今天看了一遍不错的文章,关于Java访问Hive的,正好要用到这一块,分享到此以便更多的人可以学习和应用
非常感谢博主的总结和分享
博文链接: https://www.jianshu.com/p/4ef28607fc04
Hive内置服务与HiveServer2应用
内置服务介绍
我们执行hive --service help查看内置的服务帮助,图中的Service List右侧罗列了很多Hive支持的服务列表,种类很多。

下面介绍最有用的一些服务:
(1)cli
cli是Command Line Interface 的缩写,是Hive的命令行界面,用的比较多,是默认服务,直接可以在命令行里使用。
(2)hiveserver
这个可以让Hive以提供Thrift服务的服务器形式来运行,可以允许许多个不同语言编写的客户端进行通信,使用需要启动HiveServer服务以和客户端联系,我们可以通过设置HIVE_PORT环境变量来设置服务器所监听的端口,在默认情况下,端口号为10000。
我们可以使用如下的指令启动该服务:hive --service hiveserver -p 10002,其中-p参数也是用来指定监听端口的。
(3)hwi
其实就是hive web interface的缩写它是hive的web借口,是hive cli的一个web替代方案。
(4)jar
与hadoop jar等价的Hive接口,这是运行类路径中同时包含Hadoop 和Hive类的Java应用程序的简便方式。
(5)metastore
在默认的情况下,metastore和hive服务运行在同一个进程中,使用这个服务,可以让metastore作为一个单独的进程运行,我们可以通过METASTOE——PORT来指定监听的端口号。
Hive的三种启动方式
hive shell模式
bin/hive 或者 bin/hive –-service cli
hive web界面启动模式
bin/hive –-service hwi &, & 表示后台运行。我们后台启动hwi服务,然后输入jps查看进程发现多了一个RunJar,表明我们的hive hwi启动成功。
用于通过浏览器来访问hive,感觉没多大用途,浏览器访问地址是:http://huatec01:9999/hwi/
启动示意图:
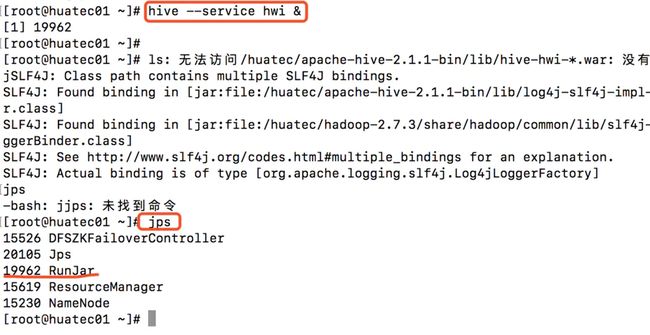
浏览器访问:

hive远程服务 (端口号10000) 启动方式
bin/hive --service hiveserver2 &
用java,python等程序实现通过jdbc等驱动的访问hive就用这种起动方式了,这个是程序员最需要的方式了。

HiveServer与HiveServer2
HiveServer2介绍
HiveServer与HiveServer2,两者都允许远程客户端使用多种编程语言,通过HiveServer或者HiveServer2,客户端可以在不启动CLI的情况下对Hive中的数据进行操作,连这个和都允许远程客户端使用多种编程语言如java,python等向hive提交请求,取回结果。
官方说明:
HiveServer is scheduled to be removed from Hive releases starting Hive 0.15. See HIVE-6977. Please switch over to HiveServer2.
从hive0.15起就不再支持hiveserver了(我的hive版本为2.1.1),但是在这里我们还是要说一下hiveserver,其实在前面的Server List中就不包含hiveserver。
我们也可以尝试执行bin/hive –-service hiveserver,会输出日志提示Service hiveserver not found。
HiveServer或者HiveServer2都是基于Thrift的,但HiveSever有时被称为Thrift server,而HiveServer2却不会。既然已经存在HiveServer,为什么还需要HiveServer2呢?
