【Redis】布隆过滤器
目录
- 1. 是什么
- 2. 原理
- 缺点
-
- 误差判断
- 删除困难
- Bloom Filter 实现
-
- bit数组大小的选择
- 哈希个数K的选择
- 验证布隆过滤器
- 源码实战
- 应用场景
1. 是什么
===》布隆过滤器
- 优点是空间效率和查询时间都远远超过一般的算法
- 缺点是有一定的误识别率和删除困难。
2. 原理
挺喜欢周阳老师说过一句话,不懂底层原理的程序员不配称为程序员
布隆过滤器说简单也简单,其实就是对一个数字(id = 1)进行K次Hash映射,将映射的K次位置变为1
现在我们再去查询id = 1这个数据,经过K次Hash,布隆过滤器判定我们的数据在数据库中存在,将我们放行
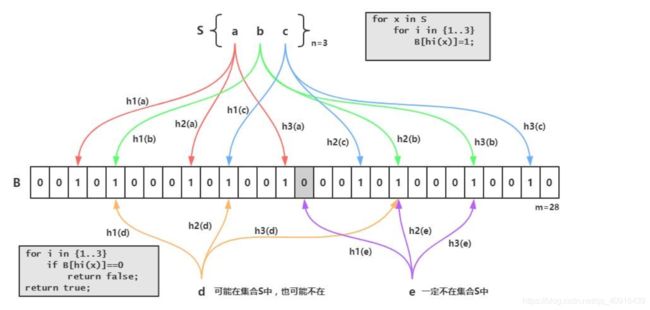
缺点
误差判断
我们上图可以看出,由于一些Hash算法的特殊性,可能会导致我们判断d在我们的数据库中,进行查询
删除困难
一个放入容器的元素映射到bit数组的k个位置上是1,删除的时候不能简单的直接置为0,可能会影响其他元素的判断。删除使用=Counting Bloom Filter
Bloom Filter 实现
布隆过滤器有许多实现与优化,Guava中就提供了一种Bloom Filter的实现。
在使用bloom filter时,绕不过的两点是预估数据量n以及期望的误判率fpp,
在实现bloom filter时,绕不过的两点就是hash函数的选取以及bit数组的大小。
对于一个确定的场景,我们预估要存的数据量为n,期望的误判率为fpp,然后需要计算我们需要的Bit数组的大小m,以及hash函数的个数k,并选择hash函数
bit数组大小的选择
根据预估数据量n以及误判率fpp,m = - nlnfpp/(ln2)^2
哈希个数K的选择
Hash函数的个数:k = m/n ln2
验证布隆过滤器
测试分两步:
-
往过滤器中放一百万个数,然后去验证这一百万个数是否能通过过滤器
-
另外找一万个数,去检验漏网之鱼的数量
/**
* 测试布隆过滤器(可用于redis缓存穿透)
*/
public class TestBloomFilter {
private static int total = 1000000;
private static BloomFilter<Integer> bf = BloomFilter.create(Funnels.integerFunnel(), total);
// private static BloomFilter bf = BloomFilter.create(Funnels.integerFunnel(), total, 0.001);
public static void main(String[] args) {
// 初始化1000000条数据到过滤器中
for (int i = 0; i < total; i++) {
bf.put(i);
}
// 匹配已在过滤器中的值,是否有匹配不上的
for (int i = 0; i < total; i++) {
if (!bf.mightContain(i)) {
System.out.println("有坏人逃脱了~~~");
}
}
// 匹配不在过滤器中的10000个值,有多少匹配出来
int count = 0;
for (int i = total; i < total + 10000; i++) {
if (bf.mightContain(i)) {
count++;
}
}
System.out.println("误伤的数量:" + count);
}
}
运行结果:
![]()
运行结果表示,遍历这一百万个在过滤器中的数时,都被识别出来了。一万个不在过滤器中的数,误伤了320个,错误率是0.03左右。
源码实战
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, int expectedInsertions) {
return create(funnel, (long) expectedInsertions);
}
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions) {
return create(funnel, expectedInsertions, 0.03); // FYI, for 3%, we always get 5 hash functions
}
public static <T> BloomFilter<T> create(
Funnel<? super T> funnel, long expectedInsertions, double fpp) {
return create(funnel, expectedInsertions, fpp, BloomFilterStrategies.MURMUR128_MITZ_64);
}
static <T> BloomFilter<T> create(
Funnel<? super T> funnel, long expectedInsertions, double fpp, Strategy strategy) {
......
}
BloomFilter一共四个create方法,不过最终都是走向第四个。看一下每个参数的含义:
funnel:数据类型(一般是调用Funnels工具类中的)
expectedInsertions:期望插入的值的个数
fpp 错误率(默认值为0.03)
strategy 哈希算法(我也不懂啥意思)Bloom Filter的应用
在最后一个create方法中,设置一个断点:

![]()
上面的numBits,表示存一百万个int类型数字,需要的位数为7298440,700多万位。理论上存一百万个数,一个int是4字节32位,需要481000000=3200万位。如果使用HashMap去存,按HashMap50%的存储效率,需要6400万位。可以看出BloomFilter的存储空间很小,只有HashMap的1/10左右
上面的numHashFunctions,表示需要5个函数去存这些数字
使用第三个create方法,我们设置下错误率:
private static BloomFilter<Integer> bf = BloomFilter.create(Funnels.integerFunnel(), total, 0.0003);
![]()
此时误伤的数量为4,错误率为0.04%左右。
![]()
当错误率设为0.0003时,所需要的位数为16883499,1600万位,需要12个函数
和上面对比可以看出,错误率越大,所需空间和时间越小,错误率越小,所需空间和时间越大
应用场景
- 进行数据收集监控数据时,查看是否被记录
- 爬虫:已经爬过的网站不需要再爬了
- 垃圾邮件过滤