------------------------------- 28 DECLARE @i INT 29 SET @i = 1 30 WHILE @i <= 1000000 31 BEGIN 32 INSERT INTO [dbo].[transtable2] 33 SELECT @i , GETDATE() 34 SET @i = @i + 2 35 END 36 37 -------------------------------------------
在transtable表上的transtime(交易时间)上建立聚集索引,在transtable2表上的tranid(交易编号)上建立聚集索引
我们分别在两个表上插入500000条记录,插入的时候有个特点,就是插入的tranid都是基数
1 SELECT COUNT(*) FROM [dbo].[transtable] 2 SELECT COUNT(*) FROM [dbo].[transtable2] 3 4 SELECT TOP 10 * FROM [dbo].[transtable] ORDER BY [tranid] 5 SELECT TOP 10 * FROM [dbo].[transtable2] ORDER BY [tranid]
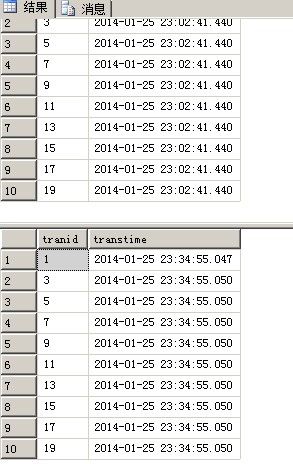
我们创建两个存储过程,这两个存储过程为插入到表数据


1 -------------------------------------------- 2 --创建两个存储过程 3 CREATE PROC INSERTTranstable 4 AS 5 DECLARE @i INT 6 SET @i = 1 7 WHILE @i <= 1000 8 BEGIN 9 IF ( @i % 2 = 0 ) 10 BEGIN 11 INSERT INTO [dbo].[transtable] 12 SELECT @i , 13 GETDATE() 14 SET @i = @i + 1 15 END 16 ELSE 17 BEGIN 18 SET @i = @i + 1 19 CONTINUE 20 END 21 END 22 ------------------------------------------ 23 CREATE PROC INSERTTranstable2 24 AS 25 DECLARE @i INT 26 SET @i = 1 27 WHILE @i <= 1000 28 BEGIN 29 IF ( @i % 2 = 0 ) 30 BEGIN 31 INSERT INTO [dbo].[transtable2] 32 SELECT @i , 33 GETDATE() 34 SET @i = @i + 1 35 END 36 ELSE 37 BEGIN 38 SET @i = @i + 1 39 CONTINUE 40 END 41 END 42 -----------------------------
测试脚本,测试一下插入到两个表的时间
1 测试插入偶数行的性能 2 DECLARE @a DATETIME 3 DECLARE @b DATETIME 4 SELECT @a=GETDATE() 5 EXEC INSERTTranstable 6 SELECT @b=GETDATE() 7 SELECT @b-@a 8 -------------------------------------- 9 10 DECLARE @c DATETIME 11 DECLARE @d DATETIME 12 SELECT @c=GETDATE() 13 EXEC INSERTTranstable2 14 SELECT @d=GETDATE() 15 SELECT @d-@c
验证一下偶数的交易编号是否已经插入到两个表中
1 SELECT TOP 10 * FROM [dbo].[transtable] ORDER BY [tranid] 2 SELECT TOP 10 * FROM [dbo].[transtable2] ORDER BY [tranid]

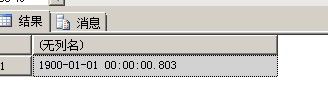
我们看一下时间
第一个表
第二个表
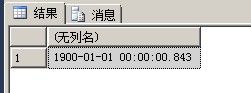
很明显,第一个表比第二个表快,因为的机器的硬盘是固态硬盘,时间差距不是很大,如果是机械硬盘时间差距会大一些,那么究竟为什麽会造成这种情况呢?
