Spring Data Solr 使用
 日萌社
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
搜索引擎:Elasticsearch、Solr、Lucene
- ELK中的ES:Elasticsearch
- SolrCloud 的搭建、使用
- Solr 高亮显示
- Spring Data Solr 使用
- Solr的安装与配置
- Solr 原理、API 使用
- Lucene 原理、API使用
- Lucene 得分算法
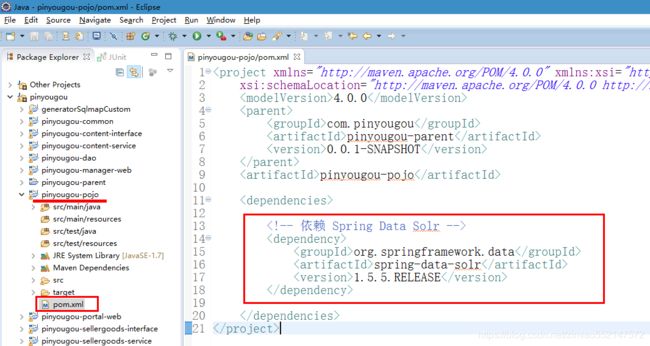
Spring Data Solr就是为了方便Solr的开发所研制的一个框架,其底层是对SolrJ(官方API)的封装。
Spring Data Solr 的Demo
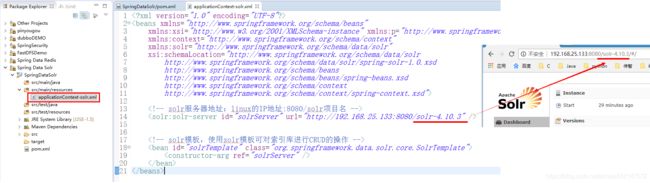
solr服务器地址 + 指定数据库存储:
1.默认使用的是 solr_home目录下的 collection1数据库:“linux的IP地址:8080/solr项目名”
2.指定使用 solr_home目录下的 哪个数据库:“linux的IP地址:8080/solr项目名/数据库名”
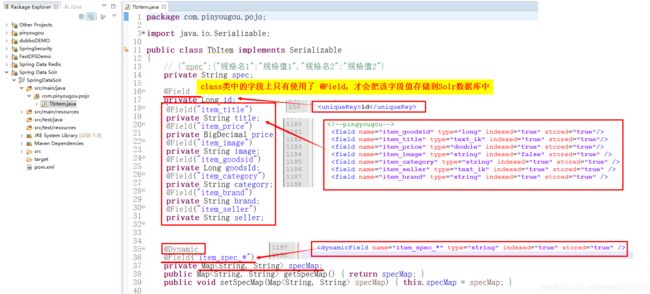
@Field注解:要把class类中的字段值存储到Solr数据库中,必须在class类中的字段上使用 @Field
1.@Field:class类中的字段名 与 schema.xml配置文件中 定义的域名称相同时,定义@Field即可。
2.@Field(“对应schema.xml配置文件中的域名称”):
当class类中的字段名 与 schema.xml配置文件中 定义的域名称不一致,
那么class类中的字段上 需要使用@Field(“对应schema.xml配置文件中的域名称”),并且必须在注解中指定域字段名称。

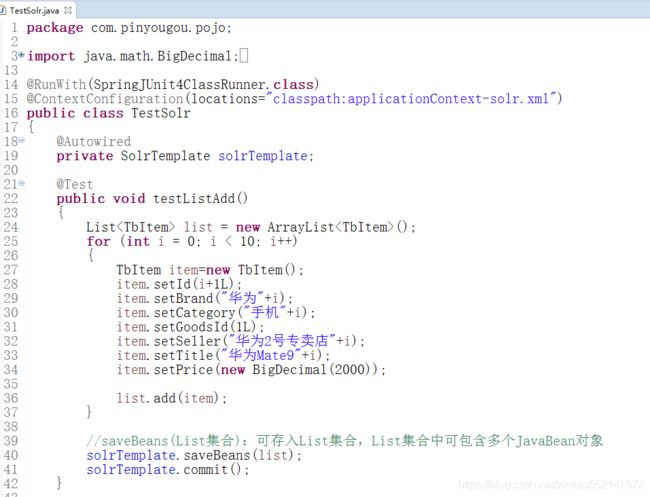
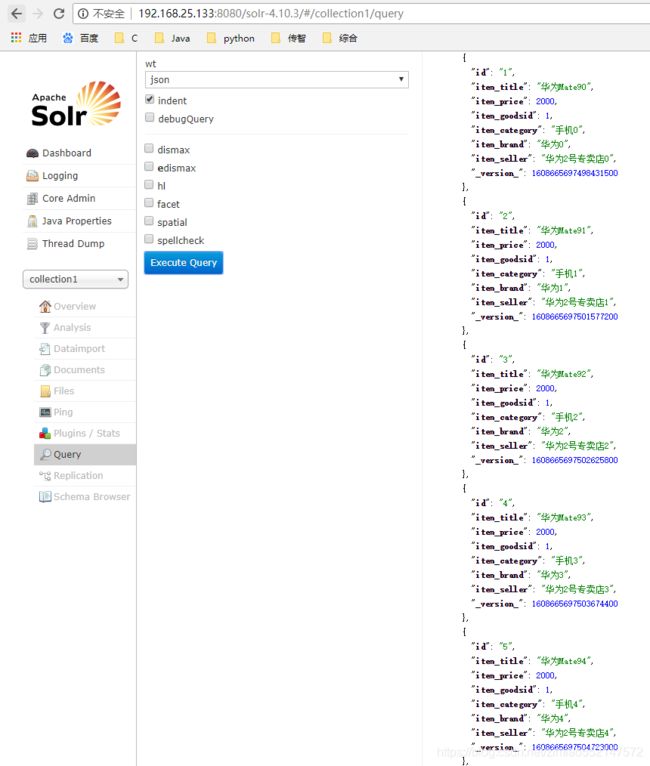
增加/修改单个对象都是使用saveBean(对象) ,同时增加/修改多个对象则都是使用saveBeans(List集合)
1.在每个数据库中conf目录下的schema.xml配置文件:solr_home\collection1\conf\schema.xml
都配置了的主键ID:id
2.增加操作:没有设置主键ID
修改操作:设置了主键ID
3.saveBean(对象):增加/修改单个对象。
4.saveBeans(List集合):同时增加/修改多个对象。
![]()
saveBean(JavaBean对象):存入一个JavaBean对象
saveBeans(List集合):可存入List集合,List集合中可包含多个JavaBean对象
根据主键查询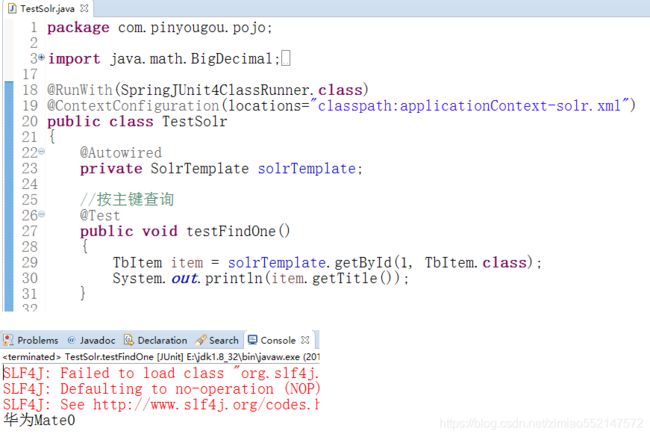
根据主键删除
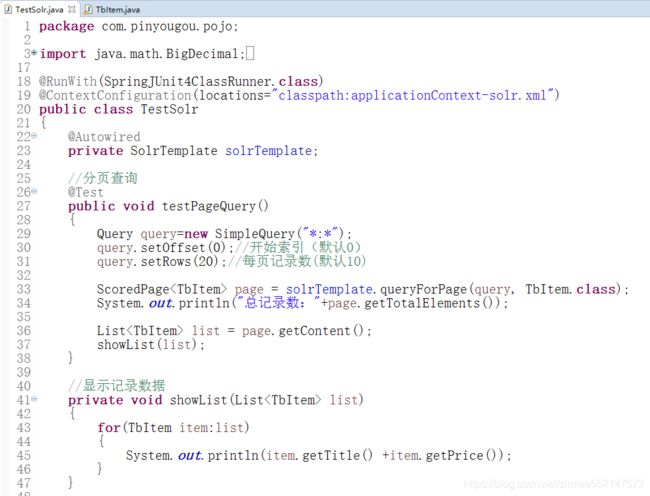
分页查询
1.创建查询对象:Query query=new SimpleQuery("*:*")
Query:接口
SimpleQuery:实现类
"*:*":表示查询的范围是所有数据
