字节码与常量池和JVM内存原理
字节码与常量池
- JVM模型
-
- 模型图
- 模型图解析
- 常量池
-
- 常量池表
- 常量池表举例
JVM模型
模型图

模型图解析
1.JVM主要包括了图中的三块,分别是方法区,堆,以及线程独有的区域。
2.其中方法区中包括了类变量,类信息,方法信息以及常量池。
常量池
1.常量池以表的形式存在
2.常量池用于存储编译期间生成的字面量和符号引用。值得注意的是,运行期间产生的新的常量也可被存储到常量池中,例如String中的intern方法。常量池就是这个类型用到的常量的一个有序集合。包括直接常量(基本类型,String)和对其他类型、方法、字段的符号引用.
常量池表
常量池中每一项常量都是一个表,jdk1.8有14种结构不同的表结构,这14个表有个共同特点,就是表开始的第一位都是一个u1类型的标志位,JVM根据这个标志位[tag]来确定某个常量池项表示什么类型的字面量,比如tag为1就是指CONSTANT_utf8_info。
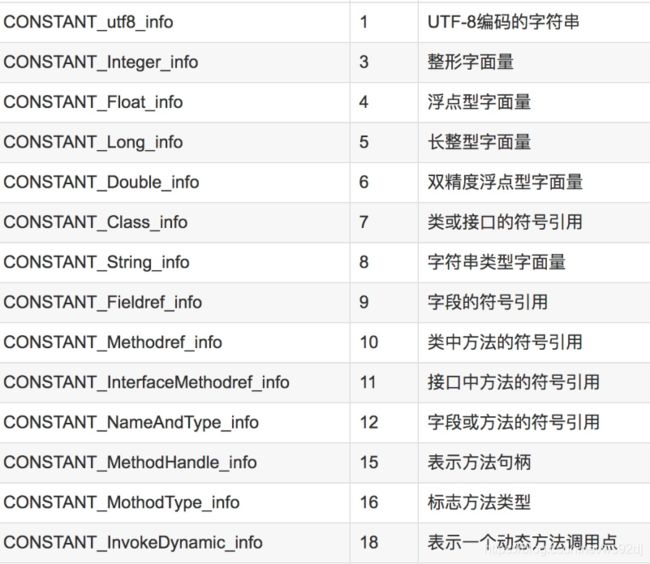
常量池表举例
1.CONSTANT_utf8_info:代码中的输出就是字符串“你好世界的”UTF8格式。即该常量表就是保存字符串的unicode编码的。
public class U8 {
static String string = "你好世界";
public static void main(String[] args) {
for (int i = 0;i < string.length();i++){
System.out.print("\\u" + Integer.toHexString(string.charAt(i)));
}
}
}
//OUTPUT: \u4f60\u597d\u4e16\u754c
2.CONSTANT_INTEGER_info:
public class IntegerInfo {
public static void main(String[] args) {
Integer integer1 = 127;
Integer integer2 = 127;
Integer integer3 = 128;
Integer integer4 = 128;
System.out.println("integer1 == integer2:" + (integer1 == integer2));
System.out.println("integer3 == integer4:"+(integer3 == integer4));
}
}
//OUTPUT: integer1 == integer2:true
// integer3 == integer4:false
上面的代码片段中,integer1 == integer为真值,是因为直接赋值的Integer类型在常量池中的范围是-128~127。此时符号引用integer1和integer2都直接指向常量池中值为127的CONSTANT_INTEGER_info。因此值为TRUE。而如果超出了范围呢?会在堆中new出一个Integer来存放值。
3.CONSTANT_String_info:
CONSTANT_String_info {
u1 tag;
u2 string_index; //存放指向CONSTANT_UTF8_info的指针
}
可以看到,这个表的本身不存放任何字符串数据,而只是存放了一个指向CONSTANT_UTF8_info的指针。
public class StringInfo {
public static void main(String[] args) {
