车牌定位(四)
python手动实现车牌定位(四)
- 一. 获取所有灰度图片
- 二. 获取所有车牌区域
- 三. 分割字符串
- 四. 结果分析
- 五. CNN识别字符串
写在前面的话: 这篇文章是将之前的所有整合到一起,对一组图片进行系统的比较分析,判断其处理过程及结果的可行性与准确性。
一. 获取所有灰度图片
def get_imlist(path):
path_list = [os.path.join(path,f) for f in os.listdir(path) if f.endswith('.bmp')]
return path_list
path_list = get_imlist( 'G:/photo/bmp_image/')
print(path_list)
将代码整合到一起
def get_location(path):
im = Image.open(path)
im_L = im.convert('L')
im_rgb, width, height = get_rgb(im)
print(width, height)
# 转换为数据
im_array = np.array(im)
im_L_array = np.array(im_L)
im_rgb = np.array(im_rgb).reshape(height,width,3)
# print(im_rgb.shape)
hsv_list = []
for i in range(height):
for j in range(width):
h1,s1,v1 = rgb2hsv(im_rgb[i,j,0], im_rgb[i,j,1], im_rgb[i,j,2])
hsv_list.append((h1,s1,v1))
hsv_list = np.array(hsv_list).reshape(height,width,3)
# print(len(hsv_list))
for i in range(height):
for j in range(width):
if(hsv_list[i,j,0]<230 and hsv_list[i,j,0]>180 and hsv_list[i,j,1]>0.6 and hsv_list[i,j,2]<250):
im_L_array[i,j] = 255
else:
im_L_array[i,j] = 0
im_L_array = im_L_array.reshape(width,height)
# print(im_L_array)
im_L_array = im_L_array.T
huiimg = Image.fromarray(im_L_array)
huiimg.save('./huiimg/' + path.split("/")[-1].split('.')[0] + '.png')
if __name__ == "__main__" :
for p in path_list:
get_location(p)
二. 获取所有车牌区域
def get_imlist(path):
path_list = [os.path.join(path,f) for f in os.listdir(path) if f.endswith('.png')]
return path_list
path_list = get_imlist( 'E:/jupyter/vision/identify/huiimg/')
print(path_list)
将第二部分整合到一起的代码
def get_region(path, new_path, i):
im = Image.open(path).convert('L')
im_array = np.array(im)
width, height = im_array.shape
imb_array = erosion(im_array, width, height)
imb_array2 = dilation(imb_array, width, height)
imb = Image.fromarray(imb_array2)
VL, VH, HL, HH = get_location(imb_array2, width, height, 10)
# print(VL, VH, HL, HH)
img = Image.open(bmp_path + files[i])
box=( VL,HL,VH,HH )
region = img.crop(box)
hui_region = imb2.crop(box)
# plt.imshow(region)
region.save(new_path1 + path.split("/")[-1])
hui_region.save(new_path2 + path.split("/")[-1])
if __name__ == "__main__":
bmp_path = 'G:/photo/bmp_image/'
files = os.listdir(bmp_path)
new_path1 = 'E:/jupyter/vision/identify/region/'
new_path2 = 'E:/jupyter/vision/identify/region2/'
for n in range(len(path_list)):
get_region(path_list[n], new_path, n)
放出结果图



注意: 在此处我将 get_location() 函数中的阈值设为10,在这里我认为阈值取3就可以,我只是为了多取一些边框,便于处理。对进行开运算后的图片进行截取保存。
三. 分割字符串
这个部分改了很多,因为每幅图像信息不同,需要不同的阈值去分割开来。在 vertical() 函数中
def vertical(s):
threads = min(s) + 2
for i in range(len(s)):
if s[i]>threads:
s[i] = 1
