标准I/O库总结
前言
不积硅步无以至千里,不积小流无以成江河。工作中遇到的一些小问题,隐藏的BUG往往都是一些小知识点掌握的不全面导致的。还是很有必要把一些常用的知识点总结一下,可以供以后查阅,提供工作效率。
一、概念:
1、标准I/O库在很多操作系统上都实现了此库,它由ISO C标准说明。标准I/O库是带缓存的I/O,处理了很多细节,例如缓冲区分配,以优化长度执行I/O等。这些处理使用户不必担心如何选择使用正确的块长度。这使得它便于用户使用,但是如果深入的了解I/O库函数的操作,也会带来一些问题。
所有的文件I/O都是针对文件描述符的。当打开一个文件时,即返回一个文件描述符,然后该文件描述符就用于后续的I/O操作。而对于标准I/O库,它们的操作使围绕流(stream)进行的。当用标准I/O库打开或创建一个文件时,我们已使一个流与一个文件相关联。
当打开一个流时,标准I/O函数fopen返回一个FILE对象的指针(类型为FILE *,称为文件指针)。该对象通常是一个结构体,它包含了标准I/O库为管理该流所需要的所有信息,包括:用于实际I/O的文件描述符、指向用于该流缓冲区的指针、缓冲区长度、当前在缓冲区中的字符数以及出错标志等。
2、标准输入、标准输出和标准出错:
对一个进程预定义了三个流,并且这三个流可以自动的被进程使用,他们是:标准输入、标准输出和标准错误。这三个标准I/O流通过预定义的文件指针stdin,stdout和stderr加以引用。这三个文件指针定义在头文件
3、缓冲:(定义不同的缓冲区长度,执行I/O所需要的CPU时间量不同)
标准I/O库提供缓冲的目的是尽可能减少使用read和write调用的次数。标准I/O库也对每个I/O流自动的进行缓冲处理,从而避免了应用程序需要考虑这一点所带来的麻烦。
标准I/O库提供了三种类型的缓冲:
1)全缓冲:这种情况下,在填满标准I/O缓冲区后才进行实际I/O操作。对于驻留在磁盘上的文件(如常规文件)通常是由标准I/O库实施全缓冲的。
2)行缓冲,只有在写了一行之后,或者当输入输出中遇到换行符时标准I/O库才进行I/O操作。行缓冲通常用于终端设备,如标准输入和标准输出对应的终端设备。
注意:标准I/O库用来收集每一行的缓冲区的长度是固定的,所以只要填满了缓冲区,即使还没有写一个换行符,也进行I/O操作。
3)不带缓冲:
标准I/O库不对字符进行缓冲存储。例如,如果用标准I/O函数fputs写15个字符到不带缓冲的流中,则该函数可能会用write系统调用函数将这些字符立即写至相关联的打开文件上。
标准出错流stderr通常是不带缓冲的,这可以使出错的信息尽快的显示出来,而不管它是都含有一个换行符。
二、标准I/O函数解析:
1、打开和关闭流:
1.1 打开流fopen:
头文件:#include
函数原型:FILE *fopen(const char *restrict pathname, const char *restrict type);
freopen与fdopen暂不讨论。
返回值:若成功则返回文件指针,若出错则返回NULL。
函数作用:打开一个指定的文件。
参数:
pathname:文件路径
type:文件打开的方式,常用以下方式打开。取值如下:
r rb 只读方式打开;文件必须已存在。
w wb 只写方式打开;如果文件不存在则创建,如果文件已存在则把文件长度截断(Truncate)为0字节再重新写,也就是替换掉原来的文件内容。
a ab 只写打开追加文件末尾;只能在文件末尾追加数据,如果文件不存在则创建。
r+ rb+ 读写方式打开;允许读和写,文件必须已存在。
w+ wb+ 读写打开,长度置零;允许读和写,如果文件不存在则创建,如果文件已存在则把文件长度截断为0字节再重新 写。
a+ ab+ 读写打开,追加文件末尾;允许读和追加数据,如果文件不存在则创建。
1.2 关闭流fclose:
头文件:#include
函数原型:int fclose(FILE *fp);
返回值:若成功则返回0,若出错则返回EOF。
说明:在文件被关闭之前,冲洗缓冲区中的输出数据。丢弃缓冲区中的任何输入数据。如果标准I/O库已经为该流自动分配了一个缓冲区,则释放此缓冲区;当一个进程正常终止时(直接调用exit或从main函数返回),则所有(分配给该进程的)标准I/O流都会被冲洗,所有打开的I/O流都会被关闭。
1.3 错误码errno与打印错误信息函数perror、strerror:
