Hadoop之自写统计json格式数据 + 排序
我们用java写统计json格式的数据。这与前面的WordCount.class统计了一个文件每个单词出现了几次性质基本一样,就是格式换成了json。
今天我们就写根据电影名,把所有的评分加起来。
1.首先我们要写MapReduce类和实现类(我写到一个类中了)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.codehaus.jackson.map.ObjectMapper;
import java.io.IOException;
public class UserRateDriver {
public static class UserRateMap extends Mapper<LongWritable, Text,Text, IntWritable> {
ObjectMapper objectMapper = new ObjectMapper();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
UserRateBean userRateBean = objectMapper.readValue(line, UserRateBean.class);
String movie = userRateBean.getMovie();
Integer rate = userRateBean.getRate();
context.write(new Text(movie),new IntWritable(rate));
//Map阶段在往Readuce传输 ,默认是按字典顺序排 例如(1,12,123,1234,2,21,213.....)
}
}
public static class UserRateReduce extends Reducer<Text,IntWritable,Text,IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable v:values) {
sum = sum + v.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
conf.set("yarn.resorcemanager.hostname","192.168.72.110");
conf.set("fs.deafutFS", "hdfs://192.168.72.110:9000/");
Job job = Job.getInstance(conf);
job.setJarByClass(UserRateDriver.class);
//设置本次job是使用map,reduce
job.setMapperClass(UserRateMap.class);
job.setReducerClass(UserRateReduce.class);
//设置本次map和reduce的输出类
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//制定本次job读取源数据时需要用到的组件:我们的源文件在hdfs的文本文件中,用TextInputFormat
job.setInputFormatClass(TextInputFormat.class);
//制定本次job输出数据需要的组件:我们要输出到hdfs文件中,用TextOutputFormat
job.setOutputFormatClass(TextOutputFormat.class);
//设置输入路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//提交任务,客户端返回
job.submit();
//核心代码:提交jar程序给yarn,客户端不退出,等待接收mapreduce的进度信息,
//打印进度信息,并等待最终运行的结果
//客户端true的含义:等着
//result:返回true则跑完了,false,出错了
boolean b = job.waitForCompletion(true);
System.exit(b ? 0: 1);
}
}
2.写完了实现类我们就可以进行打jar包 ,上一个已经告知,在这里就不多做详情了。
3.打包完上传到虚拟机上
[root@Tyler01 home]# rz
4.将json文件上传到hdfs
[root@Tyler01 home]# rz
[root@Tyler01 home]# hadoop fs -moveFromLocal rating.json /wc/
5.统计总分
[root@Tyler01 home]# hadoop jar a22.jar /wc/rating.json /wc/output
6.查看结果
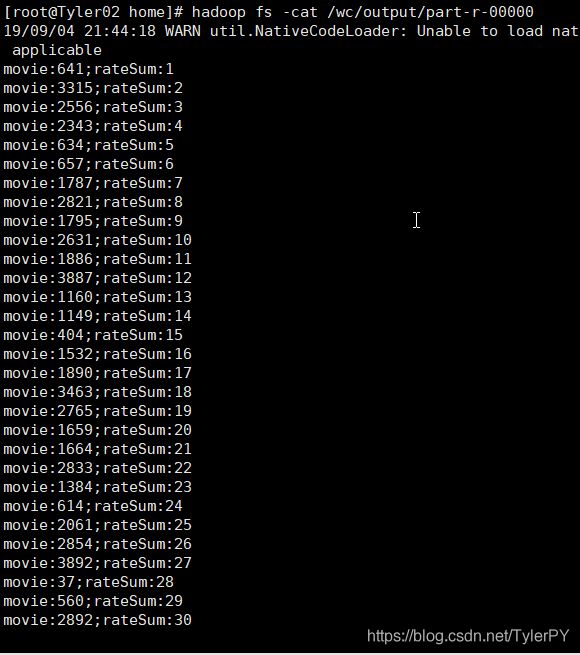
[root@Tyler01 home]# hadoop fs -cat /wc/output/part-r-00000
革命尚未完成,同志仍需努力!!!