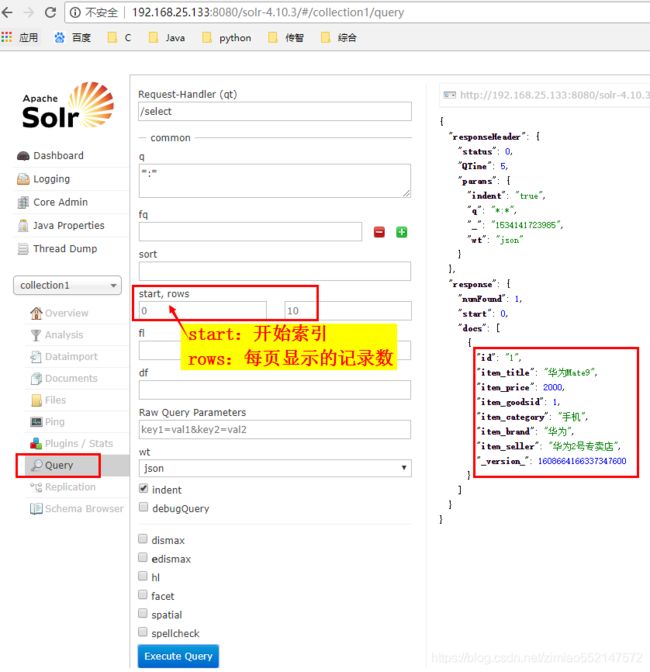
2.查询对象query.setOffset(20):开始索引(默认0)
查询对象query.setRows(20):每页显示的记录数(默认10)
3.ScoredPage对象.getTotalElements():总记录数(数据的总条数)
ScoredPage对象.getTotalpages():总页数
条件查询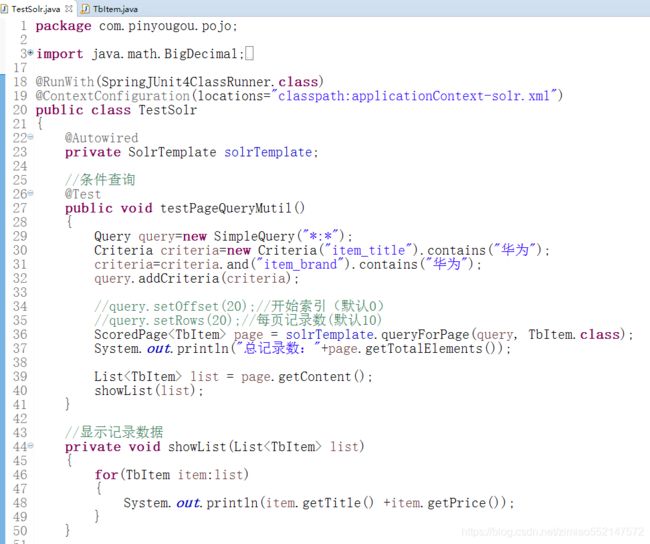
删除全部
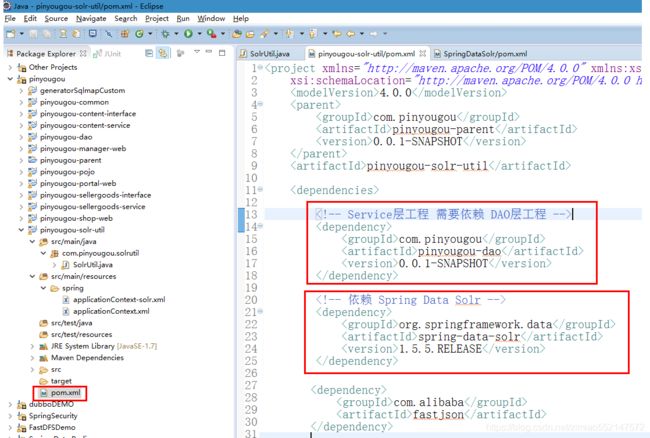
创建使用Spring Data Solr的工程pinyougou-solr-util:把MySQL数据库中的数据批量导入到Solr中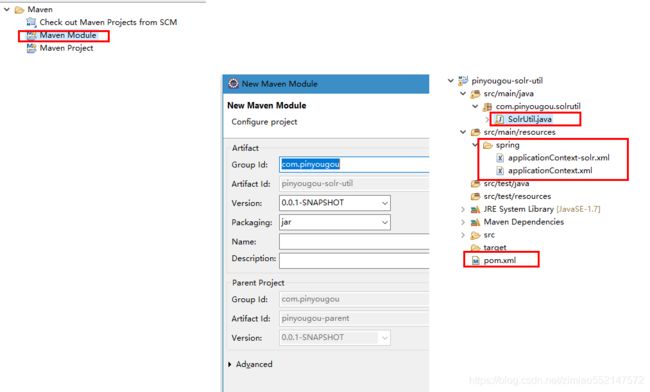
修改完pinyougou-pojo后 记得还需要 install pinyougou-pojo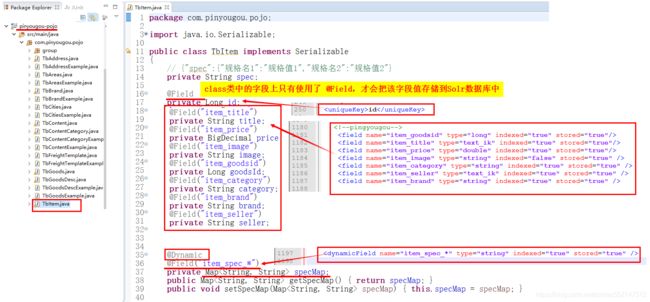




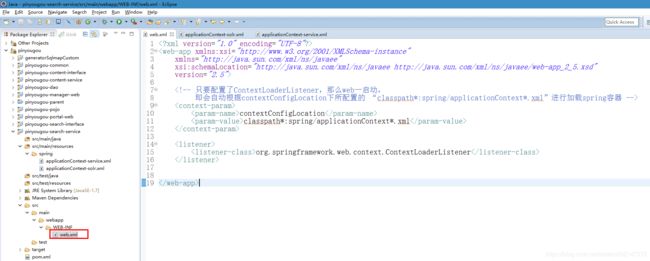
ApplicationContext context=new ClassPathXmlApplicationContext("classpath*:spring/applicationContext*.xml"):
1."classpath*":
不仅会到当前项目中的WEB-INF/classes的目录下查找文件,
还会到当前项目中所依赖的jar包中的classes的目录中查找文件;
当前项目中所依赖的jar包 实际指的就是 当前项目下“所依赖的项目中的WEB-INF/classes的目录下”查找文件,
比如当前项目是Service工程,那么当前的Service工程依赖着DAO(jar)工程的话,
DAO(jar)工程就会以jar包的方式引入进到Service工程中,那么即不仅会扫描Service工程classes目录进行查找文件,
还会扫描所依赖进来的DAO(jar)工程中的classes目录进行查找文件。
2."spring/applicationContext*.xml":
指的是spring目录下的“applicationContext”名称打头的xml文件都会被找到并加载
3."classpath*:spring/applicationContext*.xml":
指的就是既会扫描当前项目中classes目录下的“applicationContext”名称打头的xml文件,
还会扫描当前项目所依赖进来的jar工程中classes目录下的“applicationContext”名称打头的xml文件。
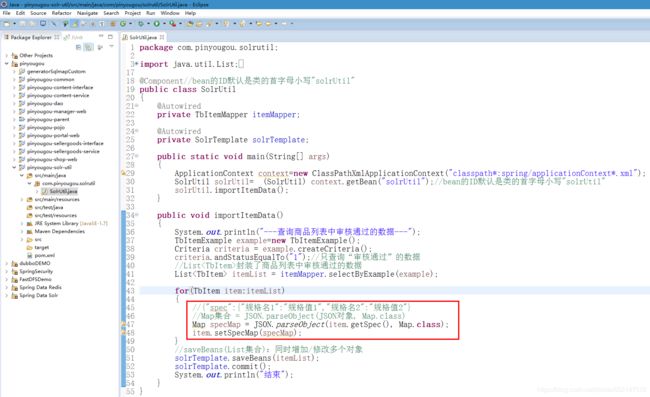
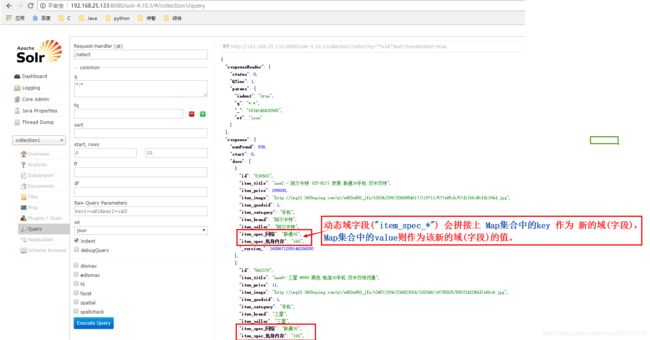
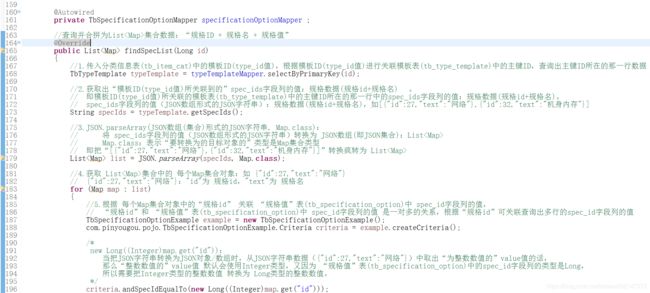
1.spec字段值:JSON对象的字符串
2.动态域(动态字段):
1.第一步:把 spec字段值(JSON对象的字符串) 转换为 Map集合:Map集合 = JSON.parseObject(JSON对象, Map.class)
2.第二步:把该Map集合 赋值给 动态域字段("item_spec_*") 对应的 Map specMap
