六种常见系统架构 —— 基础篇
六种常见系统架构 —— 基础篇
常见的几种系统架构设计,本文先讲前三个:
1. 单库单应用架构:最简单的,可能大家都见过
2. 内容分发架构:目前用的比较多
3. 读写分离架构:对于大并发的查询、业务
4. 微服务架构:适用于复杂的业务模式的拆解
5. 多级缓存架构:可以把缓存玩的很好
6. 分库分表架构:解决单及数据库瓶颈
一、单库单应用架构
这是最简单的一种设计模式,我们的大部分本科毕业设计、一些小的应用,基本上都是这种模式,这种模式的一般设计见下图:
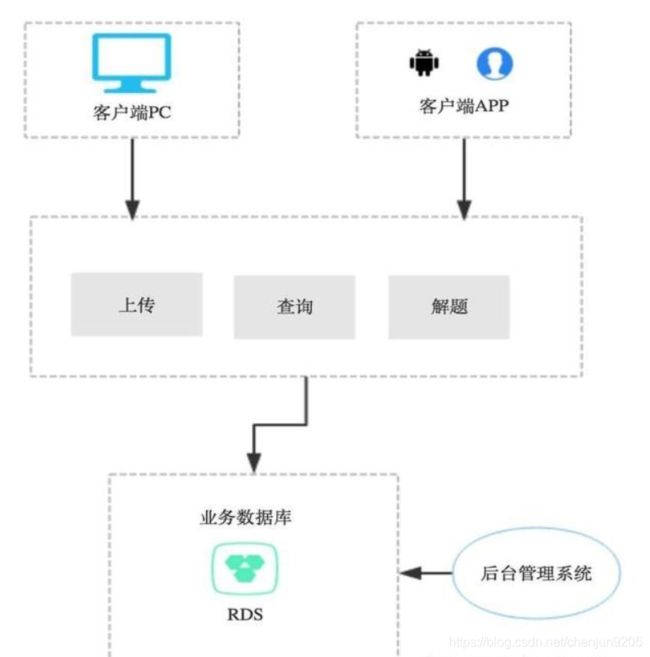 如上图所示,这种模式一般只有一个数据库,一个业务应用层,一个后台管理系统,所有的业务都是用业务层完成的,所有的数据也都是存储在一个数据库中,好一点会由数据库的同步,虽然简单,但是也并不是一无是处。
如上图所示,这种模式一般只有一个数据库,一个业务应用层,一个后台管理系统,所有的业务都是用业务层完成的,所有的数据也都是存储在一个数据库中,好一点会由数据库的同步,虽然简单,但是也并不是一无是处。
优点:结构简单、开发速度快、实现简单,可用于产品的第一版等有原型验证需求。
缺点:性能差、基本没有高可用、扩展性查,不适合用于大规模部署、应用等生产环境。
二、内容分发架构
基本上所有的大型的网站都有或多或少的采用这一种设计模式,常见的应用场景是采用CDN技术把网页、图片、CSS、JS等这些静态资源分发到离用户最近的服务器,这种模式的一般设计见下图:
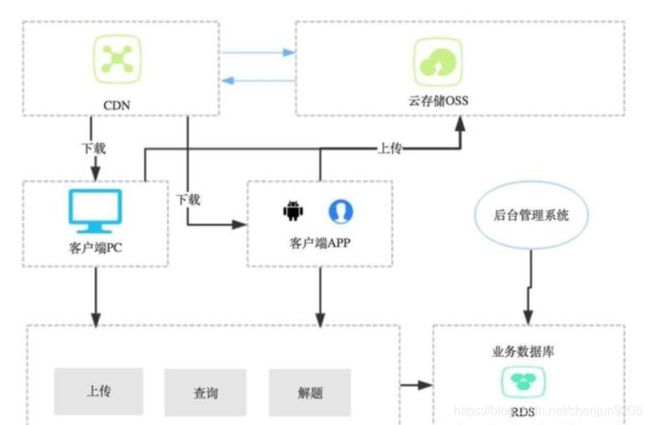
如上图所示,这种模式较单库单应用的模式多了一个CDN、一个云存储OSS(七牛、又拍等雷同)。一个经典的应用流程(以用户上传、查看图片需求为例如下:)
1、上传的时候,用户选择本地机器上的一个图片进行上传
2、程序会把这个图片上传到云存储OSS上,并返回该图片的一个URL
3、程序把这个URL字符串存储在业务数据库中,上传完成
4、查看的时候,程序从业务数据库得到该图片的URL
5、程序通过DNS查询到这个URL的图片服务器
6、智能DNS会解析这个URL,得到于用户最近的服务器(或集群)的地址A
7、然后把服务器A上的图片返回给程序
8、程序显示该图片,查看完成
由上可知,这个模式的关键是智能DNS,他能够解析出离用户最近的服务器,运行原理大致是:根据请求者的IP得到请求地点B,然后通过计算或者配置得到与B最近或通讯时间最短的服务器C,然后把C的IP地址返回给请求者。这种模式的优缺点如下:
优点:资源下载快,无需过多的开发与配置,同时也减轻了后端服务器对资源的存储压力,减少带宽的使用。
缺点:目前来说OSS、CDN的加个还是稍微优点贵的,只适用于中小规模的应用,另外由于网络传输延迟、CDN的同步策略等,会有一些一致性、更新慢方面的问题。
三、读写分离架构
这种模式主要解决单及数据库压力过大,从而导致业务缓慢甚至超时,查询影响时间变长的问题,也包括需要大量数据库服务器计算资源的查询请求,这个可以说是单库应用模式的升级版本,也是技术架构迭代演进过程中的必经之路。
