【学习总结】VM12+CentOS6.8+hadoop2.7+jdk1.8搭建hadoop完全分布式集群超详细步骤【下篇】
上篇详细介绍了虚拟机环境配置, 在每一台虚拟机上安装好hadoop,创建好集群分发脚本sxync。下篇将进行ssh无密登录配置,以及集群的真正搭建。
目标集群规划:
|
|
hadoop101 |
hadoop102 |
hadoop103 |
| HDFS
|
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
1 SSH无密登录配置
1.1生成公钥与私钥
Hadoop101以普通用户mr进入mr的家目录里下的.ssh目录下,生成公钥和私钥,直接三次回车:
[mr@hadoop101 .ssh]$ ssh-keygen -t rsa
查看hadoop101生成的公钥,

将hadoop101自己的公钥拷贝到hadoop101将要免密登录的目标机器上
[mr@hadoop101 .ssh]$ ssh-copy-id hadoop101
[mr@hadoop101 .ssh]$ ssh-copy-id hadoop102
[mr@hadoop101 .ssh]$ ssh-copy-id hadoop103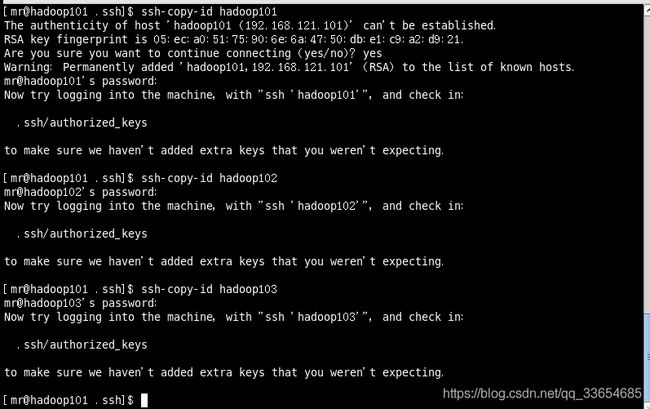
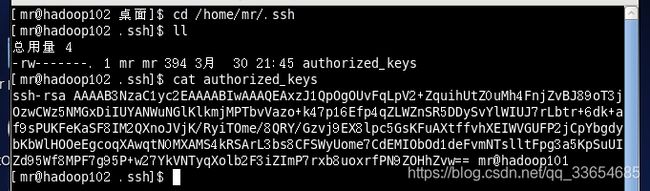
可以在hadoop102的mr家目录下的.ssh/目录下查看,验证是否收到hadoop101的公钥,
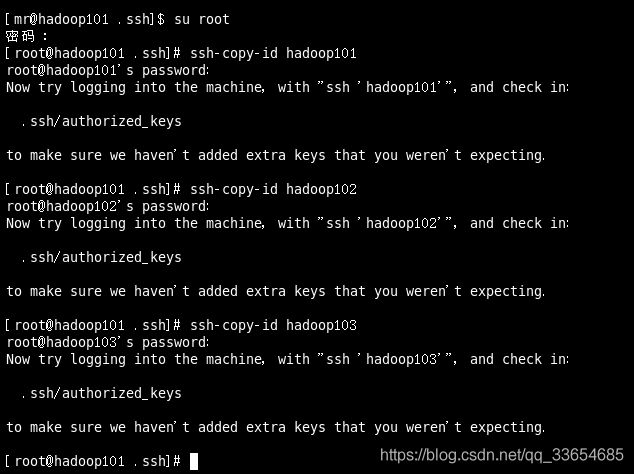
还需要在hadoop101上采用root账号,配置一下无密登录到hadoop102、hadoop103、hadoop104;因为在hadoop101上有namenode节点,将会hadoop101,hadoop102,hadoop103通讯。
在hadoop102上采用mr账号配置一下无密登录到hadoop101、hadoop102、hadoop103服务器上。因为在hadoop102上有resourceManager,也会将于hadoop101,hadoop102,hadoop103通讯。
要进入hadoop102家目录下的.ssh/目录下,上生成hadoop102的公钥与私钥。 将hadoop102的公钥分发到hadoop101、hadoop102、hadoop103服务器上。
[mr@hadoop102 .ssh]$ ssh-copy-id hadoop101
[mr@hadoop103 .ssh]$ ssh-copy-id hadoop102
[mr@hadoop102 .ssh]$ ssh-copy-id hadoop1032.集群配置
2.1在hadoop101上配置slavers
[mr@hadoop101 .ssh]# cd /opt/module/hadoop-2.7.2/etc/hadoop/
[mr@hadoop101 hadoop]# sudo vim slaves在该文件中增加如下内容,配置DataNode节点:
hadoop101
hadoop102
hadoop103
使用xsync在hadoop102,hadoop103即所有节点上同步配置文件,(xsync脚本创建及编写见上篇)
[mr@hadoop101 hadoop]$ xsync slaves
配置了ssh免密登录就不用再输入密码了。
2.2 配置集群
核心配置文件
配置core-site.xml
[mr@hadoop101 hadoop]$ vim core-site.xml![]() 在该文件中编写如下配置
在该文件中编写如下配置
fs.defaultFS
hdfs://hadoop101:9000
hadoop.tmp.dir
/opt/module/hadoop-2.7.2/data/tmp
 HDFS配置文件
HDFS配置文件
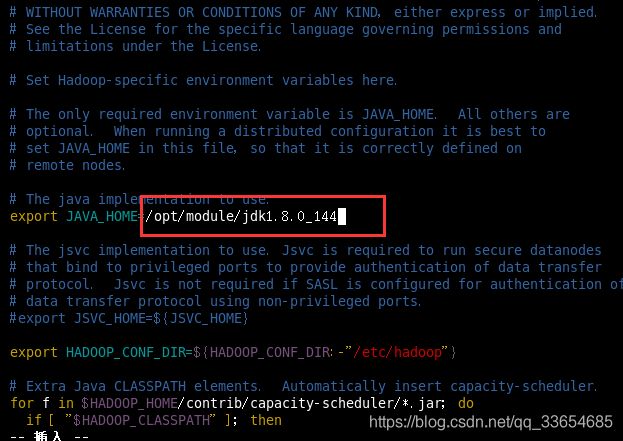
配置hadoop-env.sh,查看我的jdk安装在什么位置后,将地址拷贝
[mr@hadoop101 hadoop]$ vim hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置hdfs-site.xml
[mr@hadoop101 hadoop]$ vim hdfs-site.xml在该文件中编写如下配置
dfs.namenode.secondary.http-address
hadoop104:50090

