文本检测+识别之Mask TextSpotter
论文:Mask TextSpotter: An End-to-End Trainable Neural Network for Spotting Text with Arbitrary Shapes
文章主要基于mask RCNN做的改进,提出了一种可以对各种曲面文字进行检测的框架。并具体对10个数字+26个字母共36个字母的识别能力。

第一个图表示只能进行水平检测的框架,第二个图表示了具体方向检测能力的斜框形式的检测方法,第三个图也就是本文的Mask TextSpotter方法,可以看出检测+识别都具有更好的效果。
整体框架结构:
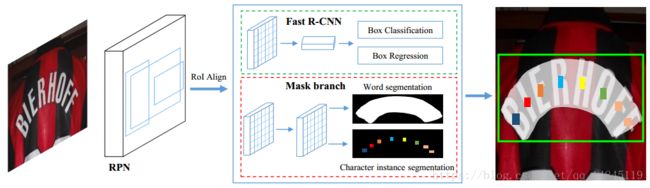
整体结构主要包含4个部分:
(1)特征金字塔FPN
该骨架网络采用Resnet50。
(2)RPN模块
该模块的anchor大小为{}32*32; 64*64; 128*128; 256*256; 512*512 }anchor长宽比为{0:5; 1; 2 }
(3)Fast RCNN模块用于文本框回归和文本分类
(4)Mask 分支,主要用于文本区域的实例分割和每一个字母的语义分割。
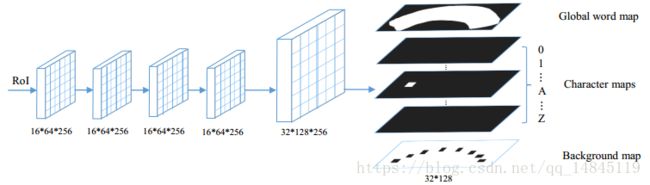
在ROI Align之后出来的特征图大小为16*64,然后经过4个卷积,1个反卷积,最终得到32*128的特征图。然后将channel维度降维为38个维度,包括1个全局文本的实例分割图,一个字符的背景分割图,10个数据+26个字母的语意分割图。
训练和测试的区别:
在训练过程中,ROI Align之后fast RCNN模块和Mask模块是同时进行的。也就是说RPN处理过剩下的大概1000-2000个框都需要进入后续的fast RCNN模块和Mask模块。这么多框进入fast RCNN模块可以理解,进入Mask模块可以起到类似随机crop的操作,更加有利于Mask模块中FCN的学习。
在测试阶段,ROI Align之后,先经过fast RCNN模块生成更加少更加精确的文本框,然后再利用这些文本框进行Mask模块的ROI Align操作。
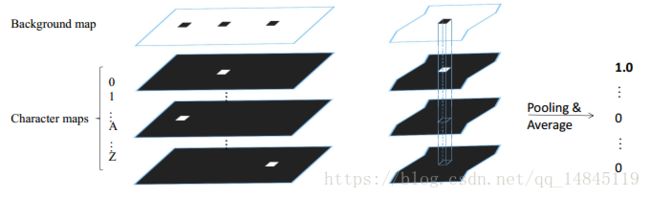
其中,求类别得分这步利用了pixel voting算法。如上图所示,对于每一个特征图通过阈值192进行二值化操作。然后计算每一个特征图中高亮区域的均值,均值得分最高的为预测的类别。
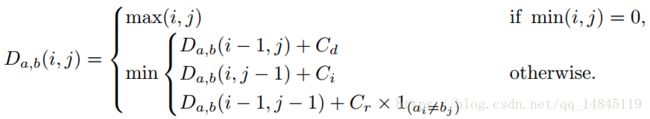
推测部分还对传统的Edit Distance进行了改进,提出了Weighted Edit Distance ,应该是识别之后的矫正工作,保证输出结果为一个真实存在的单词。

损失优化:
![]()
主要包含3个损失,RPN模块的损失,Fast RCNN模块的损失,这些都和faster RCNN的一样。Mask 模块的损失。其中平衡因子a1=1,a2=1。
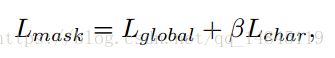
Mask 模块的损失包含了全局的实例分割的损失和每一个字符的语意分割的损失。其中平衡因子beita=1。
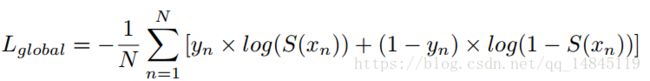
其中Lglobal是binary cross-entropy 损失。S表示gigmoid函数。

Lchar表示加权的soft-max loss 。其中T表示类别数目,N表示所有的像素数目。W表示用于平衡字符和背景的权值。
总结:
(1)Mask TextSpotter对曲面的文本具有较好的召回率。
(2)Mask TextSpotter支持整体端到端的训练,是一个集检测+识别的一体化的框架。
(3)识别部分只能识别26个字母+10个数字,简单的场景或许可以,实际应用的话,不现实。如果这里想进行更多类别的分类也不实际。