AVA后端知识点碎片化整理 基础篇(十七) 小常识
(—)select poll epoll的区别(NIO的原理)
select poll epoll都是IO多路复用的机制,IO多路复用就是通过一种机制监视多个描述符,一旦某个描述符就绪,能够通知程序进行相应的读写操作,但select、poll、epoll本质上是同步IO,因为他们都需要在读写事件就绪后自己负责进行读写,就是说这个读写过程是阻塞的。
nio原理就是使用单线程或者只是使用少量的线程,每个连接共用一个线程,当处于等待的时候现成资源可以释放出来处理别的请求,通过实践驱动模型当有acctep./read/write时实践发生通知主贤臣过处理相关资源,selector就是这个模型中的观察者。
(1)select
调用过程,首先将fd_set从用户空间拷贝到内核空间,然后注册回调函数,遍历所有的fd,调用其对应的poll方法(对于socket,这个poll方法是),将当前进程挂到设备的等待队列中,不同设备有不同的等待队列,当设备收到一个消息或者填写完成文件数据后,会唤醒等待队列上的睡眠进程,这poll方法就会返回一个描述操作是否读写的mask掩码,会唤醒设备等待队列上睡眠进程,这时current就被唤醒了。根据这个mask掩码给fd_set赋值。如果遍历完了fd还没有可以读写的mask掩码,就会让select,等待一段时间如果还是没人唤醒那么select的进程就会被重新唤醒获得cpu,进而重新遍历fd,判断就绪。最后将fd_set内核空间拷贝到用户空间中。
select的几大缺点:(1)每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd会很大,
(2)同时每次调用select都需要吧内核传进来的所有fd都进行遍历,这开销在id很多时候会很大。
(3)select支持的文件描述符数量太少是1024
从用户到内核空间的拷贝,既然长期监视这几个fd,甚至连期待的时间都不会改变,那么拷贝将是重复而无任何意义的,我们可以让内核长期保持所有需要监视的fd甚至是期待事件,或者可以在需要时进行部分事件的修改,将当前线程轮流加入到每个fd对应设备的等待队列中,这样无非是哪一个设备就绪时能够通知进程退出调用。
(2)poll实现
poll的实现和select非常相似,只是描述fd方式不同,poll的接口保护监视的event和发生的event,poll没有最大数量限制,与select函数一样,poll返回后,需要轮询的方式来获取描述符。
(3)epoll
epoll是对select和poll的改进,就应该能避免上述三个缺点,epoll都是怎么解决的?
第一点:epoll的解决方案是在每次注册新事件到句柄中时,所有的fd拷贝到内核,而不是epoll_wait的时候重复拷贝,保证了每个fd在整个过程中只会拷贝一次。
第二点:epoll不像select和poll那样每次吧current轮流加入到fd对应的设备等待队列中,它为每个fd提供一个回调函数,当设备就绪时候,唤醒等待队列上的等待者,就会调用这个回调函数,而这个回调函数会把就绪的fd加入到一个就绪链表中,实际工作时候就是去查看这个链表上有没有就绪fd,判断情况与select一致。
第三点:epoll没有这个限制,它支持的fd上限是最大可以打开文件的数目,这个数目2048,epoll的这个限制由内存所决定。
总结:(1)select,poll实现需要自己不断轮询所有fd集合,直到设备就绪,期间可能需要睡眠唤醒的多次交替,而epoll其实也需要嗲用epoll_wait不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,吧就绪fd放入就绪链表中,并唤醒epoll_wait进入睡眠进程,虽然都要睡眠和交替,但是select和poll是“醒着”的时候需要遍历整个fd集合,epoll醒着的时候只要判断一下就绪链表是否为空就行了,节省了大量CPU时间。(2)select poll每次调用都需要将fd集合从用户态拷贝到内核态,要把current往等待设备队列中挂一次,而epoll只需要拷贝一次(epoll这里并不是设备等待队列,而是epoll内部自定义的队列)(实际上最要的就是epoll只拷贝了就绪设备,而select和poll都拷贝再判断)
(2)虚唤醒?如何解决(网络上例子,被问到了不会XXX)
public class MyStack {
private List
public synchronized void push(String value) {
synchronized (this) {
list.add(value);
notify();
}
}
public synchronized String pop() throws InterruptedException {
synchronized (this) {
if (list.size() <= 0) {
wait();
}
return list.remove(list.size() - 1);
}
}
}
问题:这段代码正常情况允许正常,但是某些情况下回出现问题,什么时候回出现问题?如何修正?