Linux中系统调用的错误都存储于 errno中,errno由操作系统维护,存储就近发生的错误,即下一次的错误码会覆盖掉上一次的错误。各种错误对应一个错误码,errno在errno.h中声明,是一个整型变量,所有错误码都是正整数。
直接打印errno只会打印出一个整数值看不出什么错误,可以用perror或strerror函数将errno解释成字符串再打印。
头文件:#include
函数原型:void perror(const char *s);
函数作用:打印系统错误信息。
参数: s表示字符串提示符
返回值:无返回值
说明:perror函数将错误信息打印到标准错误输出,首先打印参数s所指的字符串然后打印":"号,然后根据当前errno的值打印错误原因。 输出形式:
const char *s: strerror(errno) ,提示符:发生系统错误的原因。
头文件:#include
函数原型:char *strerror(int errnum);
函数作用:根据错误号返回错误原因字符串。
参数errnum:错误码errno。
返回值:错误码errnum所对应的字符串。
说明:有些函数的错误码并不保存在errno中而是通过返回值返回,这时strerror就可以用到了,用法:fputs(strerror(n), stderr)。
2、读和写流:
2.1 一旦打开了流,则可在三种不同类型的非格式化I/O中进行选择,对其进行读、写操作:
1)每次一个字符I/O。使用这些函数可实现一次读或写一个字符,每次读入一个字符:getc、fgetc、getchar;每次输出一个字符putc、fputc、putchar。
2)每次一行的I/O。使用这些函数可实现每次读或写一行,读一行:fgets;写一行:fputs。每行都以一个换行符终止。当调用fgets时,应说明能处理的最大行长。
3)直接I/O(也成为二进制I/O)。fread和fwrite函数支持这种类型的I/O。每次I/O操作读或写某种数量的对象,而每个对象具有指定的长度。这两个函数常用于从二进制文件中每次读或写一个结构。
4)补充:格式化I/O函数,例如printf和scanf。
2.2.1 以下三个函数用于一次读一个字符:
头文件:#include
函数原型:
int getc(FILE *fp);
int fgetc(FILE *fp);
int getchar(void);
三个函数的返回值:若成功则返回下一个字符,若已到达文件结尾或出错则返回EOF。
1)fgetc()和getc()用法是相同的,getc()是宏定义函数,fgetc()是一个函数。
2)getchar()从标准输入stdin读入一个字符,程序等待你输入的时候,你可以输入多个字符,回车后程序继续执行。但getchar只读入一个字符。
3)这三个函数返回值都是返回流中的下一个字符,然后将其由unsigned char类型转换为int类型。
4)EOF是在stdio.h文件中定义的符号常量,值为-1。EOF不是可输出字符,因此不能在屏幕上显示。
2.2.2 以下三个函数用于一次输出一个字符:
头文件:#include
函数原型:
int putc(int c, FILE *fp);
int fputc(int c, FILE *fp);
int putchar(int c);
三个函数的返回值:若成功则返回c,若出错则返回EOF。
2.3.1 以下两个函数每次输入一行:
头文件:#include
函数原型:
char *fgets(char *restrict buf, int n, FILE *restrict fp);
char *gets(char *buf);
返回值:若成功则返回buf,若已到达文件结尾或出错则返回NULL;
1)这两个函数都指定了缓冲区地址,读入的行将送入其中。gets从标准输入读,而fgets从指定的流读。
2)fgets必须指定缓冲区的长度n。当读取 (n-1) 个字符时,或者读取到换行符时,或者到达文件末尾时,它会停止。读入的字符被送入到缓冲区。该缓冲区以null字符结尾。如果该行的字符数(包括最后一个换行符)超过了n-1,fgets返回一个不完整的行,当fgets下一次调用时会继续读改行剩余的内容。
3)gets是一个不推荐使用的函数。其问题是使用者在使用gets时不能指定缓冲区的长度,这样可能造成缓冲区溢出(如若该行长于缓冲区长度),写到缓冲区之后的存储空间中,从而产生不可预料的后果。
