【学习总结】VM12+CentOS6.8+hadoop2.7+jdk1.8搭建hadoop完全分布式集群超详细步骤【上篇】
当前环境:在vm12中,一个刚安装上的centOS,在虚拟机上只装vmtools,并创建了一个mr的普通用户。
方法概括:克隆出三台机器,然后修改对应的ip地址等,安装jdk和hadoop(上篇),进行ssh免密设置,再进行集群的核心配置,群起集群,运行(下篇)。
目标集群规划:
|
|
hadoop101 |
hadoop102 |
hadoop103 |
| HDFS
|
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
注: Jdk1.8+Linux编译过的hadoop-2.7.2.tar.gz百度盘下载链接在文末。
1 虚拟机准备
1.1:克隆centos64-0000,克隆三台
点击虚拟机右键,管理à克隆-->虚拟机当前状态à创建完整克隆-->输入虚拟机名称,并保存-->完成。
关闭防火墙
首先,查看防火墙当前状态,service iptables status,如防火墙运行的话,需关闭。
##关闭命令:
chkconfig iptables off1.2修改克隆虚拟机的静态IP(root权限)
以centOS-001为例:
修改配置文件:
vim /etc/udev/rules.d/70-persistent-net.rules:
三件事:删除原来eth0那一行,拷贝生成的mac地址,修改eth1为eth0,保存写入。
修改静态ip:
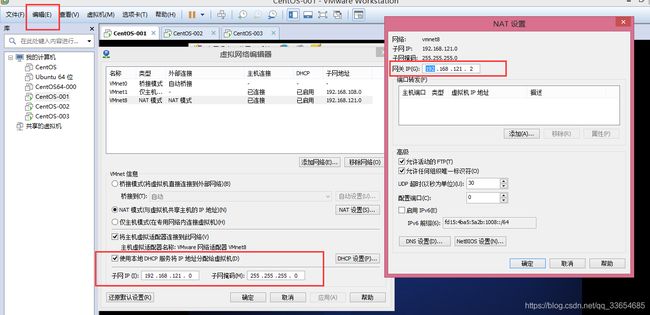
静态Ip设置标准:与网关在一个网段,且不可用网关的ip。查看网关网段:编辑-->虚拟网络编辑器,查看当前网络号。我的网段是192.168.121.0,网关是192.168.121.2。
vim /etc/sysconfig/network-scripts/ifcfg-eth0
修改主机名称:
vim /etc/sysconfig/network
修改完毕后,重启reboot。
按此方式修改其他两台静态IP
最终为三台主机名:
hadoop101----192.168.121.101,
hadoop102----192.168.121.102,
hadoop103----192.168.121.103,
测试三台虚拟机是否网络相通
为了方便,能用代号测试是否连通,可以在每台虚拟机下的/etc/hosts下配置,
vim /etc/hosts
测试三台虚拟机网络畅通网络
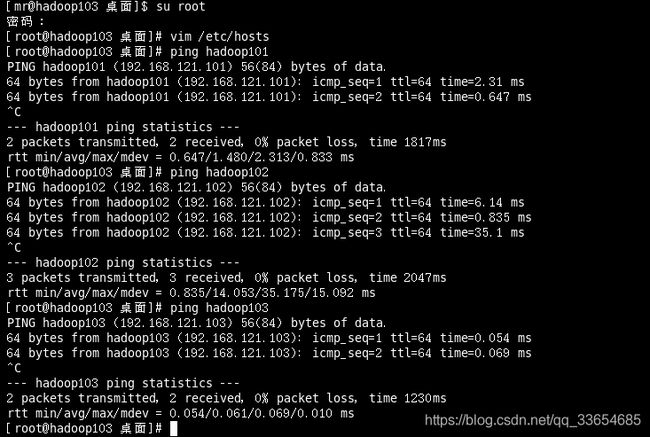
结果都能ping通。
1.3配置mr普通用户具有root权限
在修改IP地址的时候,必须root权限,但是root用户权限太高,使用root用户不安全,可以给普通用户配置root权限。
vim /etc/sudoers
三台虚拟机都为mr用户配置root权限。
2.java环境配置及hadoop安装
2.1创建目录
在/opt目录下创建module、software文件夹,software存放压缩包,module存放解压后的文件
[mr@hadoop101 桌面]$ sudo mkdir /opt/ module
[mr@hadoop101 桌面]$ sudo mkdir /opt/software修改module、software文件夹的所有者
[mr@hadoop101 opt]$ sudo chown mr:mr module/ software/
[mr@hadoop101 opt]$ ll
总用量 12
drwxr-xr-x. 2 mr mr 4096 3月 29 05:53 module
drwxr-xr-x. 3 root root 4096 3月 26 07:39 rh
drwxr-xr-x. 2 mr mr 4096 3月 29 05:54 software2.2安装jdk
将提前下载好的jdk1.8压缩包(下载链接在文末)放到/opt/software目录下,解压到/opt/module目录下,
[mr@hadoop101 opt]$ tar -zcvf software/jdk-8u144-linux-x64.tar.gz -C module/进入解压后的文件夹,获取JDK路径:
[mr@hadoop101 jdk1.8.0_144]$ pwd
/opt/module/jdk1.8.0_144打开/etc/profile文件:
[mr@hadoop101 module]$ sudo vi /etc/profile在profile文件末尾添加JDK路径:
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin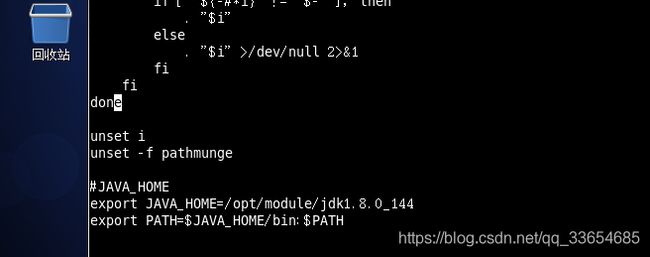
让修改后的文件生效
[mr@hadoop101 module]$ source /etc/profile
这样就把java环境配置好了。
2.4安装hadopp2.7.2