代码分析:从整体上,并发状态下,push和pop都使用synchronized的锁,来实现同步,同步的数据对象是基于list的锁的数据,大部分情况下是可以正常工作的。
状况1:
1. 假设有三个线程: A,B,C. A 负责放入数据到list,就是调用push操作, B,C分别执行Pop操作,移除数据。
2. 首先B先执行,于pop中的wait()方法处,进入waiting状态,进入等待队列,释放锁。
3. A首先执行放入数据push操作到List,在调用notify()之前; 同时C执行pop(),由于synchronized,被阻塞,进入Blocked状态,放入基于锁的等待队列。注意,这里的队列和2中的waiting等待队列是两个不同的队列。
4. A线程调用notify(),唤醒等待中的线程A。
5. 如果此时, C获取到基于对象的锁,则优先执行,执行pop方法,获取数据,从list移除一个元素。
6. 然后,A获取到竞争锁,A中调用list.remove(list.size() - 1),则会报数据越界exception。
状况2:
1. 相同于状况1
2. B、C都处于等待waiting状态,释放锁。等待notify()、notifyAll()操作的唤醒。
3. 存在被虚假唤醒的可能。
解决的办法是基于while来反复判断进入正常操作的临界条件是否满足:
synchronized (obj) {
while (
obj.wait();
... // Perform action appropriate to condition
}
如何修复问题?
#1. 使用可同步的数据结构来存放数据,比如LinkedBlockingQueue之类。由这些同步的数据结构来完成繁琐的同步操作。
#2. 双层的synchronized使用没有意义,保留外层即可。
#3. 将if替换为while,解决虚假唤醒的问题。
(3)委派双亲模式(类加载模式)
java虚拟机中有三个类加载器,默认三个主要的类加载器,每个类负责加载特定位置的类。(.java 变成 .class)
BootStrap:类加载器也是java类,因为java类的类加载器本身也是要被类加载器加载的,显然必须有一个类加载器不是Java类,这个正是bootStrap,使用C/c++写的,封装到JVM内核中,
ExtClassLoader、AppclassLoader是java类。 (他们三个不是继承关系,而是组合关系)
每个类加载器加载类是时,有会委托给其他上级类加载器,当所有祖类在加载器都没有加载到类的时候,回到发起者类加载器还记载不了,机会发出ClassNotFountException,不是再去找到发起者加载器的儿子,因为没有getChild()。实际上就是MyClassLoader-》AppClassLoader-》ExtClassLoader-》BootStrap,自定义的MyClassLoader首先会委托给AppClassLoaer,AppClassLoader会委托给ExtClassLoader,ExtClassLoader会委托给BootStrap,这个时候BootStrap会去加载,如果加载成功,就结束了。如果加载失败,就会交给ExtClassLoader去加载,如果ExtClassLoader加载成功,就结束了,如果加载失败就交给AppClassLoader加载,如果成功就结束,如果还失败就交给MyClassLoader1类加载器,最后还加载失败就会ClassNotFound异常。
优点是Java的类加载器一起具备了这种带优先级的层次关系,越是基础的类,越是被上层的类加载器进行加载,保证java程序的稳定运行。启动类加载器会抢在标准扩展加载器之前去装载类,而标准扩展类加载器可以抢在类路径加载器之前去装载那个类,类路径装载器之前去加载类。所以java虚拟机从最可信的java核心API中去查找类型,这是为了防止不可信的类扮演被信任的类。
(4)如何查看一个端口是否被占用
netstat -anp |grep 端口号 如果是普通用户需要sudu一下,
例如linux下查看3306,会发现listen状态,这表明他被mysql占用了。
![]()
(5)Mysql中行锁的实现(真的很气)
背景:事务(Transaction)即ACID属性
事务是由一组SQL组成的逻辑处理单元,事务具有以下四个属性,通常简称为事务的ACID属性。
原子性(Atomicity)事务是一个原子操作单元,其对数据的修改,要么全执行要么全不执行。
一致性(Consitent)事务开始和完成时,数据都必须保持一致状态,这意味着所有相关的数据规则都必须应用事务的修改,以保持数据的完整性;事务结束时,所有的内部数据结构也必须一致。
隔离性(Isolation):数据库系统提供一定的隔离机制,保证事务不受外部并发操作影响的独立环境,这以为这事务处理过程中的中间状态对外部都是不可见的。
持久性(Rurable)事务完成后,他对数据修改是永久性的,即使出现系统故障也能保持。
所以为了防止事务出现并发处理问题,数据更新丢失,并不能单靠数据库事务控制器来解决,需要应用程序对更新的数据加必要的锁来解决,因此,防止更新数据丢失时应用的责任,而“脏读” “不可重复读” “幻读”其实都是 数据库读一致性问题,必须由数据提供一定的事务隔离机制来解决。
- 表级锁:每次操作锁住整张表。开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低;
- 行级锁:每次操作锁住一行数据。开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高;
- 页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。没弄懂,有空再看。?
