消息队列之事务消息,RocketMQ 和 Kafka 是如何做的?
每个时代,都不会亏待会学习的人。
大家好,我是 yes。
今天我们来谈一谈消息队列的事务消息,一说起事务相信大家都不陌生,脑海里蹦出来的就是 ACID。
通常我们理解的事务就是为了一些更新操作要么都成功,要么都失败,不会有中间状态的产生,而 ACID 是一个严格的事务实现的定义,不过在单体系统时候一般都不会严格的遵循 ACID 的约束来实现事务,更别说分布式系统了。
分布式系统往往只能妥协到最终一致性,保证数据最终的完整性和一致性,主要原因就是实力不允许…因为可用性为王。
而且要保证完全版的事务实现代价很大,你想想要维护这么多系统的数据,不允许有中间状态数据可以被读取,所有的操作必须不可分割,这意味着一个事务的执行是阻塞的,资源是被长时间锁定的。
在高并发情况下资源被长时间的占用,就是致命的伤害,举一个有味道的例子,如厕高峰期,好了懂得都懂。

对了, ACID 是什么还不太清楚的同学,赶紧去查一查,这里我就不展开说了。
分布式事务
那说到分布式事务,常见的有 2PC、TCC 和事务消息,这篇文章重点就是事务消息,不过 2PC 和 TCC 我稍微提一下。
2PC
2PC 就是二阶段提交,分别有协调者和参与者两个角色,二阶段分别是准备阶段和提交阶段。
准备阶段就是协调者向各参与者发送准备命令,这个阶段参与者除了事务的提交啥都做了,而提交阶段就是协调者看看各个参与者准备阶段都 o 不 ok,如果有 ok 那么就向各个参与者发送提交命令,如果有一个不 ok 那么就发送回滚命令。
这里的重点就是 2PC 只适用于数据库层面的事务,什么意思呢?就是你想在数据库里面写一条数据同时又要上传一张图片,这两个操作 2PC 无法保证两个操作满足事务的约束。
而且 2PC 是一种强一致性的分布式事务,它是同步阻塞的,即在接收到提交或回滚命令之前,所有参与者都是互相等待,特别是执行完准备阶段的时候,此时的资源都是锁定的状态,假如有一个参与者卡了很久,其他参与者都得等它,产生长时间资源锁定状态下的阻塞。
总体而言效率低,并且存在单点故障问题,协调者是就是那个单点,并且在极端条件下存在数据不一致的风险,例如某个参与者未收到提交命令,此时宕机了,恢复之后数据是回滚的,而其他参与者其实都已经执行了提交事务的命令了。
TCC
TCC 能保证业务层面的事务,也就是说它不仅仅是数据库层面,上面的上传图片这种操作它也能做。
TCC 分为三个阶段 try - confirm - cancel,简单的说就是每个业务都需要有这三个方法,先都执行 try 方法,这一阶段不会做真正的业务操作,只是先占个坑,什么意思呢?比如打算加 10 个积分,那先在预添加字段加上这 10 积分,这个时候用户账上的积分其实是没有增加的。