将提前linux编译过的hadoop jar包hadoop-2.7.2.tar.gz(下载链接见文末)放到/opt/software目录下,解压到/opt/module目录下,

解压后查看:
[mr@hadoop101 software]$ tar -zxvf hadoop-2.7.2.tar.gz -C ../module/
获取Hadoop安装路径pwd

编辑/etc/profile文件
[mr@hadoop101 hadoop-2.7.2]$ sudo vim /etc/profile在profile文件末尾添加JDK路径:(shitf+g跳到文末,shift+$跳到行末)
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
让修改后的文件生效:
[mr@hadoop101 hadoop-2.7.2]$ source /etc/profile测试是否安装成功:
[mr@hadoop101 hadoop-2.7.2]$ hadoop version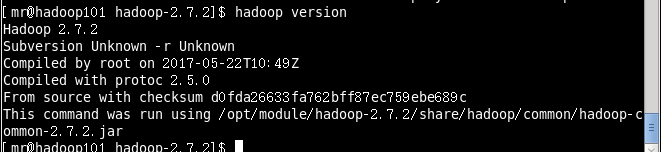
显示成功。
3. 安全拷贝scp与远程同步工具xsync
在步骤2中,我们只是对hadoop101上进行环境配置,总的来说,我们创建了两个文件夹,修改了/etc/profile文件。这些操作单一有限,可以编写集群分发脚本,把这些增加或修改分发到集群中的相应位置。这就可以用到安全拷贝scp与远程同步工具xsync了。
3.1scp
在这里我们要将hadoop101中/opt/module目录下的软件拷贝到hadoop102以及hadoop103上,在hadoop102和hadoop103上的/opt目录只有root才有写的权限,
[mr@hadoop101 /]$ scp -r /opt/module root@hadoop102:/opt/module
[mr@hadoop101 /]$ scp -r /opt/module root@hadoop103:/opt/module
在hadoop102、hadoop103上修改所有文件的,所有者和所有者组。
[mr@hadoop102 opt]$ sudo chown mr:mr -R /opt/module
[mr@hadoop103 opt]$ sudo chown mr:mr -R /opt/module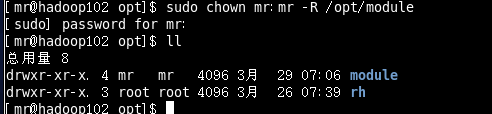
3.2 rsync 远程同步工具
在这里,我们可以将hadoop101中/etc/profile文件同步到hadoop102,hadoop103的/etc/profile上。
编写脚本
在/usr/local/bin目录下(可全局使用xsync命令)创建xsync文件,文件内容如下:
[mr@hadoop102 bin]$ sudo vim xsync在该文件中编写如下代码
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=101; host<104; host++)); do
echo ------------------- hadoop$host --------------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done修改脚本 xsync 具有执行权限: [mr@hadoop101 bin]$ sudo chmod 777 xsync
切换到root用户,把xsync脚本同步到其他两台虚拟机上的/user/local/bin下(root用户才具有在这个目录的写权限)。
[root@hadoop101 bin]# xsync /usr/local/bin
使用xsync脚本将hadoop101中/etc/profile文件同步到hadoop103、hadoop103的/etc/profile上
[root@hadoop101 bin]# xsync /etc/profile3.3执行/etc/source 文件,并检验是否安装成功
[root@hadoop103 module]# source /etc/profile
[root@hadoop103 module]# java –version
[root@hadoop103 module]# hadoop version
3.4scp和xsync的差别
scp可以实现服务器与服务器之间的数据拷贝。rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
4总结
上篇只是进行了虚拟机环境配置,在每一台虚拟机上安装好hadoop,创建好集群分发脚本sxync。具体的集群搭建,集群运行将在下篇介绍。
并且经过上述安装步骤后,服务器与服务器之间进行传输的时候,还是会输入密码,比较麻烦,下篇将设置ssh免密登录其他服务器。
hadoop2.7.2+jdk1.8下载地址
链接:https://pan.baidu.com/s/1TGMReL_VBwvxmZuAcd4T4Q
提取码:vee6