MyISAM的锁
稍微提一下MyISAM,只说和InnoDB不同的。
a. MyISAM只有表锁,锁又分为读锁和写锁。
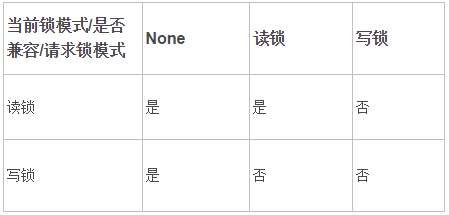
b. 没有事务,不用考虑并发问题,世界和平~
c. 由于锁的粒度太大,所以当该表写并发量较高时,要等待的查询就会很多了。优化见 。
2 InnoDB的行锁和表锁
没有特定的语法。mysql的行锁是通过索引体现的。
如果where条件中只用到索引项,则加的是行锁;否则加的是表锁。比如说主键索引,唯一索引和聚簇索引等。如果sql的where是全表扫描的,想加行锁也爱莫能助。
行锁和表锁对我们编程有什么影响,要在where中尽量只用索引项,否则就会触发表锁。另一个可能是,我们发疯了地想优化查询,但where子句中就是有非索引项,于是我们自己写连接?
InnoDB行锁是通过给索引添加索引项来实现,这一点MYSQL与Oracle不同,后者是通过数据块中相应的数据行加锁来实现的。InnoDB这种行锁实现特点意味着:只有通过索引条件检索数据,Innodb才使用行级锁。否则InnoDB将使用表锁。
在实际应用中,要特别注意InnoDB行锁这一特性,不然会导致大量的锁冲突引发开发性能。
在不通过索引条件的时候,InnoDB确实使用的是表锁,而不是行锁。(InnoDB这种行锁实现特点意味着只能通过条件检索数据,InnoDB才能使用行级锁,佛则,InnoDB将使用表锁)
1、在不通过索引条件查询的时候使用表索引。create table tab_no_index(id int,name varchar(20));
select from tab_no_index where id = 1;用的是表索引
有索引以后,在索引字段查询时,使用的就是行级锁。
alter table tab_no_index add index ind_tab_no_index_id(id);
2、由于Mysql的行锁是针对索引加的锁,不是针对记录加的锁,所以虽然我们访问不同行的记录,但是如果是使用相同的索引键,是会出现锁冲突的。
3、当表有多个索引的时候,不同的事务可以使用不同的索引锁定不同的行,另外,无论是使用主键索引,唯一索引或者是普通索引,InnoDB都会使用行锁来对数据加锁。
InnoDB实现了两种类型的行锁,
共享锁:允许一个事务去读一行,阻止其他事务获取相同数据集的排它锁。
排它锁:允许获得排他锁的事务更新数据,阻止其他事务获取相同数据集的共享读锁
间隙锁:当我们用范围条件而不是相等条件去检索数据,并请求共享或排她锁时,InnoDB会给符合条件的已有数据记录的索引项加锁,对于键值在条件范围内但并不存在的记录叫做“间隙”,InnoDB也会对这个间隙加锁,这种锁机制就是所谓的间隙锁。
举例如果表中123条数据,根据这个id是1-123,用select * from table where id》100 ,这个不仅会对100-123进行加锁,包括一些1000 10001等这些不存在的值也会被加锁。 间隙锁的目的就是为了防止幻读,满足相关隔离级别的要求, 但是这种范围条件键值的并发插入,会导致锁等待,因此 我们要尽量优化业务逻辑,尽量使用相等的条件访问更新数据,避免使用范围条件。
什么时候使用表锁:对于InnoDB,在绝大多数情况下都应该使用行锁,因为事务和行锁是我们使用InnoDB的理由,在个别特殊事务中,也可以考虑使用表级锁。
1、第一种情况是,事务需要更新大部分或者全部数据,表又比较大,如果使用默认的行锁,不仅这个事务执行效率低,而且可能造成其他事务长时间锁等待和锁冲突,这种情况下可以考虑使用表锁来提高事务的执行速度。
2、事务设计多个表比较复杂,很可能会引起死锁,造成大量事务回滚,这种情况也可以考虑一次性锁定事务涉及的表,从而避免死锁,减少数据库回滚的开销。
有一个小例子 用for update为select语句加写锁,默认情况下,select语句不会加写锁也就是阻止写入update
行锁 如果主键查询的话,那么加行锁
第一个链接begin;select * from test where id = 1for update;
第二个连接update test set name =‘abc’ where id = 1;这时候第二个连接连接不上
第三个连接 update test set name ‘lzh’ where id = 2;执行成功
这时候第一个链接commit之后,第二个连接也会执行成功。
相同的三个操作,在表锁的情况下第三个操作不会执行成功的,因为他锁定了一个表。
悲观锁和乐观锁的概念:
悲观锁(Pessimistic Concurrency Control,PCC):假定会发生并发冲突,屏蔽一切可能违反数据完整性的操作。至于怎么加锁,加锁的范围也没讲。
乐观锁(Optimistic Concurrency Control,OCC):假设不会发生并发冲突,只在提交操作时检查是否违反数据完整性。也没具体指定怎么检查。
就是这么概念,什么都不说清楚。毕竟乐观锁和悲观锁也不仅仅能用在数据库中,也能用在线程中。
悲观的缺陷是不论是页锁还是行锁,加锁的时间可能会很长,这样可能会长时间的限制其他用户的访问,也就是说悲观锁的并发访问性不好。
乐观锁不能解决脏读,加锁的时间要比悲观锁短(只是在执行sql时加了基本的锁保证隔离性级别),乐观锁可以用较大的锁粒度获得较好的并发访问性能。但是如果第二个用户恰好在第一个用户提交更改之前读取了该对象,那么当他完成了自己的更改进行提交时,数据库就会发现该对象已经变化了,这样,第二个用户不得不重新读取该对象并作出更改。
可见,乐观锁更适合解决冲突概率极小的情况;而悲观锁则适合解决并发竞争激烈的情况,尽量用行锁,缩小加锁粒度,以提高并发处理能力,即便加行锁的时间比加表锁的要长。