这种模式的一般设计如下图:
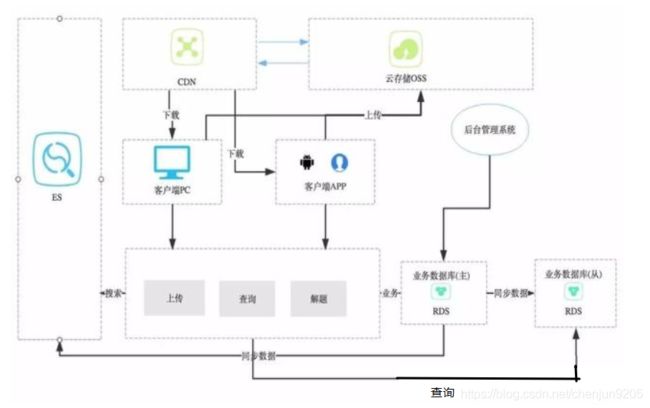
如上图所示,这种模式较单库但应用模式与内容分发模式多了几个部分,一个是业务数据库的主从分离,一个是引入ES,为什么要这样?都解决的哪些痛点,下面具体结合业务需求场景进行叙述。
场景一:全文关键词检索
我想这个需求,绝大多数应用都会有,如果使用传统的数据库技术,大部分可能会使用like这种sql语句,高级一点的是先分词,然后通分词index相关的记录。sql语句的性能问题与全表扫描机制导致了非常严重的性能问题,现在基本上很少见到。
ES较Solr配置简单、使用方便,所以这里选用了他。另外,ES支持横向扩展,理论上没有性能的瓶颈。同时,还支持各种插件、自定义分词器等,可扩展性较强。在这里,使用ES不仅可以替代数据库完成全检索功能,还可以实现诸如分页、排序、分组、分面等功能。具体的,请同学们自行学习之,那怎么使用呢?一个一般的流程是这样的:
1、服务端把一条业务数据落库
2、服务器异步把该条数据发送到ES
3、ES把该条记录按照规则、配置放入自己的索引库
4、客户端查询的时候,由服务端把这个请求发送到ES,得到数据后,根据需求拼装、组合数据,返回给客户端
实际中怎么用,还请同学们根据实际情况做组合、取舍
场景二:大量的普通查询
这个场景是指我们的业务中的大部分辅助性的查询,如:取钱的时候先查询一下余额,根据用户的ID查询用户的记录,取得该用户最新的一条取钱记录等,我们肯定是要天天用到的,而且用的还非常多。同时呢,我们的写入请求也是非常多的,导致大量的写入、查询操作压向同一数据库,然后,数据库挂了,系统挂了,领导生气了,被开除了,还不起房贷了,露宿街头了,老婆跟别人跑了……
不敢想,所以要求我们必须分散数据库的压力,一个业界较成熟的方案就是数据库的读写分离,写的时候入主库,读的时候读分库。这样就把压力分散到不同的数据库了,如果一个读库性能不行,扛不住的话,可以一主多从,横向扩展,可谓是一剂良药啊!那么怎么使用呢?一个一般的流程是这样的:
1、服务端把一条数据落库
2、数据库同步或异步或半同步把这条数据复制到从库
3、服务端读取数据的时候直接去从库读相应的数据
比较简单吧,一些聪明的、爱思考的、上进的同学可能发现问题了,也包括上面介绍的场景一,就是延迟问题,如:数据还没到从库,我就马上读,那么是读不到的,会发生问题的。对于这个问题,各家公司解决的思路也是不一样的,方法不尽相同,一个普遍的解决方案是:读不到就读主库,当然这么说也是有前提条件的,但具体的方案就不在这里一一展开了,我可能会在接下来的分享中详解各种方案。
另外,关于数据库复制模式,还请同学们自行学习,太多了,这里说不清,该总结一下这种模式的优缺点了,如下:
优点:减少数据库的压力,理论上提供无限高的读性能,简介提高业务(写)的性能,专用的查询、索引、全文(分词)解决方案。
缺点:数据延迟,数据一致性的保证。
六种常见系统架构 —— 进阶篇
本文章源自公众号:javabaiwen。