HiveQL迁移至Spark SQL入门示例(PySpark版)
目录
- 一、示例HiveQL
- 二、迁移至Pyspark
- 三、Linux执行命令
- 四、查看报错的方式
- 五、执行脚本时遇到【XXX not found】报错的处理方式(配置hive-site.xml)
- 六、其他希望读者了解到的
面向群体:为提高可维护性,需要快速将大量HiveQL脚本通过PySpark迁移到Spark SQL的开发人员。
一、示例HiveQL
create table test.test_20190601_1
as
select '${date}${site}${year}${month}${day}${site}' as data_date
;
create table test.test_20190601_2
as
select '${site}${year}${month}${day}${site}' as data_date
;
二、迁移至Pyspark
将以下代码拷贝在普通的文本编辑器保存修改即可。
Python版本:2.7,本次示例脚本命名为 test.py,分Spark 1.6.0、Spark 2.3.0两个版本
Spark 1.6.0:
# -*- coding:UTF-8 -*-
# author:
# date: 2019年06月01日
# desc:
# spark version: 1.6.0
from pyspark.sql import SQLContext, HiveContext
from pyspark import SparkConf, SparkContext
import sys
def main():
# 获取传入的第1个参数,当前工作的环境一般传入的是YYYYMMDD的日期
data_date = sys.argv[1]
# 参数填充
param = {
"date": data_date,
"year": data_date[0:4],
"month": data_date[4:6],
"day": data_date[6:8],
"site": "hahaha"
}
conf = SparkConf()
sc = SparkContext(conf=conf)
# sql_context = SQLContext(sc)
hive_context = HiveContext(sc)
def hive_sql(sql_string):
sql_string_with_param = sql_string.format(**param)
return hive_context.sql(sql_string_with_param)
# 正文开始
# 从hive迁移过来时,将下面的SQL语句替换掉即可,以往被${}包含的参数需要去掉$号
# 被{}包含的参数将被上面param内定义的参数所替换
hive_sql(
"""
create table test.test_20190601_1
as
select '{date}{site}{year}{month}{day}{site}' as data_date
"""
)
# 存在多段sql的可以多次调用这个函数
hive_sql(
"""
create table test.test_20190601_2
as
select '{site}{year}{month}{day}{site}' as data_date
"""
)
# 处理结束
sc.stop()
if __name__ == "__main__":
main()
Spark 2.3.0:
# -*- coding:UTF-8 -*-
# author:
# date: 2019年06月01日
# desc:
# spark version: 2.3.0
from pyspark.sql import SparkSession
from pyspark.conf import SparkConf
import sys
def main():
# 获取传入的第1个参数,当前工作的环境一般传入的是YYYYMMDD的日期
data_date = sys.argv[1]
# 参数填充
param = {
"date": data_date,
"year": data_date[0:4],
"month": data_date[4:6],
"day": data_date[6:8],
"site": "hahaha"
}
spark_session = SparkSession.builder\
.enableHiveSupport()\
.getOrCreate()
def hive_sql(sql_string):
sql_string_with_param = sql_string.format(**param)
return spark_session.sql(sql_string_with_param)
# 正文开始
# 从hive迁移过来时,将下面的SQL语句替换掉即可,以往被${}包含的参数需要去掉$号
# 被{}包含的参数将被上面param内定义的参数所替换
hive_sql(
"""
create table test.test_20190601_1
as
select '{date}{site}{year}{month}{day}{site}' as data_date
"""
)
# 存在多段sql的可以多次调用这个函数
hive_sql(
"""
create table test.test_20190601_2
as
select '{site}{year}{month}{day}{site}' as data_date
"""
)
# 处理结束
spark_session.stop()
if __name__ == "__main__":
main()
迁移时只需简单处理以下几个步骤:
- 在param完成参数填充
- 将需要迁移的HiveQL中的参数处理一下,把${}包含的参数的$号去掉
- 将每一段的处理好的HiveQL复制到hive_sql()函数中,把上面示例中的SQL替换掉,注意保留括号内头尾的6个双引号(
""" 需要执行的HiveQL """)
三、Linux执行命令
# spark-submit --master yarn-cluster --queue 队列名 --executor-memory 1G --executor-cores 1 --num-executors 16 pyspark脚本路径 日期参数
spark-submit --master yarn-cluster --queue root.default --executor-memory 1G --executor-cores 1 --num-executors 16 test.py 20190601
四、查看报错的方式
前几次执行脚本难免会报错,所以要知道如何查看错误。
首先要知道提交的脚本对应的applicationId是什么,这个在提交后的屏幕日志信息可以找到。
以下为日志的示例:
19/05/28 13:00:56 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: XXX.XXX.XXX.XXX