然后如果都 try 成功了那么就执行 confirm 方法,大家都来做真正的业务操作,如果有一个 try 失败了那么大家都执行 cancel 操作,来撤回刚才的修改。
可以看到 TCC 其实对业务的耦合性很大,因为业务上需要做一定的改造才能完成这三个方法,这其实就是 TCC 的缺点,并且 confirm 和 cancel 操作要注意幂等,因为到执行这两步的时候没有退路,是务必要完成的,因此需要有重试机制,所以需要保证方法幂等。
事务消息
事务消息就是今天文章的主角了,它主要是适用于异步更新的场景,并且对数据实时性要求不高的地方。
它的目的是为了解决消息生产者与消息消费者的数据一致性问题。
比如你点外卖,我们先选了炸鸡加入购物车,又选了瓶可乐,然后下单,付完款这个流程就结束了。

而购物车里面的数据就很适合用消息通知异步删除,因为一般而言我们下完单不会再去点开这个店家的菜单,而且就算点开了购物车里还有这些菜品也没有关系,影响不大。
我们希望的就是下单成功之后购物车的菜品最终会被删除,所以要点就是下单和发消息这两个步骤要么都成功要么都失败。
RocketMQ 事务消息
我们先来看一下 RocketMQ 是如何实现事务消息的。
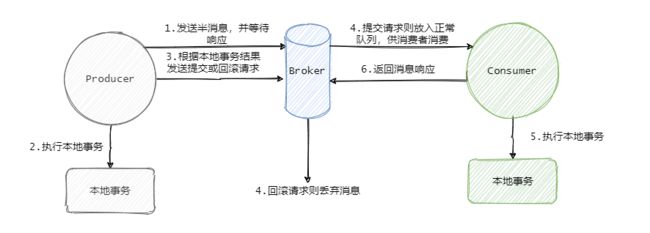
RocketMQ 的事务消息也可以被认为是一个两阶段提交,简单的说就是在事务开始的时候会先发送一个半消息给 Broker。
半消息的意思就是这个消息此时对 Consumer 是不可见的,而且也不是存在真正要发送的队列中,而是一个特殊队列。
发送完半消息之后再执行本地事务,再根据本地事务的执行结果来决定是向 Broker 发送提交消息,还是发送回滚消息。
此时有人说这一步发送提交或者回滚消息失败了怎么办?
影响不大,Broker 会定时的向 Producer 来反查这个事务是否成功,具体的就是 Producer 需要暴露一个接口,通过这个接口 Broker 可以得知事务到底有没有执行成功,没成功就返回未知,因为有可能事务还在执行,会进行多次查询。
如果成功那么就将半消息恢复到正常要发送的队列中,这样消费者就可以消费这条消息了。
我们再来简单的看下如何使用,我根据官网示例代码简化了下。

可以看到使用起来还是很简便直观的,无非就是多加个反查事务结果的方法,然后把本地事务执行的过程写在 TransationListener 里面。
至此 RocketMQ 事务消息大致的流程已经清晰了,我们画一张整体的流程图来过一遍,其实到第四步这个消息要么就是正常的消息,要么就是抛弃什么都不存在,此时这个事务消息已经结束它的生命周期了。
RocketMQ 事务消息源码分析
然后我们再从源码的角度来看看到底是怎么做的,首先我们看下sendMessageInTransaction 方法,方法有点长,不过没有关系结构还是很清晰的。