4)gets与fgets的另一个区别是,gets并不将换行符存入缓冲区中。
2.3.2 以下两个函数每次输出一行:
头文件:#include
函数原型:
int *fputs(const char *restrict str, FILE *restrict fp);
int *puts(const char *str);
返回值:若成功则返回非负值,若出错则返回EOF;
1)fputs将一个以null符终止的字符串写到指定的流,尾端的终止符null不写出。通常,在null符之前是一个换行符,但并不要求总是如此。
2)puts将一个以null符终止的字符串写到标准输出,终止符不写出。但是,puts会将换行符写到标准输出。
2.4.1 直接I/O(二进制I/O)
当我们要读或写一整个结构时(比如写一个结构体)如果使用getc/fgetc或putc/fputc读写一个结构,那么必须循环通过整个结构,每次循环处理一个字节,一次读或写一个字节,这会非常麻烦而且费时。如果使用fputs和fgets,在输出时,fputs在遇到null字符就停止,而结构中可能含有null字符,所以不能使用它实现读结构的要求。在输入时如果输入数据包含有null字符或换行符,则fgets也不能正确工作。因此需要下列两个函数执行二进制I/O操作。
头文件:#include
函数原型:
size_t fread(void *restrict ptr, size_t size, size_t nobj, FILE *restrict fp);
函数作用:读取文件内容到缓冲区中。
size_t fwrite(const void *restrict ptr, size_t size, size_t nobj, FILE *restrict fp);
函数作用:将缓冲区的内容写入到文件中。
两个函数的返回值:读或写的对象数;
两种常见的用法:
1)读或写一个二进制数组,例如,为了将一个浮点数组的第2~5个元素写至一个文件上,可以编写如下程序:
float data[10];
if(fwrite(&data[2], sizeof(float), 4, fp) != 4)
err_sys("fwrite error");
其中,指定size为每个数组元素的长度,nobj为欲写的元素个数;
2)读或写一个结构。例如,
struct{
short count;
long total;
char name[NAMESIZE];
}item;
if(fwrite(&item, sizeof(item), 1, fp) != 1)
err_sys("fwrite error");
其中,指定sizeof(item)为结构体的长度,nobj为1表示欲写的对象个数;
说明:
1)对于fread,如果出错或达到文件尾端,则此数字可以少于nobj。这种情况下,应调用ferror或feof以判断属于哪一种情况
2)通常fread的返回值是一个非负整数,如果返回值为负数肯定出错了。
3)对于fwrite,如果返回值少于要写的nobj,则出错。可用fwrite返回值与nobj比较判断函数执行是否出错。
2.4.2 feof与ferror
头文件:#include
函数原型:int feof(FILE * stream);
相关函数 fopen,fgetc,fgets,fread。
函数作用:检查文件流是否读到了文件尾。
函数说明: feof()用来侦测是否读取到了文件尾(EOF),参数stream为fopen()所返回之文件指针。如果出错或者文件指针到了文件末尾(EOF)则返回 TRUE,否则返回 FALSE。即如果已到文件尾则返回非零值,其他情况返回0。
返回值 返回非零值代表已到达文件尾。
用法:
while(!feof(pf)) {
ch = fgetc(pf);
putchar(ch);
fputc(ch, pf2);
}
头文件:#include
函数原型:int ferror(FILE *stream);
相关函数 fopen,fgetc,fgets,fread。
函数作用:测试给定流 stream 的错误标识符。
返回值 如果设置了与流关联的错误标识符,该函数返回一个非零值,否则返回一个零值。
用法:
c = fgetc(fp);
if( ferror(fp) )
{
