概述
研究论坛搜索如何综合时间和TF/IDF权重。
自定义权重计算的效率问题
数据结构
假设有一个论坛的搜索
字段包括:
subject:标题
message:内容
dateline:发布时间
tagid:论坛id
直接通过注释一个查询语句来直观了解如何使用json来查询数据。
{
//为每个全文索引字段定义highlight(高亮)格式
"highlight": {
"fields": {
"subject": {},
"message": {}
}
},
//不返回全部数据
"_source": false,
//只返回subject字段
"fields": [
"subject"
],
//一个查询语句
"query": {
//自定义score(分数)
"function_score": {
"query": {
//带过滤器的查询需要用filtered 包裹
"filtered": {
//过滤器部分
"filter": {
"term": {
"tagid": 1
}
},
//查询语句部分(全文索引)
"query": {
//要查的部分有2个,用or连接起来(should 类似or)
"bool": {
"should": [
{
//match来按照全文索引来查
"match": {
//查标题
"subject": {
//标题关键字
"query": "手榴弹",
//权重boost会做个乘法
"boost": 5
}
}
},
//内容字段权重较低,配置基本相同
{
"match": {
"message": {
"query": "手榴弹",
"boost": 1
}
}
}
]
}
}
}
},
//额外的发布时间权重,时间越大,权重越大,也是乘法(默认)
//但是由于log在输入值巨大的情况下(时间戳)y轴增长缓慢,几乎无法影响到score,所以下面这个配置,思想是好的,结果是废的
"field_value_factor": {
"field": "dateline",
//log(1 + dateline)
"modifier": "log1p",
"factor": 0.1,
"missing": 1//没有这个字段的处理方式,返回分数1
}
}
}
}note: 你可能注意到我用了手榴弹一词,因为我们论坛中几乎不会出现这个词,所以在测试中可以方便测试词频、标题(subject),内容(message)的权重问题,而减少其他用户数据干扰
使用groovy语言来控制排序用的score字段
如果你使用比较新版本的ES,比如>=2.0,你可能需要先配置一下服务器以便支持groovy语句
_score是ES通过TF/IDF和其他自定义算法计算得到的一个分数,用来表达和搜索预期的接近程度,值越大越接近理想的结果。通过控制这个值,就可以改变搜索的排序结果。上面的boost是其中一种,通过设置boost,得到 _score = _score * boost的效果,相当于我们喜欢使用的“权重”。
而上面的field_value_factor的控制方式为:
_score = oldscore * log(1 + dateline * 0.1)其实这个语句的目的就是为了让时间大的(靠近现在)的数据排序靠前一点,比如新闻什么的,时间越近也是越好的,然而这个分数在dateline有巨大差异的情况下,只有万分之几的变化,不能满足要求,一个简单的方法就是 1 /(当前时间 - 发布时间),由于这个分数的底数是从0开始算起的,而 f(x) = 1/x 靠近1的部分,数值差异比较大,远离的部分(旧数据,趋于0)。这个公式还有个问题,就是底数可能是0,如果你有N台服务器,而服务器之间有一定的时间差,就可能遇到这个问题。
改为下面这样:
1 / (当前时间 - 发布时间 > 0 ? 当前时间 - 发布时间 : 1)
但是如果旧数据时间趋于0也会导致一个新问题就是,基于TF/IDF的分数失效了,也不是我们想要的,所以简单办法就是给这个分数 + 1
还有一个问题就是当时间差异为2秒的时候,数值已经下降了50%,这也太快了一点,通过一个因数控制一下下降速度
1 / (当前时间 - 发布时间 >= 1000 ? (当前时间 - 发布时间)/ 1000 : 1) + 1