3.第三步:动态域字段("item_spec_*") 会拼接上 Map集合中的key 作为 新的域(字段),
Map集合中的value则作为该新的域(字段)的值。
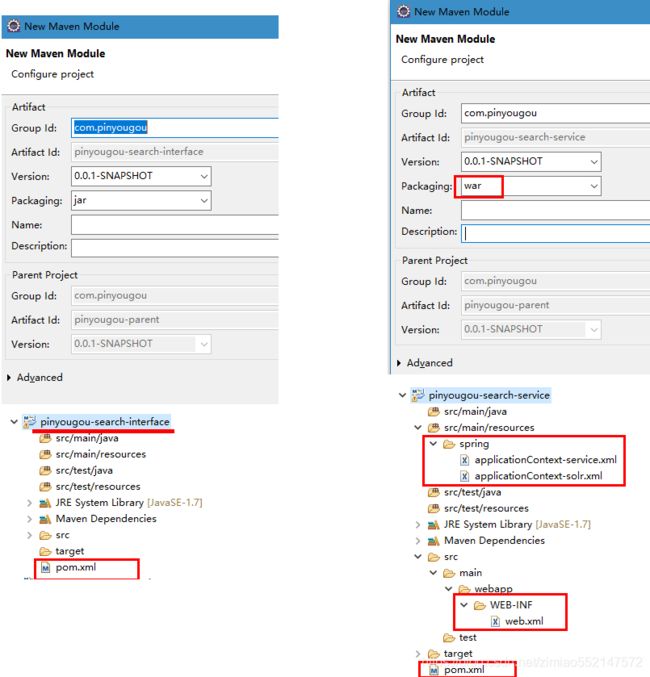
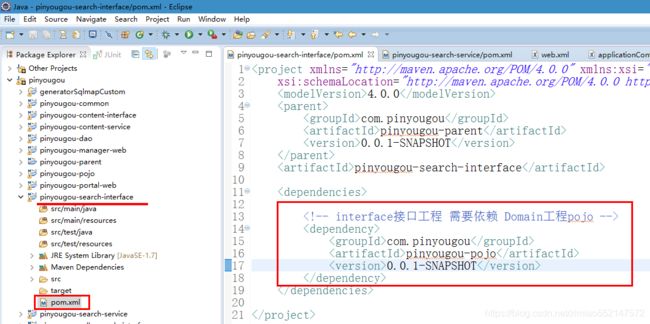
创建“搜索功能模块”工程:pinyougou-search-interface、pinyougou-search-service



classpath*:spring/applicationContext*.xml:
1."classpath*":
不仅会到当前项目中的WEB-INF/classes的目录下查找文件,
还会到当前项目中所依赖的jar包中的classes的目录中查找文件;
当前项目中所依赖的jar包 实际指的就是 当前项目下“所依赖的项目中的WEB-INF/classes的目录下”查找文件,
比如当前项目是Service工程,那么当前的Service工程依赖着DAO(jar)工程的话,
DAO(jar)工程就会以jar包的方式引入进到Service工程中,那么即不仅会扫描Service工程classes目录进行查找文件,
还会扫描所依赖进来的DAO(jar)工程中的classes目录进行查找文件。
2."spring/applicationContext*.xml":
指的是spring目录下的“applicationContext”名称打头的xml文件都会被找到并加载
3."classpath*:spring/applicationContext*.xml":
指的就是既会扫描当前项目中classes目录下的“applicationContext”名称打头的xml文件,
还会扫描当前项目所依赖进来的jar工程中classes目录下的“applicationContext”名称打头的xml文件。
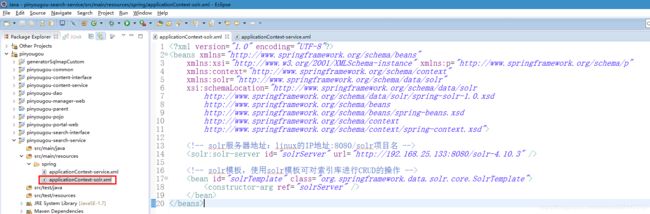

创建“搜索功能模块”web工程:pinyougou-search-web


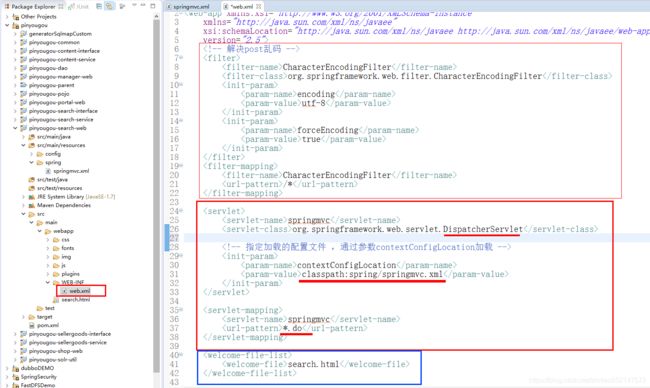
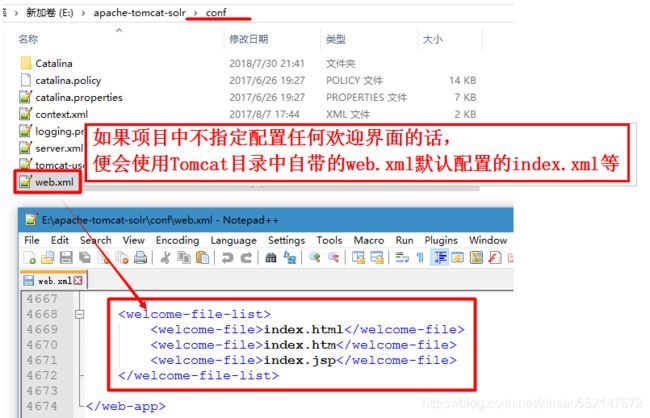
项目中配置欢迎页面的作用:
当我不输入任何请求资源或请求路径的时候,
访问的是我指定的欢迎页面,
而不是Tomcat目录中自带的web.xml默认配置的index.xml等。

1.dubbo默认的超时时间是1秒,如果调用服务开始的 1秒之后dubbo还没有响应返回的话就会报错,可以设置自定义的超时时间解决。
2.设置超时时间的两种方式:
1.第一种方式:在Controller工程中设置超时时间 @Reference(timeout=毫秒数)
2.第二种方式:在Service工程中的实现类上 设置超时时间 @Service(timeout=毫秒数)
3.如果Controller工程中既设置了@Reference(timeout=毫秒数),又在Service工程中设置了@Service(timeout=毫秒数)的话,
那么以Controller工程中设置的@Reference(timeout=毫秒数)超时时间为准。

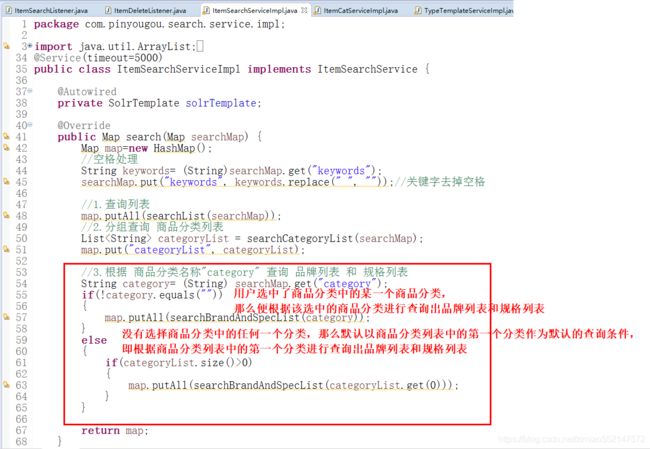