YARN配置文件
配置yarn-env.sh,我的jdk安装在/opt/module/jdk1.8.0_144,
[mr@hadoop101 hadoop]$ vim yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置yarn-site.xml
[mr@hadoop101 hadoop]$ vim yarn-site.xml在该文件中增加如下配置
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop102

MapReduce配置文件
配置mapred-env.sh
[mr@hadoop101 hadoop]$ vim mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置mapred-site.xml,先拷贝mapred-site.xml.template,并生成mapred-site.xml文件
[mr@hadoop101 hadoop]$ cp mapred-site.xml.template mapred-site.xml
[mr@hadoop101 hadoop]$ vim mapred-site.xml在该文件中增加如下配置
mapreduce.framework.name
yarn

2.3在集群上分发配置好的Hadoop配置文件
[mr@hadoop101 hadoop]$ xsync /opt/module/hadoop-2.7.2/2.4查看文件分发情况
[mr@hadoop101 ~]$ cat /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml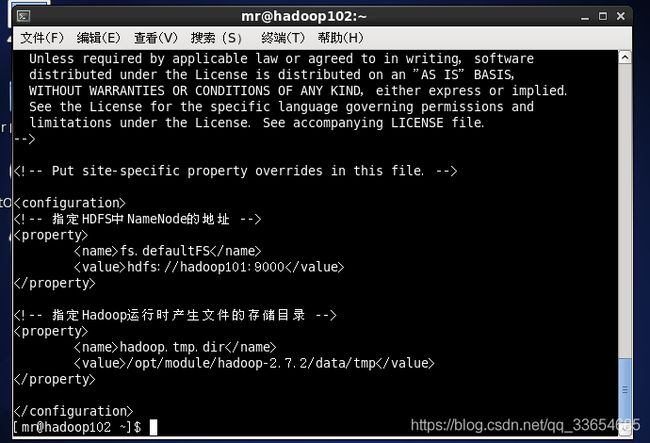 3.群起集群
3.群起集群
3.1格式化NameNode
如果集群是第一次启动,需要格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)



在hadoop101中进入hadoop安装目录,开始格式化:
[mr@hadoop101 hadoop-2.7.2]$ bin/hdfs namenode -format
格式化成功

3.2在hadoop101上启动HDFS
[mr@hadoop101 hadoop-2.7.2]$ sbin/start-dfs.sh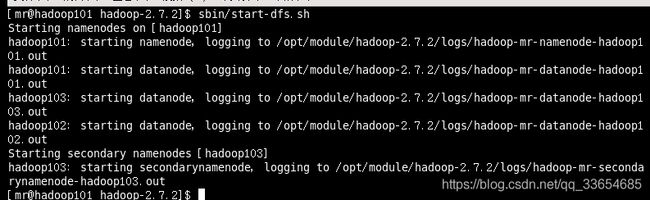
3.3在hadoop102上启动YARN
[mr@hadoop102 hadoop-2.7.2]$ sbin/start-yarn.sh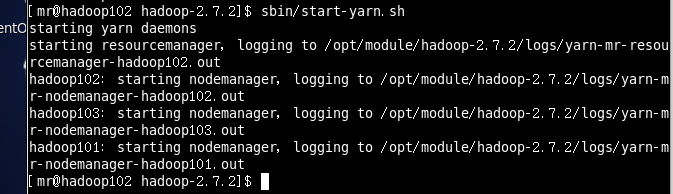
注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN。
3.4查看三个集群是否都正常启动
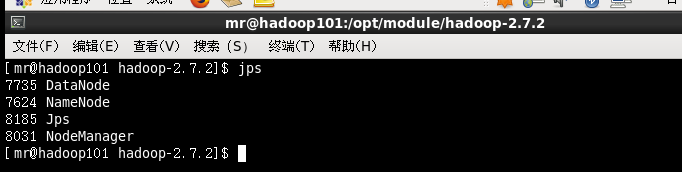

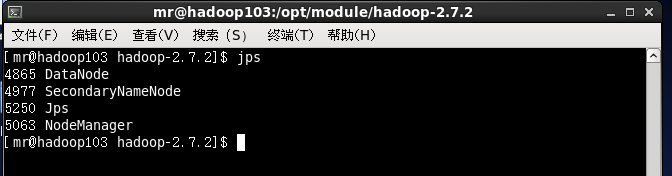
最终集群搭建成功
4 集群启动/停止方式总结
4.1各个服务组件逐一启动/停止
(1)分别启动/停止HDFS组件
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode
(2)启动/停止YARN
yarn-daemon.sh start / stop resourcemanager / nodemanager
4.2各个模块分开启动/停止(配置ssh是前提)常用
(1)整体启动/停止HDFS
start-dfs.sh / stop-dfs.sh
(2)整体启动/停止YARN
start-yarn.sh / stop-yarn.sh