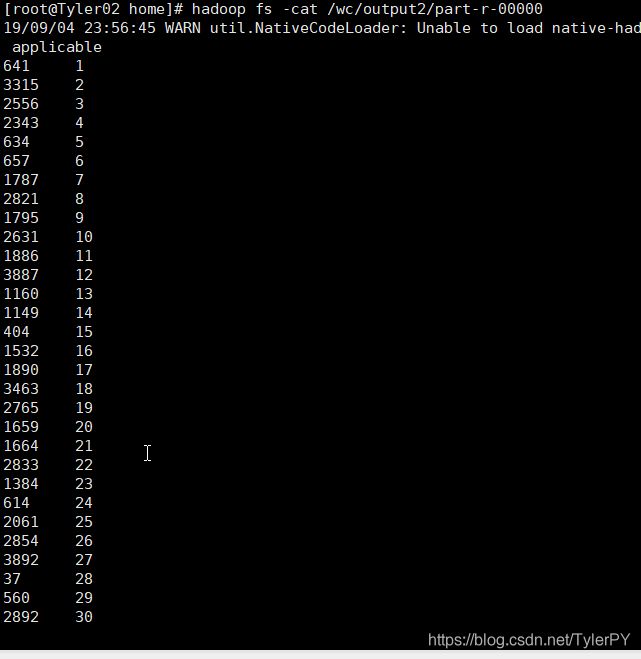
接下来我们将结果进行排序 (以总评分升序)
第一种方法:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparator;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class UserRateSumSort {
public static class UserRateSumSoutMap extends Mapper<LongWritable, Text, IntWritable,IntWritable>{
//输出: reatSum movie
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//将数据以/'\t' 拆分
String[] split = value.toString().split("\t");
//将 movie 和 rateSum 按索引取出 强转成Integer 类型
Integer movie = Integer.parseInt(split[0]);
Integer rateSum = Integer.parseInt(split[1]);
//将数据 反过来输出 reatSum movie
context.write(new IntWritable(rateSum),new IntWritable(movie));
}
}
public static class Sort extends WritableComparator{
public Sort(){
super(IntWritable.class,true);
}
public int compare(IntWritable a,IntWritable b) {
return a.compareTo(b);
}
}
public static class UserRateSumSoutReducer extends Reducer<IntWritable,IntWritable,Text,IntWritable>{
//输出:movie rateSum
@Override
protected void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//这里的values是一个迭代器 用next()方法取出 迭代器的数据。values是movie
IntWritable movie = values.iterator().next();
//输出 类型装换成string,key还是原来的key
context.write(new Text(movie.toString()),key);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(UserRateSumSort.class);
conf.set("yarn.resorcemanager.hostname","192.168.72.110");
conf.set("fs.deafutFS", "hdfs://192.168.72.110:9000/");
//指定map的key的排序类
job.setSortComparatorClass(Sort.class);
job.setMapperClass(UserRateSumSoutMap.class);
job.setReducerClass(UserRateSumSoutReducer.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.submit();
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
第二种方法:
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class UserRateSum implements WritableComparable<UserRateSum> {
private String movie;
private Integer rate;
private String timeStamp;
private String uid;
private Integer rateSum;
public String getMovie() {
return movie;
}
public void setMovie(String movie) {
this.movie = movie;
}
public Integer getRate() {
return rate;
}
public void setRate(Integer rate) {
this.rate = rate;
}
public String getTimeStamp() {
return timeStamp;
}
public void setTimeStamp(String timeStamp) {
this.timeStamp = timeStamp;
}
public String getUid() {
return uid;
}
public void setUid(String uid) {
this.uid = uid;
}
public Integer getRateSum() {
return rateSum;
}
public void setRateSum(Integer rateSum) {
this.rateSum = rateSum;
}
@Override
public String toString() {
return "movie:" + movie+ ";" + "rateSum:" + rateSum;
}
@Override
public int compareTo(UserRateSum other) {
Integer other_rateSum = other.getRateSum();
Integer my_rateSum = this.rateSum;
Integer cha = -(other_rateSum - my_rateSum); //把负号去掉就是降序排
return cha;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(this.movie);
dataOutput.writeInt(this.rateSum);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.movie = dataInput.readUTF();
this.rateSum = dataInput.readInt();
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class UserRateSumDriver {
public static class UserRateSumMap extends Mapper<LongWritable, Text,UserRateSum, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("\t");
UserRateSum userRateSum =new UserRateSum();
String movie = split[0];
//转换成int 强转
Integer rateSum = Integer.parseInt(split[1]);
userRateSum.setMovie(movie);
userRateSum.setRateSum(rateSum);
context.write(userRateSum,NullWritable.get());
}
}
public static class UserRateSumReducer extends Reducer<UserRateSum, NullWritable,UserRateSum, NullWritable>{
@Override
protected void reduce(UserRateSum key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
conf.set("yarn.resorcemanager.hostname","192.168.72.110");
conf.set("fs.deafutFS", "hdfs://192.168.72.110:9000/");
job.setJarByClass(UserRateSumDriver.class);
job.setMapperClass(UserRateSumMap.class);
job.setReducerClass(UserRateSumReducer.class);
//括号里的类型是Map阶段输出的两个类型
job.setMapOutputKeyClass(UserRateSum.class);
job.setMapOutputValueClass(NullWritable.class);
//括号里的类型是Reducer阶段输出的两个类型
job.setOutputKeyClass(UserRateSum.class);
job.setOutputValueClass(NullWritable.class);
//TextInputFormat 的 Text 不是上面的类型
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.submit();
boolean bs = job.waitForCompletion(true);
System.exit(bs ? 0: 1);
}
}