public Map search(Map searchMap)
{
Map map=new HashMap();
//空格处理
String keywords= (String)searchMap.get("keywords");
searchMap.put("keywords", keywords.replace(" ", ""));//关键字去掉空格
//1.查询列表
//Map集合对象.putAll(Map集合对象):表示把一个Map集合对象中的所有键值对拷贝到另外一个Map集合对象中
map.putAll(searchList(searchMap));
//2.分组查询 商品分类列表
List categoryList = searchCategoryList(searchMap);
map.put("categoryList", categoryList);
return map;
}

tb_item(商品SKU表):
根据category(商品分类)进行group by分组,同时在where子句中通过“复制域字段=搜索关键字”进行过滤查询


/**
* 分组查询(查询商品分类列表)
* @return
*/
private List searchCategoryList(Map searchMap)
{
List list=new ArrayList();
Query query=new SimpleQuery("*:*");
//Where子句:根据关键字查询
// where 复制域名"item_keywords" = 关键字
Criteria criteria=new Criteria("item_keywords").is(searchMap.get("keywords"));
query.addCriteria(criteria);
//Group子句:设置商品分类名的分组选项
//根据category(商品分类)进行group by分组:group by 域字段名"item_category"
GroupOptions groupOptions=new GroupOptions().addGroupByField("item_category");
query.setGroupOptions(groupOptions);
//1.此处获取“按照category(商品分类)进行分组查询后的”分组页数据
//2.GroupPage:分组页对象。
// GroupPage分组页对象中 可以包含多个不同的 GroupResult分组结果对象,
// 意思即 每个GroupResult分组结果对象 都对应一个不同的“分组查询字段”,根据多个不同的“分组查询字段”进行分组查询之后,
// 产生的多个不同的GroupResult分组结果对象 都一并封装到GroupPage分组页对象中。
GroupPage page = solrTemplate.queryForGroupPage(query, TbItem.class);
//1.GroupPage对象.getGroupResult("分组字段"):
// 根据指定的分组字段,获取出“通过该分组字段分组查询出的”结果对象。
// 可以根据不同的分组字段,获取出“通过该分组字段分组查询出的”结果对象。
GroupResult groupResult = page.getGroupResult("item_category");