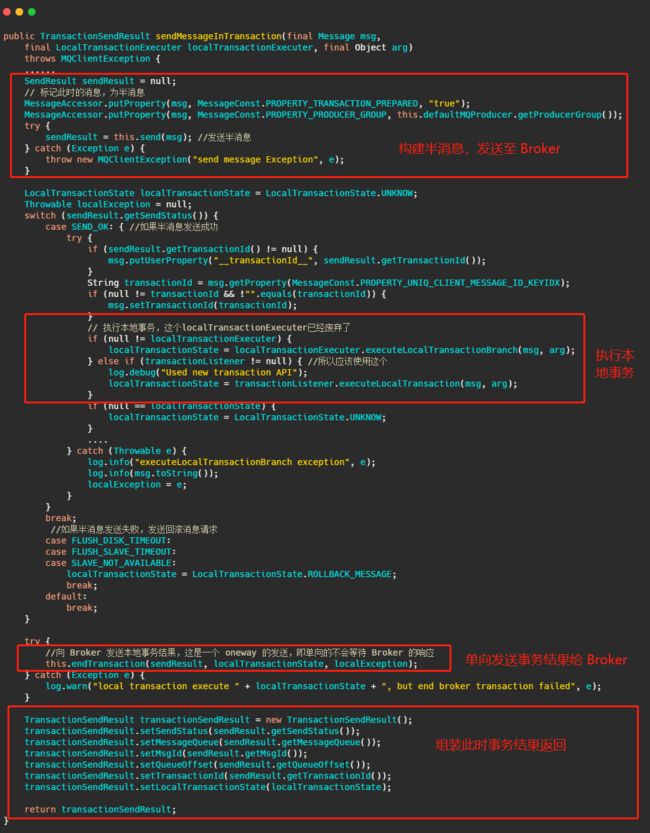
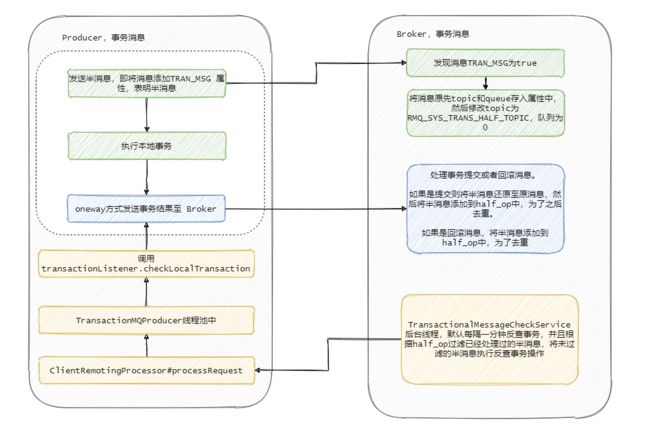
流程也就是我们上面分析的,将消息塞入一些属性,标明此时这个消息还是半消息,然后发送至 Broker,然后执行本地事务,然后将本地事务的执行状态发送给 Broker ,我们现在再来看下 Broker 到底是怎么处理这个消息的。
在 Broker 的 SendMessageProcessor#sendMessage 中会处理这个半消息请求,因为今天主要分析的是事务消息,所以其他流程不做分析,我大致的说一下原理。
简单的说就是 sendMessage 中查到接受来的消息的属性里面MessageConst.PROPERTY_TRANSACTION_PREPARED 是 true ,那么可以得知这个消息是事务消息,然后再判断一下这条消息是否超过最大消费次数,是否要延迟,Broker 是否接受事务消息等操作后,将这条消息真正的 topic 和队列存入属性中,然后重置消息的 topic 为RMQ_SYS_TRANS_HALF_TOPIC,并且队列是 0 的队列中,使得消费者无法读取这个消息。
以上就是整体处理半消息的流程,我们来看一下源码。
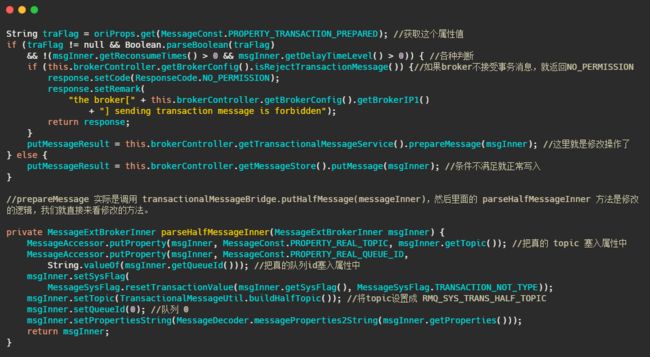
就是来了波狸猫换太子,其实延时消息也是这么实现的,最终将换了皮的消息入盘。
Broker 处理提交或者回滚消息的处理方法是 EndTransactionProcessor#processRequest,我们来看一看它做了什么操作。
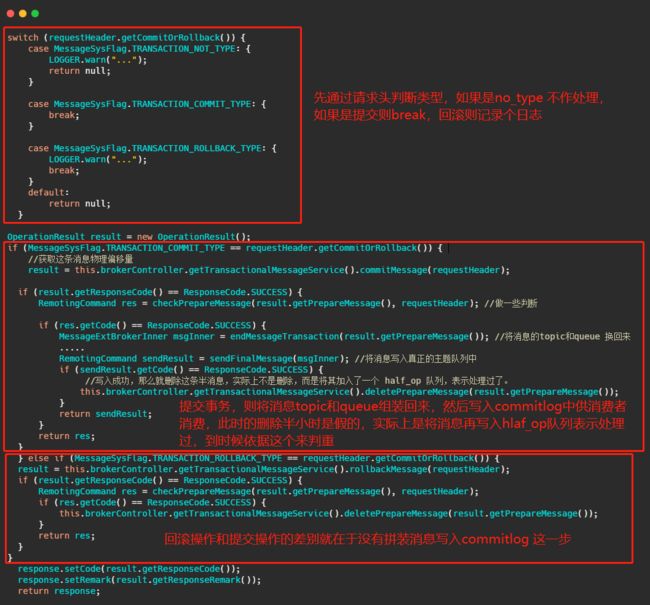
可以看到,如果是提交事务就是把皮再换回来写入真正的topic所属的队列中,供消费者消费,如果是回滚则是将半消息记录到一个 half_op 主题下,到时候后台服务扫描半消息的时候就依据其来判断这个消息已经处理过了。
那个后台服务就是 TransactionalMessageCheckService 服务,它会定时的扫描半消息队列,去请求反查接口看看事务成功了没,具体执行的就是TransactionalMessageServiceImpl#check 方法。
我大致说一下流程,这一步骤其实涉及到的代码很多,我就不贴代码了,有兴趣的同学自行了解。不过我相信用语言也是能说清楚的。
首先取半消息 topic 即RMQ_SYS_TRANS_HALF_TOPIC下的所有队列,如果还记得上面内容的话,就知道半消息写入的队列是 id 是 0 的这个队列,然后取出这个队列对应的 half_op 主题下的队列,即 RMQ_SYS_TRANS_OP_HALF_TOPIC 主题下的队列。