printf("read file error!\n");
}
clearerr(fp);
如果我们试图打开一个只写的空文件,就会出错。clearerr(fp);用于清空流中的错误标识符。
2.5 特别说明
fgets函数从stream所指的文件中读取以'\n'结尾的一行(包括'\n'在内)存到缓冲区s中,并且在该行末尾添加一个 '\0'组成完整的字符串。
对于 fgets() 来说,'\n' 是一个特别的字符,而 '\0' 并无任何特别之处,如果读到 '\0'就当作普通字符读入。如果文件中存在 '\0' 字符(或者说0x00字节),调用fgets() 之后就无法判断缓冲区中的 '\0' 究竟是从文件读上来的字符还是由 fgets() 自动添加的结束符,所以 fgets() 只适合读文本文件而不适合读二进制文件,并且文本文件中的所有字符都应该是可见字符,不能有 '\0'。
3、以二进制文件和文本文件的读写为例,来深化上述理论的学习。
着重学习fopen,fread,fwrite函数;fgetc,fputc函数为例;
3.1 使用fopen,fread,fwrite函数实现二进制文件、文本文件复制。设置不同的数据段长度COUNT,来看一看文件读写的准确性和效率。
#include
#include
#include
#define COUNT 1024
/*
*复制文件
*/
int file_copy(char *str, char *dstr)
{
FILE *sp = NULL;
FILE *fp = NULL;
char ch[COUNT] = {0};
int i = 0;
int count = 0;
if((str == NULL) || (dstr == NULL))
{
printf("input parameter is NULL!\n");
return -1;
}
//打开二进制文件rb,文本文件r
sp = fopen(str, "rb");
if(sp == NULL)
{
printf("open file %s failed!\n", str);
return -1;
}
fp = fopen(dstr, "ab");
if(fp == NULL)
{
printf("open file %s failed!\n", dstr);
return -1;
}
struct stat f_stat;
if (stat(str, &f_stat) == -1)
{
fclose(sp);
fclose(fp);
return -1;
}
f_stat.st_size;
if(f_stat.st_size % COUNT == 0)
{
count = f_stat.st_size / COUNT;
}
else
{
count = f_stat.st_size / COUNT + 1;
}
printf("count = %d , f_stat.st_size = %d \n", count, f_stat.st_size);
for(i = 0; i < count; i++)
{
if(fread(ch, sizeof(char), COUNT, sp) != COUNT)
{
//如果出错或者文件指针到了文件末尾(EOF)则返回 TRUE,否则返回 FALSE。
if(feof(sp))
{
//如果设置了与流关联的错误标识符,该函数返回一个非零值,否则返回一个零值。
if( ferror(sp) )
{
printf("read file %s error!\n", str);
fclose(sp);
fclose(fp);
return -1;
}
else
{
printf("remainder = %d \n", f_stat.st_size % COUNT);
if(fwrite(ch, sizeof(char), f_stat.st_size % COUNT, fp) != f_stat.st_size % COUNT)
{
printf("write file %s error!\n", dstr);
fclose(sp);
fclose(fp);
return -1;
}
}
clearerr(fp);//清除错误标识符
break;
}
}
else
{
if(fwrite(ch, sizeof(char), COUNT, fp) != COUNT)
{
