上位机数据监测系统——ORACLE数据库子系统AWR报告分析(数据库优化分析)
1、Elapsed/DB Time
通过Elapsed/DBTime比较,反映出数据库的繁忙程度。如果DBTime>>Elapsed,则说明数据库很忙。DBTime表示用户操作花费的时间,包括CPU时间和等待事件。通常同时这个数值判读数据库的负载情况。

2、Instance Efficiency Percentages(Target 100%)
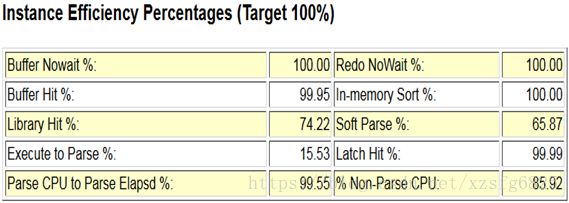
(1)Library Hit %——共享池中SQL解析的命中率。
Library Hit<95%,要考虑加大共享池,绑定变量,修改cursor_sharing等。
(2)Soft Parse %——软解析占总解析数的百分比。
可以近似当作sql在共享区的命中率。这个数值偏低,说明系统中有些SQL没有重用,最优可能的原因就是没有使用绑定变量。
<95%:需要考虑到绑定
<80%:那么就可能sql基本没有被重用
(3)Execute to Parse %——执行次数对分析次数的百分比。
如果该值偏小,说明解析(硬解析和软解析)的比例过大,快速软解析比例小。根据实际情况,可以适当调整参数session_cursor_cache,以提高会话中sql执行的命中率。
round(100*(1-:prse/:exe),2) 即(Execute次数 - Parse次数)/Execute次数 x 100%
prse = select value from v$sysstat where name = 'parsecount (total)';
exe = select value from v$sysstat where name ='execute count';
没绑定的话导致不能重用也是一个原因,当然sharedpool太小也有可能,单纯的加session_cached_cursors也不是根治的办法,不同的sql还是不能重用,还要解析。即使是soft parse 也会被统计入 parsecount,所以这个指标并不能反应出fastsoft(pga 中)/soft(shared pool中)/hard(shared pool 中新解析)几种解析的比例。只有在pl/sql的类似循环这种程序中使用使用变量才能避免大量parse,所以这个指标跟是否使用bind并没有必然联系增加session_cached_cursors是为了在大量parse的情况下把soft转化为fast soft而节约资源。
(4)%Non-ParseCPU——CPU非分析时间在整个CPU时间的百分比。
100*(parse time cpu / parse time elapsed)= Parse CPUto Parse Elapsd %
查询实际运行时间/(查询实际运行时间+sql解析时间),太低表示解析消耗时间过多。
3、ForegroundWait Class
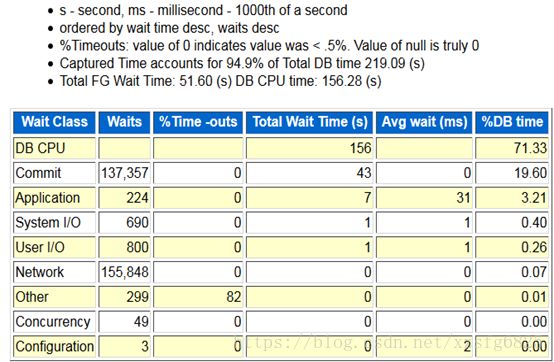
(1)DB CPU 等待时间最长,cpu等待
(2)第二等待时间长的就是commit,一共等待43秒
4、ForegroundWait Events
这一部分是前端等待事件的明细,它包含了TOP5等待事件的信息。

5、BackgroundWait Events
这一部分是实例后台进程的等待事件。如果我们怀疑那个后台进程(比如DBWR)无法及时响应,可以在这里确认一下是否有后台进程等待时间过长的事件存在。

6、SQL ordered by Elapsed Time
如果看到SQL语句执行时间很长,而CPU时间很少,则说明SQL在I/O操作时(包括逻辑I/O和物理I/O)消耗较多。可以结合前面I/O方面的报告以及相关等待事件,进一步分析是否是I/O存在问题。当然SQL的等待时间主要发生在I/O操作方面,不能说明系统就存在I/O瓶颈,只能说SQL有大量的I/O操作。
如果SQL语句执行次数很多,需要关注一些对应表的记录变化。如果变化不大,需要从前面考虑是否大多数操作都进行了Rollback,导致大量的无用功。

7、Tablespace IO Stats——表空间的I/O性能分析
Reads——发生了多少次物理读。
Av Reads/s——每秒钟物理读的次数。
Av Rd(ms)——平均一次物理读的时间(毫秒)。一个高相应的磁盘的响应时间应当在10ms以内,最好不要超过20ms;如果达到了100ms,应用基本就开始出现严重问题甚至不能正常运行。红框内的users02平均一次物理读的时间位64ms,解决的话,可以把users02空间再移动回D盘。
Av Blks/Rd——每次读多少个数据块。
Writes——发生了多少次写。
Av Writes/s——每秒钟写的次数。
Buffer Waits——获取内存数据块等待的次数。
Av Buf Wt(ms)——获取内存数据块平均等待时间。

总结:
通过AWR报告分析可得,开发完成的一个数据库子系统存在不少问题,在部分等待问题上存在严重问题,代码还需要重新整理逻辑,或者通过其他方法来解决该问题。暂时先做一个简单记录,有时间再具体分析。
PS:小菜鸟一枚,刚刚开始学习ORACLE,也欢迎各位大牛帮忙分析分析这里面有啥问题,如有错误恳请指正!