Spark学习案例——SparkSQL结合Kudu实现广告业务分析
下方有数据可免费下载
目录
- 原始数据
- 项目架构
- ETL处理
- 业务一
- 业务二
- 业务三
- 代码重构
- 打包定时运行
源码地址https://github.com/chengyanban/spark-project/tree/master/广告数据分析
原始数据
下载数据: 请点击我.提取码:3bm9
有两个文件,一个广告业务的data-test.json,一个ip.txt文件
项目架构
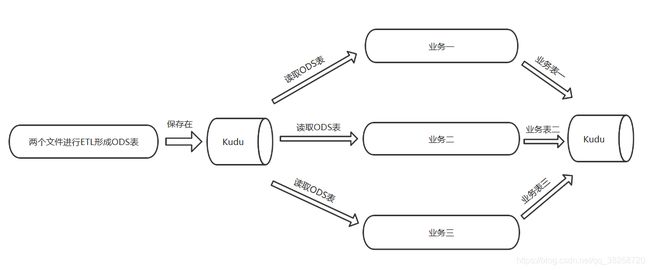
ETL处理
data-test.json文件中每行有ip地址,需通过ip.txt文件进行解析,解析出地名,运营商等信息。但是data-test.json中的ip格式为123.23.3.11,而ip.txt中的ip格式为16777472——16778239十进制的形式,需将ip转化为十进制,判断是否在其范围内。
def ip2Long(ip:String)={
val splits = ip.split("[.]")
var ipNum = 0L
for (i <- 0.until(splits.length)){
ipNum = splits(i).toLong | ipNum << 8L
}
ipNum
}
读取两个文件形成DF,再创造临时视图,再通过join产生ODS表
jsonDF.createOrReplaceTempView("logs")
ipRuleDF.createOrReplaceTempView("ips")
lazy val SQL = "select " +
"logs.ip ," +
...
...
...
"logs.sessionid," +
"from logs left join " +
"ips on logs.ip_long between ips.start_ip and ips.end_ip "
业务一
统计每个省每个城市的数量
select provincename, cityname, count(1) as cnt from ods group by provincename,cityname
object ProvinceCityStatProcess extends DataProcess{
override def process(spark:SparkSession): Unit = {
val sourceTableName = DateUtils.getTableName("ods", spark)
val masterAdress = "hadoop000"
//第一步,读取ODS表
val odsDF = spark.read.format("org.apache.kudu.spark.kudu")
.option("kudu.master", masterAdress)
.option("kudu.table", sourceTableName)
.load()
//odsDF.show()
//第二步,建立视图根据业务进行SQL分析
odsDF.createOrReplaceTempView("ods")
val result = spark.sql(SQLUtils.PROVINCE_CITY_SQL)
//result.show()
val KUDU_MASTERS = "hadoop000"
val tableName = DateUtils.getTableName("province_city_stat", spark)
val partitionID = "provincename"
val schema = SchemaUtils.ProvinceCitySchema
//第三步,将得到的DF写入到Kudu中
KuduUtils.sink(result,tableName, KUDU_MASTERS, schema,partitionID)
}
业务二
地区分布指标
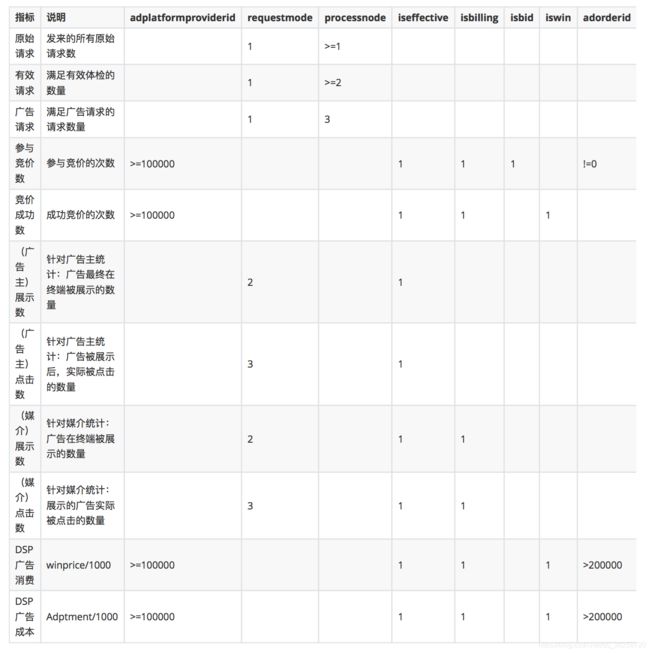
业务三
APP统计直播
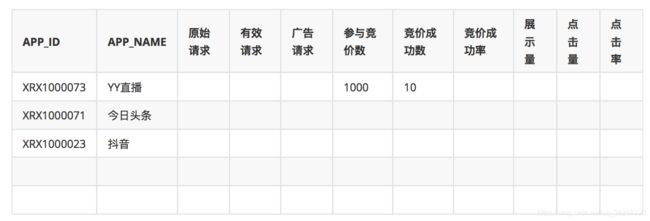
代码重构
1.创建一个trait文件
trait DataProcess {
def process(spark:SparkSession)
}
2.各种业务(object实例文件)只需要去实现process()这个函数就行,如上业务一,继承DataProcess,并实现process()。
object ProvinceCityStatProcess extends DataProcess{
override def process(spark:SparkSession): Unit = {
...
//第一步,读取ODS表
//第二步,建立视图根据业务进行SQL分析
//第三步,将得到的DF写入到Kudu中
...
}
3.程序mian入口
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().getOrCreate()
val time = spark.sparkContext.getConf.get("spark.time") // spark框架只认以spark.开头的参数,否则系统不识别
if(StringUtils.isBlank(time)) { // 如果是空,后续的代码就不应该执行了
logError("处理批次不能为空....")
System.exit(0)
}
//ETL,每个业务就运行process()函数,都有统一的SparkSession
LogETLProcessor.process(spark)
//业务一
ProvinceCityStatProcess.process(spark)
//业务二
AreaStatProcess.process(spark)
//业务三
AppStatProcess.process(spark)
spark.stop()
}
4.各种工具类只需调用即可
DateUtils //表名后加日期,一天一处理
IPUtils //ip二进制转换
KuduUtils //写入到Kudu表
SchemaUtils //Kudu表的schema信息
SQLUtils //SQL语句
打包定时运行
//sparksql.sh:
time=20200903
${SPARK_HOME}/bin/spark-submit \
--class com.chengyanban.project.App \
--master local \
--jars /home/hadoop/lib/kudu-client-1.7.0.jar,/home/hadoop/lib/kudu-spark2_2.11-1.7.0.jar \
--conf spark.time=$time \
--conf spark.raw.path="hdfs://hadoop000:8020/muke/sparksql/$time" \
--conf spark.ip.path="hdfs://hadoop000:8020/muke/sparksql/ip.txt" \
/home/hadoop/lib/sparksql-train-1.0.jar
chmod -R 777 sparksql.sh 需要给执行权限
路径前要加hdfs://hadoop000:8020,不加crontab会用本地
crontab -e
28 */17 * * * /home/hadoop/script/sparksql.sh