printf("write file %s error!\n", dstr);
fclose(sp);
fclose(fp);
return -1;
}
}
}
fclose(sp);
fclose(fp);
return 0;
}
int main(int argc, char *argv[])
{
int ret = 0;
printf("%s %d argc:%d\r\n", __FUNCTION__, __LINE__, argc );
if((argv[1] == NULL) || (argv[2] == NULL) || (argc < 3))
{
printf("input parameter is NULL!\n");
return -1;
}
printf("argv0 = %s\r\n", argv[0]);
printf("argv1 = %s\r\n", argv[1]);
printf("argv1 = %s\r\n", argv[2]);
ret = file_copy( argv[1], argv[2]);
if(ret != 0)
{
printf("file_copy error!\n");
}
return 0;
}
注意每次读写的数据块大小COUNT 与循环读写次数count 的关系:
设置COUNT = 1
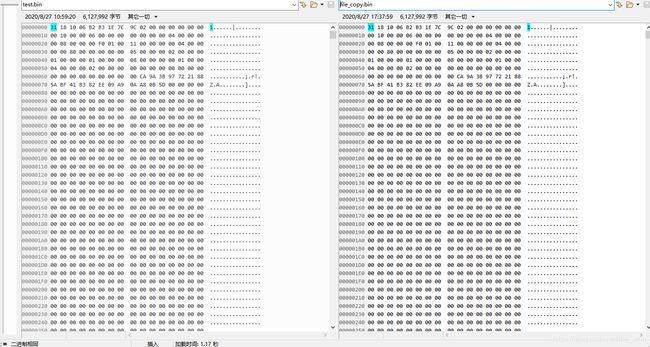
$ ./file_copy test.bin file_copy_result.bin
main 109 argc:3
argv0 = ./file_copy
argv1 = test.bin
argv1 = file_copy_result.bin
count = 6127992 , f_stat.st_size = 6127992
下图是用compare软件做二进制对比的结果,复制的二进制文件与原文件一致。
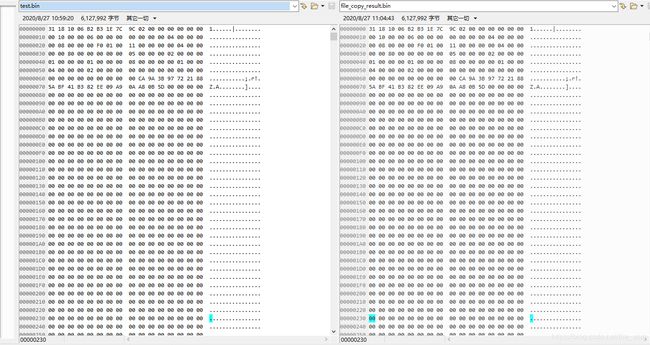
COUNT = 256
$ ./file_copy test.bin file_copy_result.bin
main 126 argc:3
argv0 = ./file_copy
argv1 = test.bin
argv1 = file_copy_result.bin
count = 23938 , f_stat.st_size = 6127992
remainder = 120

COUNT = 512
$ ./file_copy test.bin file_copy_result.bin
main 125 argc:3
argv0 = ./file_copy
argv1 = test.bin
argv1 = file_copy_result.bin
count = 11969 , f_stat.st_size = 6127992
remainder = 376
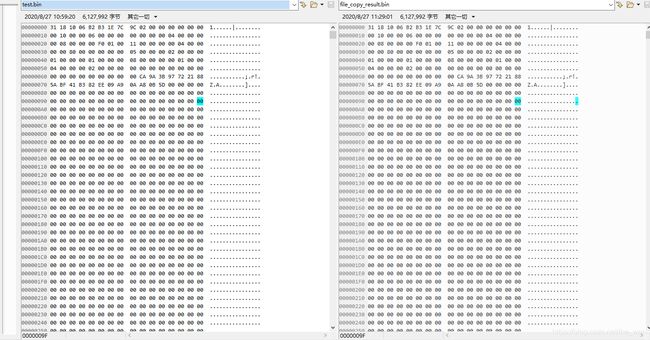
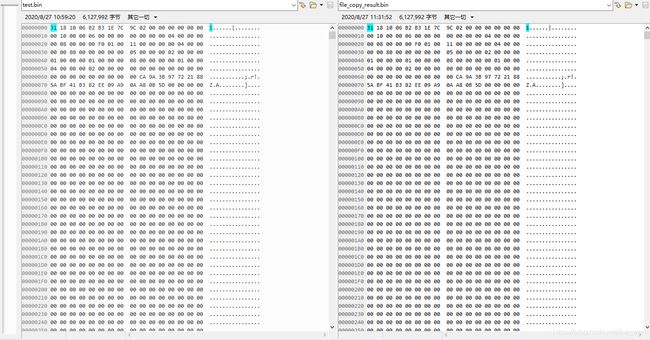
COUNT = 1024
$ ./file_copy test.bin file_copy_result.bin
main 125 argc:3
argv0 = ./file_copy
argv1 = test.bin
argv1 = file_copy_result.bin
count = 5985 , f_stat.st_size = 6127992
remainder = 376
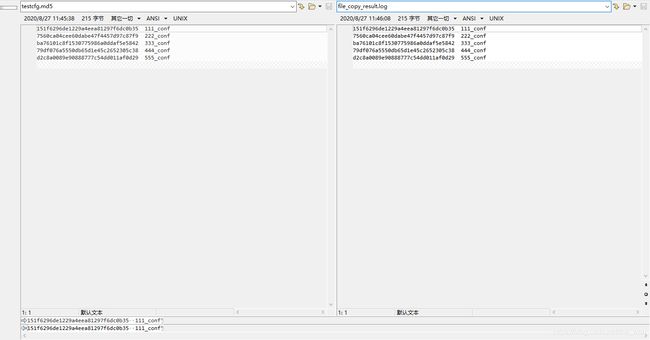
读Md5文件,注意修改fopen打开文件方式:
sp = fopen(str, "r");
if(sp == NULL)
{
printf("open file %s failed!\n", str);
return -1;
}
fp = fopen(dstr, "a");
if(fp == NULL)
{
printf("open file %s failed!\n", dstr);
return -1;
}COUNT = 1024
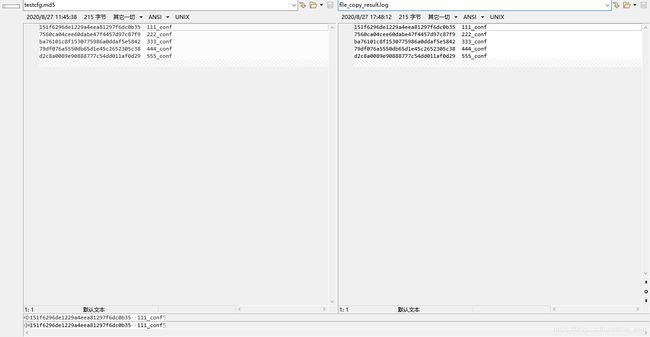
$ ./file_copy testcfg.md5 file_copy_result.log