这是因为HiveServer不能处理多于一个客户端的并发请求,这是由于HiveServer使用的Thrift接口所导致的限制,不能通过修改HiveServer的代码修正。因此在Hive-0.11.0版本中重写了HiveServer代码得到了HiveServer2,进而解决了该问题。HiveServer2支持多客户端的并发和认证,为开放API客户端如JDBC、ODBC提供更好的支持。
HiveServer与HiveServer2的区别
Hiveserver和hiveserver2的JDBC区别:
HiveServer version Connection URL Driver Class
HiveServer2 jdbc:hive2://: org.apache.hive.jdbc.HiveDriver
HiveServer jdbc:hive://: org.apache.hadoop.hive.jdbc.HiveDriver
HiveServer2的配置
Hiveserver2允许在配置文件hive-site.xml中进行配置管理,具体的参数为:
hive.server2.thrift.min.worker.threads– 最小工作线程数,默认为5。
hive.server2.thrift.max.worker.threads – 最小工作线程数,默认为500。
hive.server2.thrift.port– TCP 的监听端口,默认为10000。
hive.server2.thrift.bind.host– TCP绑定的主机,默认为localhost
我们可以在hive-site.xml文件中搜索“hive.server2.thrift.min.worker.threads”属性(hive-site.xml文件配置属性达到5358行,太长了,建议搜索),然后进行编辑,示例如下:

从Hive-0.13.0开始,HiveServer2支持通过HTTP传输消息,该特性当客户端和服务器之间存在代理中介时特别有用。与HTTP传输相关的参数如下:
hive.server2.transport.mode – 默认值为binary(TCP),可选值HTTP。
hive.server2.thrift.http.port– HTTP的监听端口,默认值为10001。
hive.server2.thrift.http.path – 服务的端点名称,默认为 cliservice。
hive.server2.thrift.http.min.worker.threads– 服务池中的最小工作线程,默认为5。
hive.server2.thrift.http.max.worker.threads– 服务池中的最小工作线程,默认为500。
我们同理可以进行搜索,然后进行配置。
启动HiveServer2
启动Hiveserver2有两种方式,一种是上面已经介绍过的hive --service hiveserver2,另一种更为简洁,为hiveserver2。
我们采用第二种方式启动hiveserver2,如下图所示:

启动后hiveserver2会在前台运行,我们开启一个新的SSH链接,使用jps查看会发现多出一个RunJar进程,它代表的就是HiveServer2服务。
使用hive--service hiveserver2 –H或hive--service hiveserver2 –help查看帮助信息。