我们用下图来解析一下
我们先说第二张表
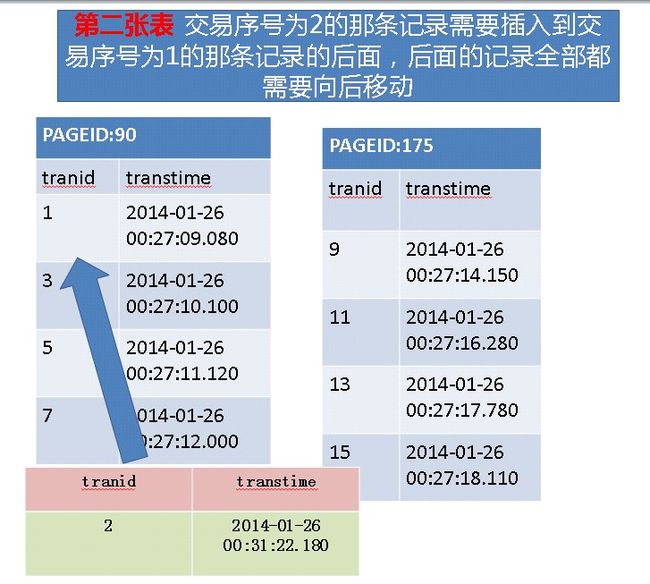
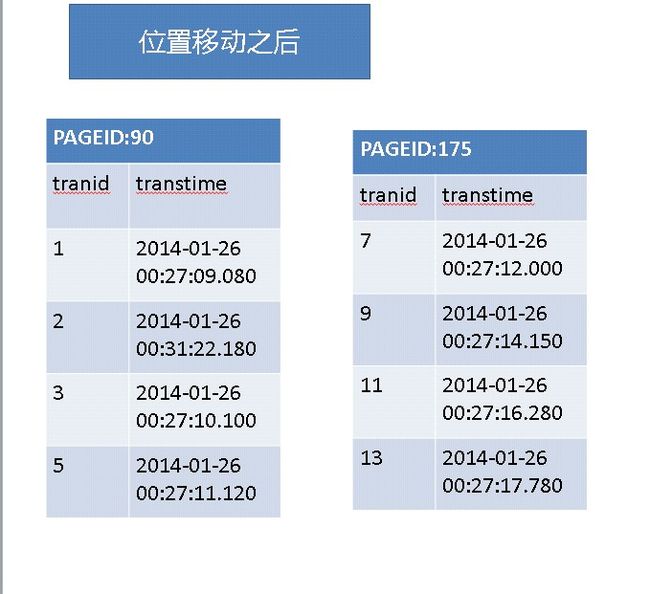
当交易编号为2的那条记录插入进来的时候,后面的记录都需要向后移动,以使交易编号从小到大排序,因为聚集索引建立在交易编号列上
这个移动时间是有开销的,而且每次偶数交易编号插入到表中,每插入一次就移动一次,而当前面的记录插入到表中的时候移动的记录数就越多
例如:tranid:2,transtime:2014-1-26 31:22.180插入到表中的时候后面的记录都需要移动,而tranid:978,transtime:2014-01-26 00:29:10.830
这条记录插入到表中的时候,后面需要移动的记录数就没有那么多,总之那个开销挺大的。。。
第一张表的情况
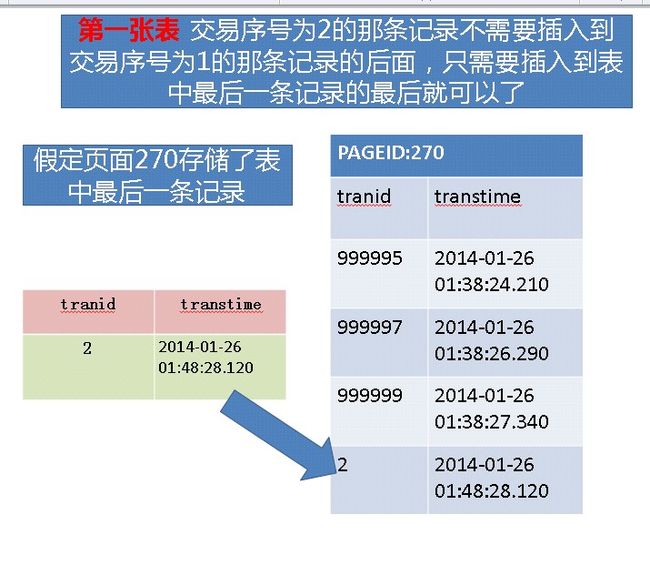
因为第一张表是以交易时间为聚集索引列的,所以无论交易编号是多少,记录都会插入到表的最后,因为后来的记录的交易时间肯定比前面的记录的交易时间大
这样的话,基本上没有开销
现实系统中的情况
实际系统中,新生成的要插入到表中的交易编号是有可能小于当前表中的某条记录的交易编号的,那么这时候记录插入到表中就需要移位(如果聚集索引建立在交易编号上)
如果聚集索引建立在交易时间上,那么新生成的要插入到表中的交易记录时间肯定会大于当前表中的任何一条交易记录的时间
(除非人为修改系统时间造成当前时间比数据库中的某些记录的交易时间要早)
总结
前公司的数据库有些表在自增列,有些表在交易时间列上建立了聚集索引,在交易时间列上建立聚集索引个人觉得很正常
因为在查询的时候按照交易时间来排序《order by 交易时间》,速度上是很快的,但是除了排序之外还有一个作用就是本文所讲到的
插入数据到表中的效率问题
本次实验用到的完整脚本
1 --测试脚本 插入性能 2 USE [test] 3 GO 4 --建表 以transtime为聚集索引列 5 CREATE TABLE transtable(tranid INT ,transtime DATETIME) 6 GO 7 CREATE CLUSTERED INDEX CIX_transtable ON [dbo].[transtable]([transtime]) 8 GO 9 10 --建表 以tranid为聚集索引列 11 CREATE TABLE transtable2(tranid INT ,transtime DATETIME) 12 GO 13 CREATE CLUSTERED INDEX CIX_transtable2 ON [dbo].[transtable2]([tranid]) 14 GO 15 16 ---------------------------------------------------------- 17 --先插入测试数据,插入的tranid都为基数 18 DECLARE @i INT 19 SET @i = 1 20 WHILE @i <= 1000000 21 BEGIN 22 INSERT INTO [dbo].[transtable] 23 SELECT @i , GETDATE() 24 SET @i = @i + 2 25 END 26 -------------------------------------- 27 DECLARE @i INT 28 SET @i = 1 29 WHILE @i <= 1000000 30 BEGIN 31 INSERT INTO [dbo].