main 125 argc:3
argv0 = ./file_copy
argv1 = testcfg.md5
argv1 = file_copy_result.log
count = 1 , f_stat.st_size = 215
remainder = 215
读日志文件:
COUNT = 1024
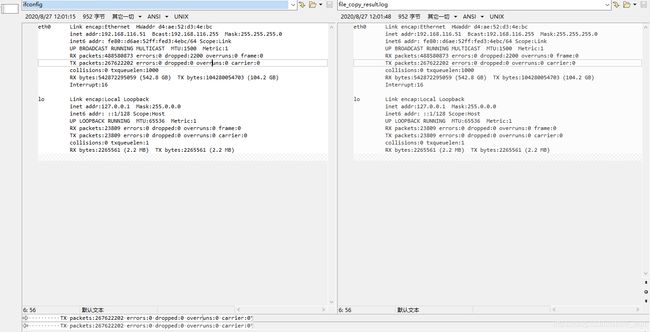
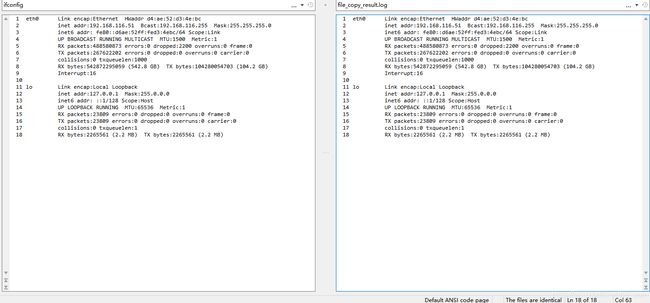
$ ./file_copy ifconfig file_copy_result.log
main 125 argc:3
argv0 = ./file_copy
argv1 = ifconfig
argv1 = file_copy_result.log
count = 1 , f_stat.st_size = 952
remainder = 952
3.1 使用fopen,fgetc,fputc函数实现二进制文件、文本文件复制。
#include
#include
#include
/*
*复制文件
*/
int file_copy(char *str, char *dstr)
{
FILE *sp = NULL;
FILE *fp = NULL;
int ret = 0;
int ch;
if((str == NULL) || (dstr == NULL))
{
printf("input parameter is NULL!\n");
return -1;
}
//打开二进制文件rb,文本文件r
sp = fopen(str, "rb");
if(sp == NULL)
{
printf("open file %s failed!\n", str);
return -1;
}
fp = fopen(dstr, "ab");
if(fp == NULL)
{
printf("open file %s failed!\n", dstr);
return -1;
}
//如果出错或者文件指针到了文件末尾(EOF)则返回 TRUE,否则返回 FALSE。
while(!feof(sp))
{
ch = fgetc(sp);
if(ch != EOF)
{
ret = fputc(ch, fp);
if(ret == EOF)
{
printf("write file %s error!\n", dstr);
fclose(sp);
fclose(fp);
return -1;
}
}
}
fclose(sp);
fclose(fp);
return 0;
}
int main(int argc, char *argv[])
{
int ret = 0;
printf("%s %d argc:%d\r\n", __FUNCTION__, __LINE__, argc );
if((argv[1] == NULL) || (argv[2] == NULL) || (argc < 3))
{
printf("input parameter is NULL!\n");
return -1;
}
printf("argv0 = %s\r\n", argv[0]);
printf("argv1 = %s\r\n", argv[1]);
printf("argv1 = %s\r\n", argv[2]);
ret = file_copy( argv[1], argv[2]);
if(ret != 0)
{
printf("file_copy error!\n");
}
return 0;
}
读二进制文件:
$ ./file_copy_fgetc test.bin file_copy.bin
main 73 argc:3
argv0 = ./file_copy_fgetc
argv1 = test.bin
argv1 = file_copy.bin
$
读Md5文件:
$ ./file_copy_fgetc testcfg.md5 file_copy_result.log
main 71 argc:3
argv0 = ./file_copy_fgetc
argv1 = testcfg.md5
argv1 = file_copy_result.log
$
读日志文件:
$ ./file_copy_fgetc ifconfig file_copy_result.log