//获取category(商品分类)的分组结果数据的入口页:Page> groupEntries = groupResult.getGroupEntries();
Page> groupEntries = groupResult.getGroupEntries();
//获取分组结果数据的入口集合:List> entryList = groupEntries.getContent();
List> entryList = groupEntries.getContent();
//遍历“分组结果数据集合”:获取出每行分组数据
for(GroupEntry entry:entryList)
{
//GroupEntry对象.getGroupValue():获取出每行分组数据的真正内容
list.add(entry.getGroupValue());
}
return list;
}
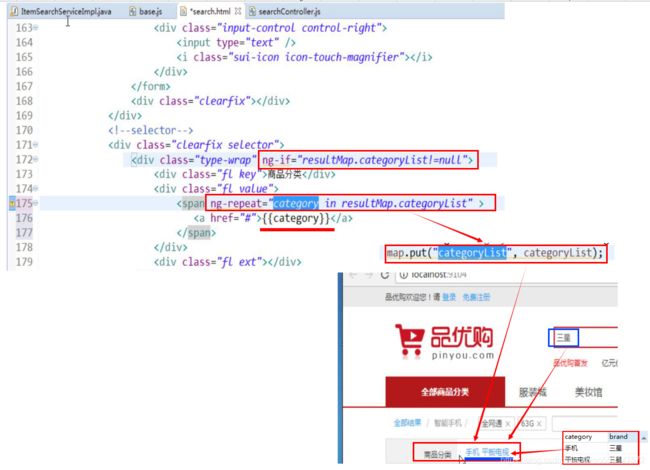


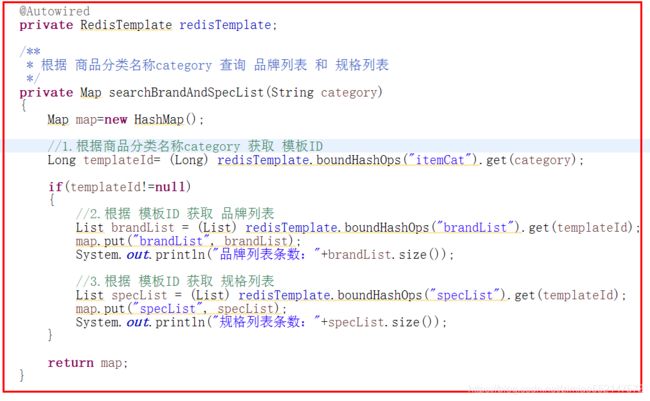
1.Hash容器中:商品分类名称作为key,商品分类对应的模板ID作为value
2.Hash容器中的key:每行商品分类信息中的name字段值(商品分类名称),即某级商品分类中的商品分类名
Hash容器中的value:每行商品分类信息中的type_id字段值(模板ID),即某级商品分类中的模板ID
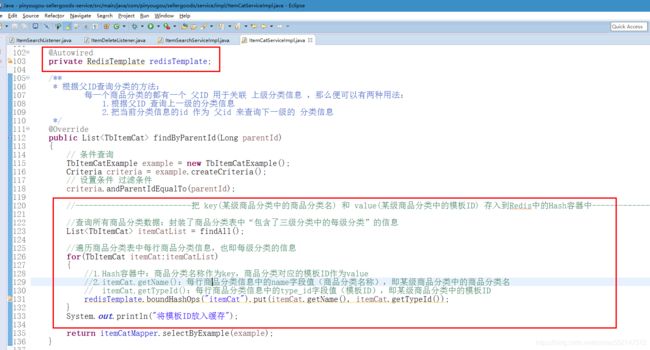
1.Hash容器名:"brandList"
Hash容器中:模板表中的主键ID作为key,模板表中的brand_ids字段值(品牌列表数据 JSON数组)作为value
2.Hash容器名:"specList"
Hash容器中:模板表中的主键ID作为key,List



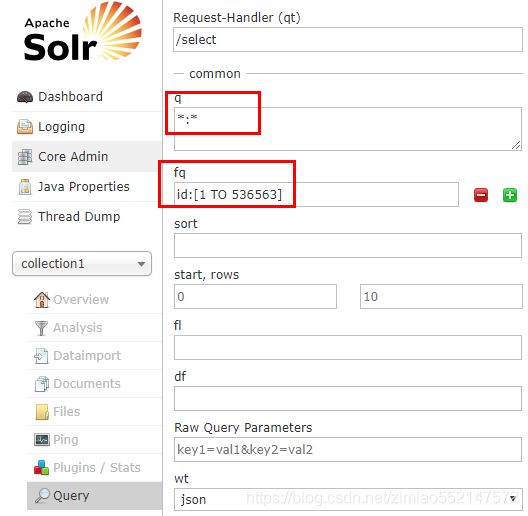
过滤查询-分类过滤、品牌过滤、规格过滤、根据分类查询品牌和规格列表
1.q:查询的关键字,首先会根据该参数先查询出数据
2.fq:过虑查询,是在“q”的基本查询数据之上再进行过滤查询
3.q 和 fq 的执行顺序:先根据“q”的关键参数查询出结果数据,然后再在“q”查询出的结果数据的基础上,
对“q”查询出的结果数据进行“fq”的过虑查询。
1.第一种用法:
1.第一步:
创建“高亮查询HighlightQuery对象”:HighlightQuery query = new SimpleHighlightQuery()
2.第二步:
构建“查询条件Criteria对象”:Criteria filterCriteria = new Criteria("solr的域字段名").is(值)//等同于“fq”
把 “查询条件Criteria对象” 传入到 “高亮查询HighlightQuery对象”中:HighlightQuery对象.addCriteria(Criteria对象);
3.第三步:
调用SolrTemplate(Solr模板对象),根据“高亮查询HighlightQuery对象”查询获取出高亮结果集:
HighlightPage page = solrTemplate.queryForHighlightPage(高亮查询HighlightQuery对象, T.class);