[transtable2] 32 SELECT @i , GETDATE() 33 SET @i = @i + 2 34 END 35 36 ------------------------------------------- 37 SELECT COUNT(*) FROM [dbo].[transtable] 38 SELECT COUNT(*) FROM [dbo].[transtable2] 39 40 SELECT TOP 10 * FROM [dbo].[transtable] ORDER BY [tranid] 41 SELECT TOP 10 * FROM [dbo].[transtable2] ORDER BY [tranid] 42 43 -------------------------------------------- 44 --创建两个存储过程 45 CREATE PROC INSERTTranstable 46 AS 47 DECLARE @i INT 48 SET @i = 1 49 WHILE @i <= 1000 50 BEGIN 51 IF ( @i % 2 = 0 ) 52 BEGIN 53 INSERT INTO [dbo].[transtable] 54 SELECT @i , 55 GETDATE() 56 SET @i = @i + 1 57 END 58 ELSE 59 BEGIN 60 SET @i = @i + 1 61 CONTINUE 62 END 63 END 64 ------------------------------------------ 65 CREATE PROC INSERTTranstable2 66 AS 67 DECLARE @i INT 68 SET @i = 1 69 WHILE @i <= 1000 70 BEGIN 71 IF ( @i % 2 = 0 ) 72 BEGIN 73 INSERT INTO [dbo].[transtable2] 74 SELECT @i , 75 GETDATE() 76 SET @i = @i + 1 77 END 78 ELSE 79 BEGIN 80 SET @i = @i + 1 81 CONTINUE 82 END 83 END 84 ----------------------------- 85 86 测试插入偶数行的性能 87 DECLARE @a DATETIME 88 DECLARE @b DATETIME 89 SELECT @a=GETDATE() 90 EXEC INSERTTranstable 91 SELECT @b=GETDATE() 92 SELECT @b-@a 93 -------------------------------------- 94 95 DECLARE @c DATETIME 96 DECLARE @d DATETIME 97 SELECT @c=GETDATE() 98 EXEC INSERTTranstable2 99 SELECT @d=GETDATE() 100 SELECT @d-@c
如有不对的地方,欢迎大家拍砖o(∩_∩)o
» 下一篇: 在SSMS里查看TDS数据包内容