这个 half_op 主要是为了记录这个事务消息已经被处理过,也就是说已经得知此事务消息是提交的还是回滚的消息会被记录在 half_op 中。
然后调用 fillOpRemoveMap 方法,从 half_op 取一批已经处理过的消息来去重,将那些没有记录在 half_op 里面的半消息调用 putBackHalfMsgQueue 又写入了 commitlog 中,然后发送事务反查请求,这个反查请求也是 oneWay,即不会等待响应。当然此时的半消息队列的消费 offset 也会推进。

然后producer中的 ClientRemotingProcessor#processRequest 会处理这个请求,会把任务扔到 TransactionMQProducer 的线程池中进行,最终会调用上面我们发消息时候定义的 checkLocalTransactionState 方法,然后将事务状态发送给 Broker,也是用 oneWay 的方式。
看到这里相信大家会有一些疑问,比如为什么要有个 half_op ,为什么半消息处理了还要再写入 commitlog 中别急听我一一道来。
首先 RocketMQ 的设计就是顺序追加写入,所以说不会更改已经入盘的消息,那事务消息又需要更新反查的次数,超过一定反查失败就判定事务回滚。
因此每一次要反查的时候就将以前的半消息再入盘一次,并且往前推进消费进度。而 half_op 又会记录每一次反查的结果,不论是提交还是回滚都会记录,因此下一次还循环到处理此半消息的时候,可以从 half_op 得知此事务已经结束了,因此就被过滤掉不需要处理了。
如果得到的反查的结果是 UNKNOW,那 half_op 中也不会记录此结果,因此还能再次反查,并且更新反查次数。
到现在整个流程已经清晰了,我再画个图总结一下 Broker 的事务处理流程。
Kafka 事务消息
Kafka 的事务消息和 RocketMQ 的事务消息又不一样了,RocketMQ 解决的是本地事务的执行和发消息这两个动作满足事务的约束。
而 Kafka 事务消息则是用在一次事务中需要发送多个消息的情况,保证多个消息之间的事务约束,即多条消息要么都发送成功,要么都发送失败,就像下面代码所演示的。

Kafka 的事务基本上是配合其幂等机制来实现 Exactly Once 语义的,所以说 Kafka 的事务消息不是我们想的那种事务消息,RocketMQ 的才是。
讲到这我就想扯一下了,说到这个 Exactly Once 其实不太清楚的同学很容易会误解。
我们知道消息可靠性有三种,分别是最多一次、恰好一次、最少一次,之前在消息队列连环问的文章我已经提到了基本上我们都是用最少一次然后配合消费者端的幂等来实现恰好一次。
消息恰好被消费一次当然我们所有人追求的,但是之前文章我已经从各方面已经分析过了,基本上难以达到。