main 71 argc:3
argv0 = ./file_copy_fgetc
argv1 = ifconfig
argv1 = file_copy_result.log
$
4 格式化IO
4.1 格式化输出
头文件:#include
函数原型:
int printf(const char *restrict format, ...);
int fprintf(FILE *restrict fp, const char *restrict format, ...);
返回值:两个函数的返回值,若成功则返回输出的字符数,若输出出错则返回负值。
思考:printf函数返回0是什么意思?
int sprintf(char *restrict buf, const char *restrict format, ...);
int fprintf(char *restrict buf, size_t n, const char *restrict format, ...);
返回值:两个函数的返回值,若成功则返回存入数组的字符数,若编码出错则返回负值。
1)printf将格式化数据写到标准输出。
2)fprintf将数据写入到指定的流。
3)sprintf将格式化的字符送入数组buf中。sprintf在该数组的尾端自动加一个null字符,但该字符不包括在返回值中。
sprintf函数可能会造成由buf指向的缓冲区的溢出,调用者需确保缓冲区足够大。
4)snprintf函数解决了sprintf函数缓冲区溢出问题。在该函数中,缓冲区长度是一个显示参数,超过缓冲区尾端写的任何字符都会被丢弃。如果缓冲区足够大,snprintf函数就会返回写入缓冲区的字符数。snprintf在该数组的尾端自动加一个null字符,但该字符不包括在返回值中。若snprintf函数返回小于缓冲区长度n的正值,那么没有截短输出。
5)格式说明控制:
%[flags][fldwidth][precision][lenmodifier]convtype
flags标志:

fldwidth说明转换的最小字段宽度。如果转换得到的字符较少,则用空格填充。字段宽度是一个非负十进制数,或是一个星号(*)。
precision说明整形转换后最少输出数字位数、浮点数转换后小数点后的最少位数、字符串转换后的最大字符数。精度是一个局点(.),后接一个可选的非负十进制整数或是一个星号(*)。
lenmodifier说明参数长度,其可能取值如下表。

convtype控制如何解释参数,如下表所示。

4.2 格式化输入
头文件:#include
函数原型:
int scanf(const char *restrict format, ...);
int fscanf(FILE *restrict fp, const char *restrict format, ...);
int sscanf(const char *restrict buf, const char *restrict format, ...);
返回值:三个函数的返回值,指定的输入项数;若输入出错或在任意变换前已达到文件结尾则返回EOF。
1)scanf函数族用于分析输入字符串,并将字符序列转换成指定类型的变量。格式之后的各参数包含了变量的地址,用于转换结果初始化这些变量。
2)格式说明控制:
%[*][fldwidth][precision][lenmodifier]convtype
fldwidth说明转换的最大字段宽度。
lenmodifier说明说明要转换结果初始化的参数大小。
convtype控制如何解释参数,如下表所示。

参考:格式化I/O函数的总结可参考以下博文,总结的很到位。
https://blog.csdn.net/zhangna20151015/article/details/52794982 Linux C 字符串输入函数 gets()、fgets()、scanf() 详解
https://www.cnblogs.com/52php/p/5724372.html scanf,sscanf,fscanf
引用以下资料,衷心感谢大家的分享:
https://blog.csdn.net/zhangna20151015/article/details/52794982
https://www.cnblogs.com/52php/p/5724372.html
UNIX环境高级编程