(6)Fork和Join
Fork/Join是JAVA7 提供了一个用并行执行任务的框架,是吧一个任务分割成多个若干个小任务,最终汇总到每个小任务到大任务的框架。Fork Join'其实就是ExecutorService接口的一种具体实现,目的是为了帮助你更好的利用多处理器的好处。它为那些能够被递归拆解成子任务的工作类型量身设计的,提高应用性能。
我们都知道Fork Join就是分割大任务成小任务去执行,最后融合成大任务的结果。而Fork/Join把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里面的任务。那么这就会出现一个情况,有些线程任务队列里面已经完成有些队列任务没有完成。这样会造成线程闲置,所以为了提高效率,完成自己的任务而处于空闲的工作线程仍可以从忙碌状态的工作线程处窃取等待任务,为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取的线程智能从头部寻找任务执行,窃取任务的线程永远智能从尾部拿任务。
核心 ForkJoinPool两个子类:
RecursiveAction:用于没有返回结果的任务。
RecursiveTask :用于有返回结果的任务。
实现大数据计算QAQ
public class FockJoinTest exteds RecursiveTask{//继承RecursizeTask来实现
//设置一个最大计算容量
private final int DEFAULT_CAPACITY = 10000;
//用两个数字表示目前计算的范围
private int start;
private int end;
public FockJoinTest(int start,int end){
this.start = start;
this.end = end;
}
@Override
protected Long compute(){
//分两种情况进行
long sum = 0;
//如果任务在最大容量内
if(end - start < DEFAULT_CAPACITY){
for (int i = start; i < end; i++) {
sum += i;
}
}else{//如果超过了最大容量,那么就进行拆分处理
//计算容量中间值
int middle = (start + end)/2;
//进行递归
FockJoinTest fockJoinTest1 = new FockJoinTest(start, middle);
FockJoinTest fockJoinTest2 = new FockJoinTest(middle + 1, end);
//执行任务
fockJoinTest1.fork();
fockJoinTest2.fork();
//等待任务执行并返回结果
sum = fockJoinTest1.join() + fockJoinTest2.join();
}
return sum;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
FockJoinTest fockJoinTest = new FockJoinTest(1, 100000000);
long fockhoinStartTime = System.currentTimeMillis();
//前面我们说过,任务提交中invoke可以直接返回结果
long result = forkJoinPool.invoke(fockJoinTest);
System.out.println("fock/join计算结果耗时"+(System.currentTimeMillis() - fockhoinStartTime));
long sum = 0;
long normalStartTime = System.currentTimeMillis();
for (int i = 0; i < 100000000; i++) {
sum += i;
}
System.out.println("普通计算结果耗时"+(System.currentTimeMillis() - normalStartTime));
}
} (7)手撕Arraylist动态代理类
final List list = new ArrayList();
List proxyInstance = (List)Proxy.newProxyInstance(list.getClass().getClassLoader(),
list.getClasss().getInstance(),
new InvocationHandler(){
@Override
public Object invoke(Object proxy,Method method,Object[] args) throws Throwable{
return method.invoke(list,args);
}
});
proxyInstance.add("你好")
System.out.pringln(list); 静态代理类通常只代理一个类,动态代理类是代理一个接口下多个实现类。 静态代理类实现知道自己要去代理什么,而动态代理类不知道自己要代理什么东西,只有运行时候才知道。
动态代理是实现InvocationHandler接口的invoke方法,但注意的是代理是接口,也就是你的业务类必须要实现的接口,通过Proxy的newProxyInstance得到代理对象。 还有一种动态代理CGLIB,代理的是类,不需要业务类继承接口,通过派生出子类去实现,通过在运行时,动态修改字节码去实现改变的目的。