2.第二种用法:
1.第一步:
创建“高亮查询HighlightQuery对象”:HighlightQuery query = new SimpleHighlightQuery()
2.第二步:
构建“查询条件Criteria对象”:Criteria filterCriteria = new Criteria("solr的域字段名").is(值)//等同于“q”
把 “查询条件Criteria对象” 传入到 “高亮查询HighlightQuery对象”中:HighlightQuery对象.addCriteria(Criteria对象);
3.第三步:
创建“过滤查询FilterQuery对象”:FilterQuery filterQuery = new SimpleFilterQuery()//等同于“fq”
构建“查询条件Criteria对象”:Criteria filterCriteria = new Criteria("solr的域字段名").is(值)
把 “查询条件Criteria 对象” 传入到 “过滤查询FilterQuery对象”中:FilterQuery对象.addCriteria(Criteria对象);
把 “过滤查询FilterQuery对象” 传入到 “高亮查询HighlightQuery对象”中:HighlightQuery对象.addFilterQuery(FilterQuery对象)
4.第四步:
调用SolrTemplate(Solr模板对象),根据“高亮查询HighlightQuery对象”查询获取出高亮结果集:
HighlightPage page = solrTemplate.queryForHighlightPage(高亮查询HighlightQuery对象, T.class);
5.例子:
1.第一步:创建“高亮查询HighlightQuery对象”
代码如下:
HighlightQuery query=new SimpleHighlightQuery();//HighlightQuery 是 Query 的子接口
//1.HighlightOptions:高亮选项
//2.高亮域(高亮字段):要在"item_title"这一列上加高亮
//3.链式编程:可以添加多个高亮域(高亮字段);
// 比如:new HighlightOptions().addField("高亮域(高亮字段)").addField("高亮域(高亮字段)")
HighlightOptions highlightOptions=new HighlightOptions().addField("item_title");
highlightOptions.setSimplePrefix("");//高亮标签的前缀
highlightOptions.setSimplePostfix(""); //高亮标签的后缀
2.第二步:
构建“查询条件Criteria对象”:Criteria filterCriteria = new Criteria("solr的域字段名").is(值)//等同于“q”
把 “查询条件Criteria对象” 传入到 “高亮查询HighlightQuery对象”中:HighlightQuery对象.addCriteria(Criteria对象);
代码如下:
//1.1 搜索关键字查询:searchMap.get("keywords") 获取的是搜索框中的搜索关键字