else:
s[i] = 0
return s
即使改成这样,也并不能适用于所有的图片,仍然得根据图片信息更改,所以还需要在这个方面进行改进,取到适用于所有图像的参数,总是有各种奇葩的数学公式能导出来吧,我也没有去尝试,在此略过了。
在 get_cared() 函数中将第一个字符加进去,否则汉字总是没有截出来。
def get_cared(s):
cared = []
x_li = []
y_li = []
x = y = 0
for i in range(len(s)-1):
if (s[i] == 1)and(s[i-1]==0):
x = i
x_li.append(x)
if (s[i] == 1)and(s[i+1]==0):
y = i
y_li.append(y)
if(x and x<y):
cared.append((x,y))
cared.append((x_li[-1],len(s)-1))
cared.append((0,y_li[0]))
cared = sorted(list(set(cared)), key=lambda x:x[0])
return cared
简单看一下效果,并不是很理想
base_path = 'E:/jupyter/vision/identify/region2/'
path = 'E:/jupyter/vision/identify/region/'
hui_files = os.listdir(base_path)
files = os.listdir(path)
# print(hui_files, files)
for i in range(len(hui_files)):
imL = Image.open(base_path + hui_files[i])
img = Image.open(path + files[i])
imL_arr = np.array(imL)
h, w = imL_arr.shape
# print(imL_arr.shape)
matrix = get_all_mess(imL_arr, w, h)
mess = vertical(matrix)
try:
c = get_cared(mess)
except:
c = []
finally:
print(files[i],len(c), c)
结果如下图,发现很多并不是车牌字符的个数,所以整体套用的方法不能实现,仍需单个分析,感觉这部分好失败::>_<::

四. 结果分析
虽然效果并不是很好,但我还是硬着头皮做个结果分析,毕竟还是的总结错误的嘛,先来结果吧。
以前十张为训练集,后十张为测试集(请忽略这稀少的样本)
| Confusion Matrix | Predict | ||
| True | False | ||
| Real | True | 8(TP) | 2(FP) |
| False | 2(FN) | 8(TN) | |
准确率 = Accuracy = T P + T N T P + Y N + F P + F N \frac{TP+TN}{TP+YN+FP+FN} TP+YN+FP+FNTP+TN = 4 5 \frac{4}{5} 54
精确率 = precision = T P T P + F P \frac{TP}{TP+FP} TP+FPTP = 4 5 \frac{4}{5} 54
召回率 = recall = T P T P + F N \frac{TP}{TP+FN} TP+FNTP = 4 5 \frac{4}{5} 54
对于这个模型而言看精确率就ok,召回率不适用这个模型。放上图形,
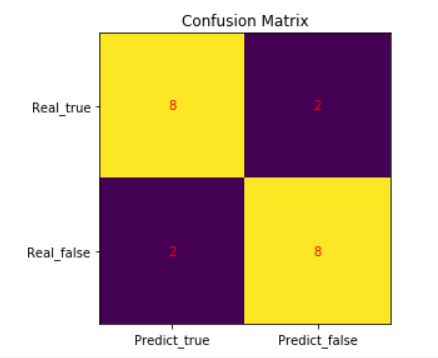
heat = np.array([[8,2],[2,8]])
fig, ax = plt.subplots()
tick_y = ["Real_true", "Real_false"]
tick_x = ["Predict_true", "Predict_false"]
ax.set_xticks(np.arange(len(tick_x)))
ax.set_yticks(np.arange(len(tick_y)))
ax.set_xticklabels(tick_x)
ax.set_yticklabels(tick_y)
for i in range(len(tick_x)):
for j in range(len(tick_y)):
text = ax.text(j, i, heat[i, j],
ha="center", va="center", color="r")
ax.set_title("Confusion Matrix")
im = ax.imshow(heat)
fig.tight_layout()
plt.show()
关于识别问题,是当下人工智能必不可少的一部分。车牌识别仅是一个小小的部分,但是对于图像的处理要求却很高,总结一下处理过程不足之处:
- 图像预处理不够,比如在膨胀操作上并不能将车牌区域全都连在一起,也就是说可以进行连通域处理,多余的噪点也不能很好的去除掉
- 分割字符串做的并不完全,但我目前没有什么更好的方法
- 代码冗长复杂,时间成本高,我仅仅是为了实现一下,并没有考虑太多的结构
- 算法的准确率不够高,提取方式仍需改进
五. CNN识别字符串
在这里不赘述CNN原理(会单独写一篇出来),通过CNN神经网络去识别字符串,随着层数的增加,准确率会更高。
代码可参考 CNN卷积神经网络实现验证码识别, 这个是没有用框架实现的CNN数字识别,只用数字是因为用了三层神经网络,仅有10个数字,计算机计算时间不算太长。若加上字符,就是 ( 10 + 26 ∗ 2 ) 3 (10+26*2)^3 (10+26∗2)3,耗时太长,而且没有加文字的训练,仅仅是了解其原理及准确率。
后记: 虽然对自己做的并没有太大的成就感,但是这个过程还是让我学到了不少东西,之后我会不断把学习的东西都总结出来…欢迎提出批评!