而 Kafka 竟说它能实现 Exactly Once?这么牛啤吗?这其实是 Kafka 的一个噱头,你要说他错,他还真没错,你要说他对但是他实现的 Exactly Once 不是你心中想的那个 Exactly Once。
它的恰好一次只能存在一种场景,就是从 Kafka 作为消息源,然后做了一番操作之后,再写入 Kafka 中。

那他是如何实现恰好一次的?就是通过幂等,和我们在业务上实现的一样通过一个唯一 Id, 然后记录下来,如果已经记录过了就不写入,这样来保证恰好一次。
所以说 Kafka 实现的是在特定场景下的恰好一次,不是我们所想的利用 Kafka 来发送消息,那么这条消息只会恰巧被消费一次。
这其实和 Redis 说他实现事务了一样,也不是我们心想的事务。
所以开源软件说啥啥特性开发出来了,我们一味的相信,因此其往往都是残血的或者在特殊的场景下才能满足,不要被误导了,不能相信表面上的描述,还得详细的看看文档或者源码。
不过从另一个角度看也无可厚非,作为一个开源软件肯定是想更多的人用,我也没说谎呀,我文档上写的很清楚的,这标题也没骗人吧?
确实,比如你点进震惊xxxx标题的文章,人家也没骗你啥,他自己确实震惊的呢。

再回来谈 Kafka 的事务消息,所以说这个事务消息不是我们想要的那个事务消息,其实不是今天的主题了,不过我还是简单的说一下。
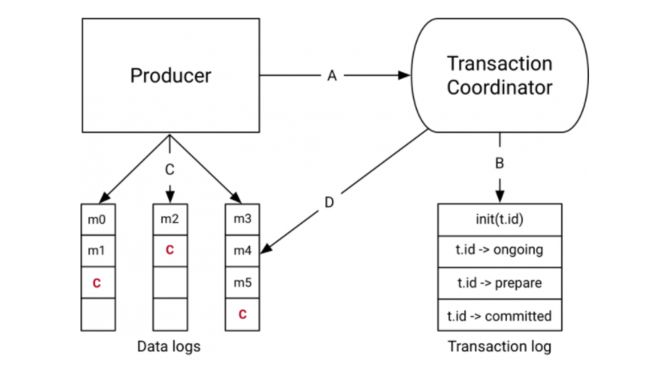
Kafka 的事务有事务协调者角色,事务协调者其实就是 Broker 的一部分。
在开始事务的时候,生产者会向事务协调者发起请求表示事务开启,事务协调者会将这个消息记录到特殊的日志-事务日志中,然后生产者再发送真正想要发送的消息,这里 Kafka 和 RocketMQ 处理不一样,Kafka 会像对待正常消息一样处理这些事务消息,由消费端来过滤这个消息。
然后发送完毕之后生产者会向事务协调者发送提交或者回滚请求,由事务协调者来进行两阶段提交,如果是提交那么会先执行预提交,即把事务的状态置为预提交然后写入事务日志,然后再向所有事务有关的分区写入一条类似事务结束的消息,这样消费端消费到这个消息的时候就知道事务好了,可以把消息放出来了。
最后协调者会向事务日志中再记一条事务结束信息,至此 Kafka 事务就完成了,我拿 confluent.io 上的图来总结一下这个流程。
最后
至此我们已经知道了 RocketMQ 和 Kakfa 的事务消息全流程,可以看到 RocketMQ 的事务消息才是我们想要的,当然你要是用的流式计算那么 Kakfa 的事务消息也是你想要的。
需要贴代码的文章其实很难受,这贴的多不好,贴的少又怕不清晰,真的难,如果觉得文章不错记得点个在看哟。

我是 yes,从一点点到亿点点,我们下篇见。