//where子句:where item_keywords = 搜索关键字
Criteria criteria=new Criteria("item_keywords").is(searchMap.get("keywords"));
query.addCriteria(criteria);
3.第三步:
创建“过滤查询FilterQuery对象”:FilterQuery filterQuery = new SimpleFilterQuery()//等同于“fq”
构建“查询条件Criteria对象”:Criteria filterCriteria = new Criteria("solr的域字段名").is(值)
把 “查询条件Criteria 对象” 传入到 “过滤查询FilterQuery对象”中:FilterQuery对象.addCriteria(Criteria对象);
把 “过滤查询FilterQuery对象” 传入到 “高亮查询HighlightQuery对象”中:HighlightQuery对象.addFilterQuery(FilterQuery对象)
代码如下:
//1.2 按商品分类过滤
if(!"".equals(searchMap.get("category")) ) //如果用户选择了分类
{
FilterQuery filterQuery=new SimpleFilterQuery();//等同于“fq”
Criteria filterCriteria=new Criteria("item_category").is(searchMap.get("category"));
filterQuery.addCriteria(filterCriteria);
query.addFilterQuery(filterQuery);
}
4.第四步:
调用SolrTemplate(Solr模板对象),根据“高亮查询HighlightQuery对象”查询获取出高亮结果集:
HighlightPage page = solrTemplate.queryForHighlightPage(高亮查询HighlightQuery对象, T.class)
代码如下:
//高亮页对象
HighlightPage page = solrTemplate.queryForHighlightPage(query, TbItem.class);
3.第三种用法:
1.第一步:
创建“Query对象”:Query query = new SimpleQuery("*:*"); //等同于“q”
2.第二步:
Criteria criteria=new Criteria("solr的域字段名").is(值); //等同于“fq”
Query对象.addCriteria(Criteria对象);
3.第三步:
@Autowired
private SolrTemplate solrTemplate;
ScoredPage page = solrTemplate.queryForPage(Query对象, T.class);
page.getContent() //获取内容数据
4.第四种用法:
//分组查询(查询商品分类列表)
private List searchCategoryList(Map searchMap)
{
List list=new ArrayList();