默认情况下,HiveServer2以提交查询的用户执行查询(true),如果hive.server2.enable.doAs设置为false,查询将以运行hiveserver2进程的用户运行。为了防止非加密模式下的内存泄露,可以通过设置下面的参数为true禁用文件系统的缓存
fs.hdfs.impl.disable.cache – 禁用HDFS文件系统缓存,默认值为false。
fs.file.impl.disable.cache – 禁用本地文件系统缓存,默认值为false。
浏览器查看http://huatec01:10002,如下图所示:
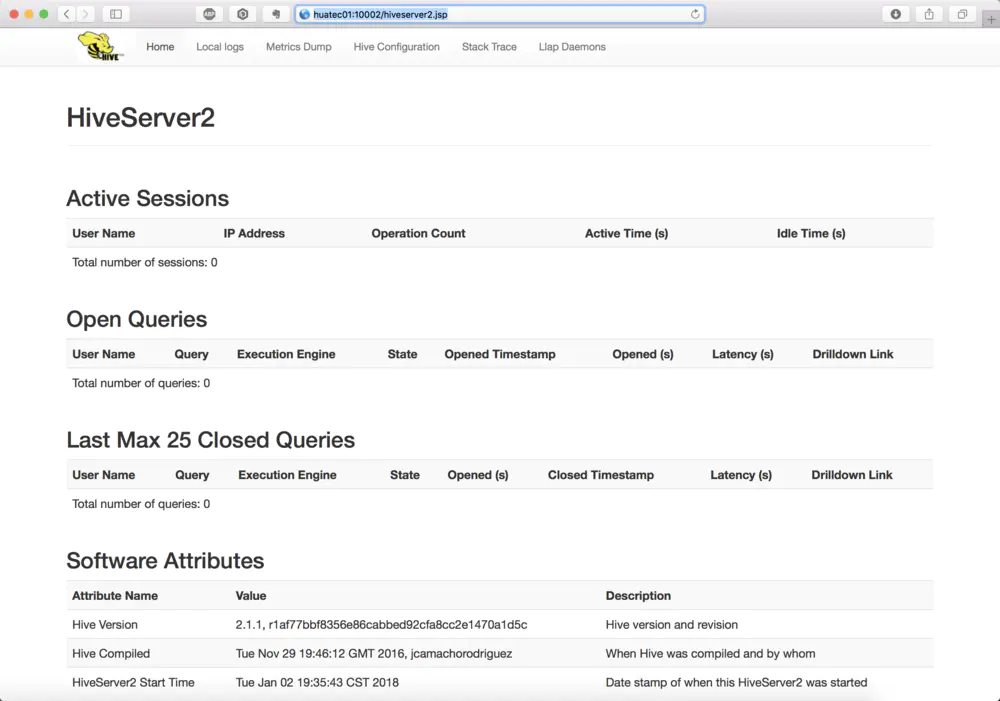
配置和使用HiveServer2
配置坚挺端口和路径
hive.server2.thrift.port
10000
Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'binary'.
hive.server2.thrift.bind.host
huatec01
Bind host on which to run the HiveServer2 Thrift service.
第一个属性默认即可,第二个将主机名改为我们当前安装hive的节点。
设置impersonation
这样hive server会以提交用户的身份去执行语句,如果设置为false,则会以起hive server daemon的admin user来执行语句。
hive.server2.enable.doAs
true
Setting this property to true will have HiveServer2 execute
Hive operations as the user making the calls to it.
我们将值改为true。
hiveserver2节点配置
Hiveserver2已经不再需要hive.metastore.local这个配置项了,我们配置hive.metastore.uris,如果该属性值为空,则表示是metastore在本地,否则就是远程。
hive.metastore.uris
Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.
默认留空,也就是metastore在本地,使用默认即可。
如果想要配置为远程的话,参考如下:
hive.metastore.uris
thrift://xxx.xxx.xxx.xxx:9083
zookeeper配置
hive.support.concurrency
true
Whether Hive supports concurrency control or not.
A ZooKeeper instance must be up and running when using zookeeper Hive lock manager
hive.zookeeper.quorum
huatec03:2181,huatec04:2181,huatec05:2181
List of ZooKeeper servers to talk to. This is needed for:
1. Read/write locks - when hive.lock.manager is set to
org.apache.hadoop.hive.ql.lockmgr.zookeeper.ZooKeeperHiveLockManager,
2. When HiveServer2 supports service discovery via Zookeeper.
3. For delegation token storage if zookeeper store is used, if
hive.cluster.delegation.token.store.zookeeper.connectString is not set
4. LLAP daemon registry service
属性1设置支持并发,属性2设置Zookeeper集群。
注意:没有配置hive.zookeeper.quorum会导致无法并发执行hive ql请求和导致数据异常。
hiveserver2的Web UI配置
Hive 2.0 以后才支持Web UI的,在以前的版本中并不支持。
hive.server2.webui.host
0.0.0.0
The host address the HiveServer2 WebUI will listen on
hive.server2.webui.port
10002
The port the HiveServer2 WebUI will listen on. This can beset to 0 or a negative integer to disable the web UI
默认即可,我们通过浏览器访问:http://huatec01:10002即可访问hiveserver2,这个前面已经试过了。
启动服务
启动metastore
bin/hive --service metastore &
启动hiveserver2
bin/hive --service hiveserver2 &
WebUI:http://huatec01:10002
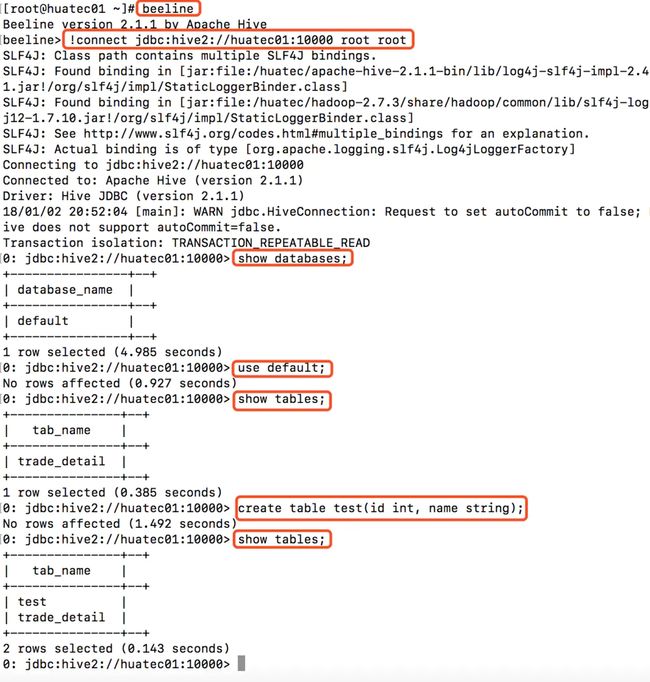
使用beeline控制台控制hiveserver2
首先我们必须启动metastore和hiveserver2
然后启动beeline
bin/beeline
尝试连接metastore:
!connect jdbc:hive2://huatec01:10000 root root
如下图表明连接成功!

beeline错误1
beeline连接hiveserver2失败,报错如下:
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: master is not allowed to impersonate hive (state=,code=0)
解决方法:
- 关闭hadoop集群
- 修改core-site.xml文件,增加如下内容:
hadoop.proxyuser.hadoop.groups
root
Allow the superuser oozie to impersonate any members of the group group1 and group2
hadoop.proxyuser.hadoop.hosts
huatec01,127.0.0.1,localhost
The superuser can connect only from host1 and host2 to impersonate a user
注意所有节点的core-site.xml都修改。
- 重启hadoop集群
- 启动metastore和hiveserver2,重新连接hiveserver2。
beeline错误2
beeline连接hiveserver2成功,但是执行sql语句报错,错误如下:
0: jdbc:hive2://huatec01:10000> show databases;
Error: java.io.IOException: java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI: ${system:user.name%7D (state=,code=0)
解决方法:
- 修改hive-site.xml中的
hive.exec.local.scratchdir属性值。将${system:user.name}改为${user.name},如下所示:
hive.exec.local.scratchdir
/huatec/apache-hive-2.1.1-bin/tmp/${user.name}
Local scratch space for Hive jobs
重新使用beeline连接hiveserver2,执行sql语句,如下图所示:
Java编程操作MetaStore
用java,python等程序实现通过jdbc等驱动的访问hive,这需要我们启动hiveserver2。如果我们能够使用beeline控制hiveserver2,那么我们毫无疑问是可以通过Java代码来访问hive了。
如果beeline控制hiveserver2出现错误,也无法执行sql,那么请先解决这方面的错误,然后再进行代码编程。
准备工作
新建maven java app项目,然后添加Hive依赖,我们编写junitc俄式代码,所以也添加junit依赖,如下所示:
junit
junit
4.12
org.apache.hive
hive-jdbc
2.1.1
编写测试类
完整的类代码如下:
package com.huatec.hive;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.sql.*;
/**
* Created by zhusheng on 2018/1/2.