1000秒的效果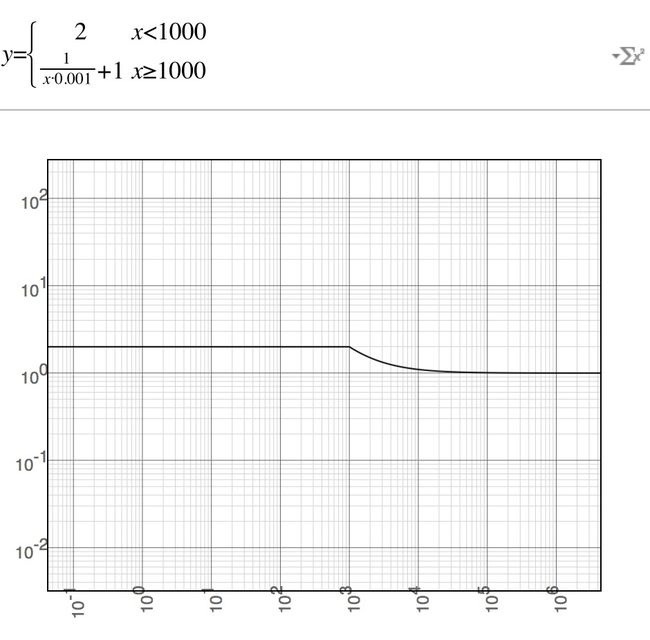
8小时的效果,基本上在10天后,分值趋近于1,也就是完全由TF/IDF决定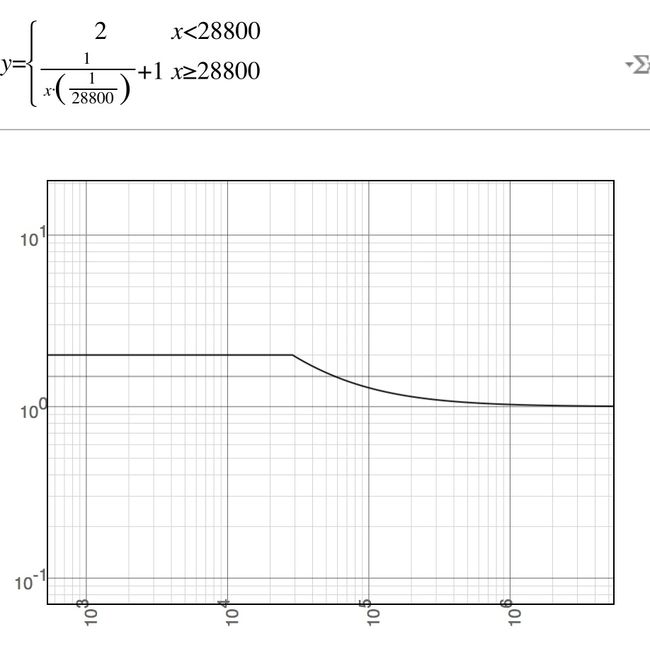
这样确保了结果在(1,2]之间变化,而分值衰减50%需要2000秒以后才会达到,最近1000秒内的数据分值相同,他们是平等的(除非新闻专题,半小时内发布的东西对于用户来说,先后的重要程度并不高,如果是论坛更是如此,在论坛中我可能会增加到4-8小时)。
{
"highlight": {
"fields": {
"subject": {},
"message": {}
}
},
"query": {
"function_score": {
"query": {
"filtered": {
"filter": {
"term": {
"tagid": 1
}
},
"query": {
"bool": {
"should": [
{
"match": {
"subject": {
"query": "手榴弹",
"boost": 1,
"operator": "or"
}
}
},
{
"match": {
"message": {
"query": "手榴弹",
"boost": 1,
"operator": "or"
}
}
}
]
}
}
}
},
//这里是差异的部分
"functions": [
{
"script_score": {
"script": "return 1 /( now - doc['dateline'].value > 1000 ? ( now - doc['dateline'].value ) / 1000 : 1);",
"params": {
"now": 1448806722
}
}
}
]
}
}
}2015年12月03更新:groovy 效率极低
在实际应用的时候,我们数据量大概是 1400 万条,约12G。
测试机器硬件配置:
Intel(R) Xeon(R) CPU E5506 @ 2.13GHz 4核
内存16G
集群设置:
- 单节点
- 分片5,备份 0 分词插件为 ik
这个查询跑下来需要3000 ms 以上,关键的问题就是groovy,这个数据不是预先计算好的,而是每次重新计算。
其实除了groovy,ES还支持多种脚本语言。
目前测试下来比较快的是expression ,内置,不需要插件,速度快,只支持数值运算,符合我们的需要。
//function 部分改为如下,注意:不需要return,这是个算数表达式。不需要分号结尾。
"functions": [
{
"script_score": {
"lang": "expression",
"script": "1 /( now - doc['dateline'].value > 259200 ? ( now - doc['dateline'].value ) / 259200 : 1)",
"params": {
"now": $time
}
}
}
]对比情况为:
groovy 3000ms 以上
expression 35 - 50 ms 间浮动
- 速度相差约 60 倍 *
官方说法是expression的速度是可以匹敌原生java语言的插件。但是表达式的各个部分,只能是数字。
参考资料:
有关script_score的官方文档
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-scripting.html#_lucene_expressions_scripts
lucene expression 官方文档
http://lucene.apache.org/core/4_9_0/expressions/index.html?org/apache/lucene/expressions/js/package-summary.html
Es权威指南第二部分,Search in Depth - script-score
https://www.elastic.co/guide/en/elasticsearch/guide/current/script-score.html