Query query=new SimpleQuery("*:*");//等同于“q”
//Where子句:根据关键字查询
// where 复制域名"item_keywords" = 关键字
Criteria criteria=new Criteria("item_keywords").is(searchMap.get("keywords")); //等同于“fq”
query.addCriteria(criteria);
//Group子句:设置商品分类名的分组选项
//根据category(商品分类)进行group by分组:group by 域字段名"item_category"
GroupOptions groupOptions=new GroupOptions().addGroupByField("item_category");
query.setGroupOptions(groupOptions);
//1.此处获取“按照category(商品分类)进行分组查询后的”分组页数据
//2.GroupPage:分组页对象。
// GroupPage分组页对象中 可以包含多个不同的 GroupResult分组结果对象,
// 意思即 每个GroupResult分组结果对象 都对应一个不同的“分组查询字段”,根据多个不同的“分组查询字段”进行分组查询之后,
// 产生的多个不同的GroupResult分组结果对象 都一并封装到GroupPage分组页对象中。
GroupPage page = solrTemplate.queryForGroupPage(query, TbItem.class);
//1.GroupPage对象.getGroupResult("分组字段"):
// 根据指定的分组字段,获取出“通过该分组字段分组查询出的”结果对象。
// 可以根据不同的分组字段,获取出“通过该分组字段分组查询出的”结果对象。
GroupResult groupResult = page.getGroupResult("item_category");
//获取category(商品分类)的分组结果数据的入口页:Page> groupEntries = groupResult.getGroupEntries();
Page> groupEntries = groupResult.getGroupEntries();
//获取分组结果数据的入口集合:List> entryList = groupEntries.getContent();
List> entryList = groupEntries.getContent();
//遍历“分组结果数据集合”:获取出每行分组数据
for(GroupEntry entry:entryList)
{
//GroupEntry对象.getGroupValue():获取出每行分组数据的真正内容
list.add(entry.getGroupValue());
}
return list;
}
过滤查询-分类过滤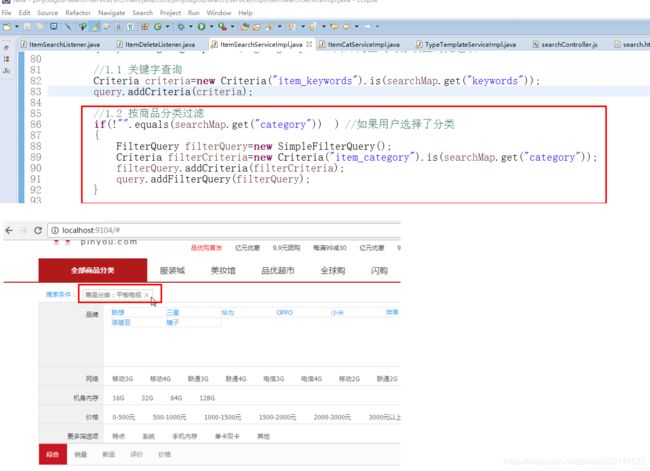
过滤查询-品牌过滤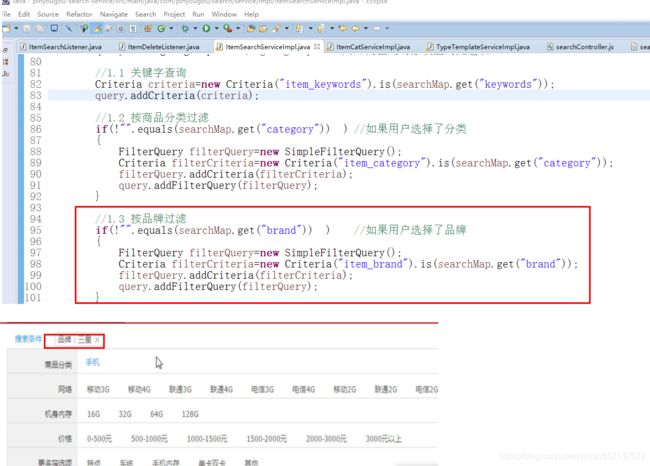
过滤查询-规格过滤
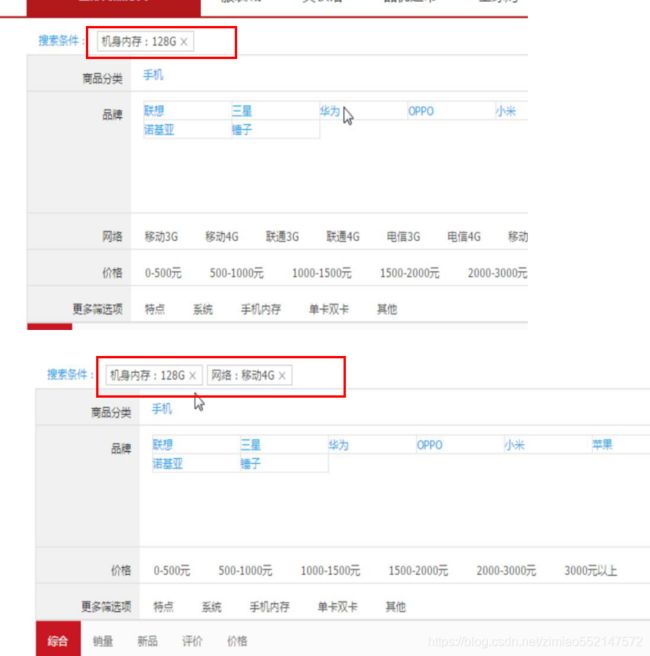
过滤查询-根据分类查询品牌和规格列表