ApplicationMaster RPC port: 0
queue: root.default
start time: 1559048430541
final status: FAILED
tracking URL: http://XXX.XXX.XXX.XXX:8088/proxy/application_1559009311579_0014/history/application_1559009311579_0014/2
user: bigdata
其中application_1559009311579_0014就是我们要找的applicationId。
tracking URL也很有用,下面会提到。
有以下几种方式查看报错:
1. 获取yarn日志
yarn logs -applicationId 【application的id】 > 【application的id】.log
然后打开【application的id】.log,最好通过vi查找
有用的几个快捷键:
翻页(向下翻:ctrl-f,向后翻:ctrl-b)通过以下关键字搜索:(搜索命令【/关键字】 ,重复搜索直接【/】即可)
hive_sql(这个是上面示例的函数名)
Traceback(一般的python报错)
Exception(一般的java报错,但是可能会搜到一些内部可忽略的报错)
以下为报错日志示例:
LogType:stdout
Log Upload Time:Tue May 28 13:00:58 +0000 2019
LogLength:692
Log Contents:
Traceback (most recent call last):
File "abc.py", line 54, in
main()
File "abc.py", line 39, in main
"""
File "abc.py", line 31, in hive_sql
return hive_context.sql(sql_string_with_param)
File "/opt/cloudera/parcels/CDH-5.8.5-1.cdh5.8.5.p0.5/lib/spark/python/lib/pyspark.zip/pyspark/sql/context.py", line 580, in sql
File "/opt/cloudera/parcels/CDH-5.8.5-1.cdh5.8.5.p0.5/lib/spark/python/lib/py4j-0.9-src.zip/py4j/java_gateway.py", line 813, in __call__
File "/opt/cloudera/parcels/CDH-5.8.5-1.cdh5.8.5.p0.5/lib/spark/python/lib/pyspark.zip/pyspark/sql/utils.py", line 51, in deco
pyspark.sql.utils.AnalysisException: u'`test`.`test_2019_1` already exists.;'
方法1是最基本的技能,当其他方法都行不通时,方法1非常有效
2. 前往spark history server查看
刚上手时通过这种方式会比较轻松,访问spark history server(默认端口:18088)对应application日志的方式有很多种:
通过上面的tracking URL直接访问,Hadoop Yarn Web UI(默认端口:8088)查看对应applicationId的运行情况时也能直接点击tracking URL访问http://【spark web ui地址】:18088http://【spark web ui地址】:18088/history/【application的id】/1/jobs/http://【spark web ui地址】:18088/history/【application的id】/2/jobs/
第2个地址是主页,可以在这里查找根据以下关键字逐页查找脚本:
提交的pyspark脚本名application的id在提交pyspark脚本时,可以在命令行加入参数【--name 作业名】,报错时通过作业名查找

第3、4个是完整链接,不一定会有第4条,看应用设置而定。
成功访问链接之后点击Executors

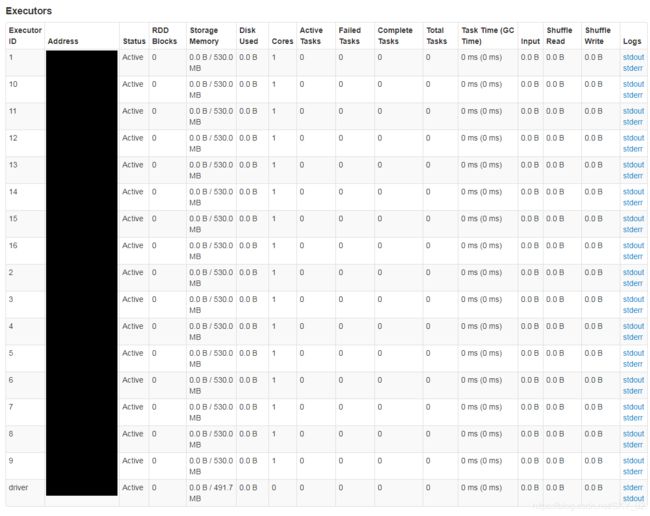
如果发现某行数据的Failed Tasks报错,可以点击该行最后的Logs查看日志,在找不到的情况下,尝试查看找Executor ID为driver那一行的Logs查看日志
五、执行脚本时遇到【XXX not found】报错的处理方式(配置hive-site.xml)
有些机器配置不完整,可能会报Database not found或Table not found等类似错误。若确认数据库和表都存在,则可能是spark找不到对应的hive元数据的关系,需要额外加上hive-site.xml。按推荐等级由高到低排序,有以下3种方式:
- 把配置xml补充完整,将
hive/conf中的hive-site.xml复制到spark/conf目录下,这个过程一些公司可能需要运维的配合。 - 将
hive/conf中的hive-site.xml复制下来,通过spark-submit命令随同python脚本提交上去。提交的命令也增加了一个--files参数:
# spark-submit --files hive-site.xml的路径 --master yarn-cluster --queue 队列名 --executor-memory 1G --executor-cores 1 --num-executors 16 pyspark脚本路径 日期参数
spark-submit --files hive-site.xml --master yarn-cluster --queue root.default --executor-memory 1G --executor-cores 1 --num-executors 16 test.py 20190601
- 自己写一个简易的
hive-site.xml,通过spark-submit命令随同python脚本提交上去。提交的方式同上。简易的hive-site.xml的写法有两种,直连数据库或连接metastore服务。安装过hive的朋友应该比较熟悉,以下只展示连接metastore服务的写法:
<configuration>
<property>
<name>hive.metastore.urisname>
<value>thrift://XXXXXX1:9083,thrift://XXXXXX2:9083value>
property>
configuration>
六、其他希望读者了解到的
- 本文讲述的内容非常初级,没有提及参数配置、优化技巧及命令含义,希望各位可以通过百度自行学习。如有纰漏,烦请指正。
- 这是一位网友写的Pyspark读取Hive数据的文章,其写文章的出发点和我的基本是一致的:http://bigdata.51cto.com/art/201703/534493.htm