*/
public class HiveJDBC {
private static String driverName = "org.apache.hive.jdbc.HiveDriver";
private static String url = "jdbc:hive2://huatec01:10000/hive_jdbc_test";
private static String user = "root";
private static String password = "root";
private static Connection conn = null;
private static Statement stmt = null;
private static ResultSet rs = null;
// 加载驱动、创建连接
@Before
public void init() throws Exception {
Class.forName(driverName);
conn = DriverManager.getConnection(url,user,password);
stmt = conn.createStatement();
}
// 创建数据库
@Test
public void createDatabase() throws Exception {
String sql = "create database hive_jdbc_test";
System.out.println("Running: " + sql);
stmt.execute(sql);
}
// 查询所有数据库
@Test
public void showDatabases() throws Exception {
String sql = "show databases";
System.out.println("Running: " + sql);
rs = stmt.executeQuery(sql);
while (rs.next()) {
System.out.println(rs.getString(1));
}
}
// 创建表
@Test
public void createTable() throws Exception {
String sql = "create table emp(\n" +
"empno int,\n" +
"ename string,\n" +
"job string,\n" +
"mgr int,\n" +
"hiredate string,\n" +
"sal double,\n" +
"comm double,\n" +
"deptno int\n" +
")\n" +
"row format delimited fields terminated by '\\t'";
System.out.println("Running: " + sql);
stmt.execute(sql);
}
// 查询所有表
@Test
public void showTables() throws Exception {
String sql = "show tables";
System.out.println("Running: " + sql);
rs = stmt.executeQuery(sql);
while (rs.next()) {
System.out.println(rs.getString(1));
}
}
// 查看表结构
@Test
public void descTable() throws Exception {
String sql = "desc emp";
System.out.println("Running: " + sql);
rs = stmt.executeQuery(sql);
while (rs.next()) {
System.out.println(rs.getString(1) + "\t" + rs.getString(2));
}
}
// 加载数据
@Test
public void loadData() throws Exception {
String filePath = "/home/hadoop/data/emp.txt";
String sql = "load data local inpath '" + filePath + "' overwrite into table emp";
System.out.println("Running: " + sql);
stmt.execute(sql);
}
// 查询数据
@Test
public void selectData() throws Exception {
String sql = "select * from emp";
System.out.println("Running: " + sql);
rs = stmt.executeQuery(sql);
System.out.println("员工编号" + "\t" + "员工姓名" + "\t" + "工作岗位");
while (rs.next()) {
System.out.println(rs.getString("empno") + "\t\t" + rs.getString("ename") + "\t\t" + rs.getString("job"));
}
}
// 统计查询(会运行mapreduce作业)
@Test
public void countData() throws Exception {
String sql = "select count(1) from emp";
System.out.println("Running: " + sql);
rs = stmt.executeQuery(sql);
while (rs.next()) {
System.out.println(rs.getInt(1) );
}
}
// 删除数据库
@Test
public void dropDatabase() throws Exception {
String sql = "drop database if exists hive_jdbc_test";
System.out.println("Running: " + sql);
stmt.execute(sql);
}
// 删除数据库表
@Test
public void deopTable() throws Exception {
String sql = "drop table if exists emp";
System.out.println("Running: " + sql);
stmt.execute(sql);
}
// 释放资源
@After
public void destory() throws Exception {
if ( rs != null) {
rs.close();
}
if (stmt != null) {
stmt.close();
}
if (conn != null) {
conn.close();
}
}
}
需要注意的是,因为hive默认只有一个数据库default,从前面的beeline访问hiveserver2的时候我们也可以看出。如果我们需要对默认数据库进行操作的话,我们的数据库连接为:
private static String url = "jdbc:hive2://huatec01:10000/default";
这里我写了一个创建数据库的测试方法,其它的Sql操作都是基于该数据库的,所以我修改我的数据库连接为我新建的数据库。
private static String url = "jdbc:hive2://huatec01:10000/hive_jdbc_test";
测试函数比较多,我本地进行了测试都是可以成功的,我选取其中的createTable测试函数为例,截图如下:

作者:Jusen
链接:https://www.jianshu.com/p/4ef28607fc04
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。