String string1 = "hello";
String string2 = "hello";
System.out.printf("string1 == string2: " + (string1 == string2));
}
}
//true
为什么此时的string1和string2是一样的?从下面的字节码文件可以看出来在常量池中只保存了一个hello字符串。两个符号引用都指向CONSTANT_UTF8_info中hello字符串的Unicode字节码。因此,它们相等。
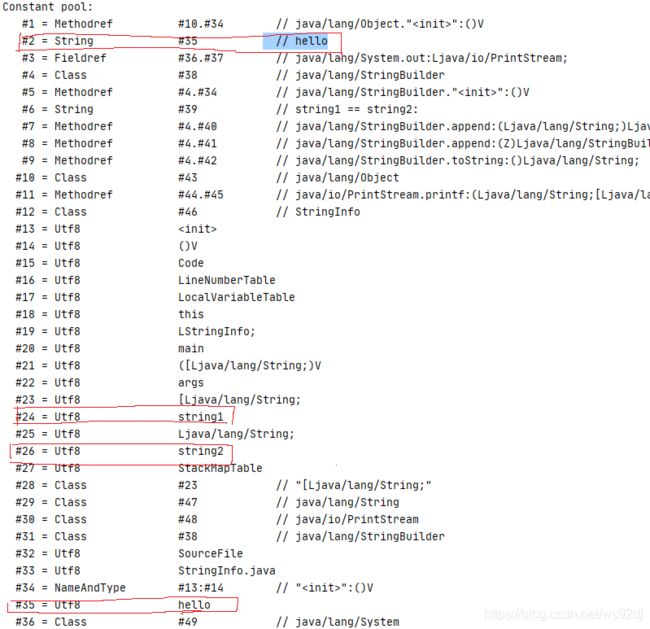
public class StringInfo2 {
public static void main(String[] args) {
String string3 = "hello";
String string4 = new String("hello");
System.out.print("string3 == string4: " +(string3 == string4));
}
}
//output:false
string3和string4不相等,因为string4是指向堆中的String对象,因此他们是不等的。
public class StringInfo3 {
public static void main(String[] args) {
String string5 = "hello";
String string6 = new String("hello").intern();
System.out.println("string5 == string6: "+(string5 == string6));
}
}
//output:true
string5和string6相等,因为intern方法返回常量池里字面值。如果常量池中没有这个字面值,那么先把这个字面值放入常量表里之后返回。
public class StringInfo4 {
public static void main(String[] args) {
String stringa = "aaabb";
String stringb = "aaa"+"bb";
System.out.println("stringa == stringb: "+(stringa == stringb));
}
}
//stringa == stringb: true
可以看到上边的代码中利用+拼接的字符串和直接写在一起的字符串是相等的,下面上字节码:

可以看到在编译的时候,两个引用所指向的字符串就已经是一样的了,字符串拼接是在编译期间完成的。他们指向常量池中的同一个String表。
 继续看下面一段代码:
继续看下面一段代码:
public class StringInfo5 {
public static void main(String[] args) {
String stringFuck = "fuck";
String stringFu = "fu";
String stringFuck2 = stringFu + "ck";
System.out.println(stringFuck == stringFuck2);
}
}
//false
这段代码输出的是false,先看下字节码:
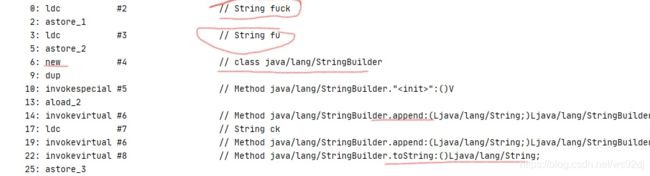
可以很明显地看出来,此时是通过new出一个StringBuilder对象,通过该对象的append方法拼接了两个字符串,再调用该对象的toString方法返回,而该类的toString方法是new了一个新的String对象,因此是false也就很明显了。