使用Python来实现钉钉自动化发送消息
- 首先pip下载第三方库:
- pip install -i https://pypi.douban.com/simple/ 要下载的库名称
- DingtalkChatbot库
第一步:电脑上开启钉钉群机器人,获取它的urlToken和secret
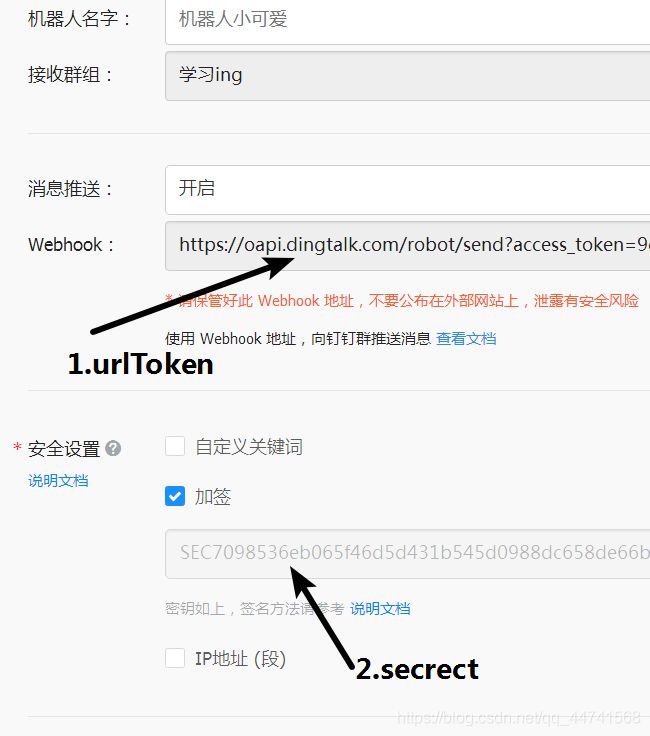
开始Python编码,只是演示,不是封装,不必在意我的中文命名
from dingtalkchatbot.chatbot import DingtalkChatbot, FeedLink
import time
import hmac
import urllib
import hashlib
import base64
# 获取链接,填入urlToken 和 secret
def getSIGN():
timestamp = str(round(time.time() * 1000))
urlToken = "你的urlToken "
secret = '你的secret '
secret_enc = secret.encode('utf-8')
string_to_sign = '{}\n{}'.format(timestamp, secret)
string_to_sign_enc = string_to_sign.encode('utf-8')
hmac_code = hmac.new(secret_enc, string_to_sign_enc, digestmod=hashlib.sha256).digest()
sign = urllib.parse.quote_plus(base64.b64encode(hmac_code))
SignMessage = urlToken + "×tamp=" + timestamp + "&sign=" + sign
return SignMessage
SignMessage = getSIGN()
xiaoDing = DingtalkChatbot(SignMessage) # 初始化机器人
def 发送文本():
"""第一: 发送文本-->
send_text(self,msg,is_at_all=False,at_mobiles=[],at_dingtalk_ids=[],is_auto_at=True)
msg: 发送的消息
is_at_all:是@所有人吗? 默认False,如果是True.会覆盖其它的属性
at_mobiles:要@的人的列表,填写的是手机号
at_dingtalk_ids:未知;文档说的是"被@人的dingtalkId(可选)"
is_auto_at:默认为True.经过测试,False是每个人一条只能@一次,重复的会过滤,否则不然,测试结果与文档不一致
"""
xiaoDing.send_text('我是陈钉,我为自己代言', is_at_all=True)
def 发送图片():
"""第二:发送图片
send_image(self, pic_url):
pic_url: "图片地址"
"""
xiaoDing.send_image("http://rrd.me/gE93L")
def 发送link():
"""第三:发送link
send_link(self, title, text, message_url, pic_url='')
title:标题 text:内容,太长会自动截取
message_url:跳转的url pic_url:添加的图片的url(可选)
"""
xiaoDing.send_link(title="今天是星期8", text="牵你的手,朝朝暮暮,牵你的手,等待明天,牵你的手,走过今生,牵你的手,生生世世",
message_url="https://baidu.com",
pic_url="http://rrd.me/gE93L")
def 发送markdown():
"""第四:发送markdown
send_markdown(self,title,text,is_at_all=False,at_mobiles=[],at_dingtalk_ids=[],is_auto_at=True)
title:标题 text:内容
is_at_all: @所有人时:true,否则为:false(可选)
at_mobiles: 被@人的手机号(默认自动添加在text内容末尾,可取消自动化添加改为自定义设置,可选)
at_dingtalk_ids: 被@人的dingtalkId(可选)
is_auto_at: 是否自动在text内容末尾添加@手机号,默认自动添加,可设置为False取消(可选)
"""
xiaoDing.send_markdown(title="我是标题",text="我是内容,啊哈哈哈哈哈",is_at_all=True)
def 发送图片超链接():
# send_feed_card(links)
"""
links是一个列表a,列表里每个元素又是列表b
列表b的属性:
title:标题 message_url:点开后跳转的URL pic_url:图片的地址
Returns:
"""
feedlink1 = FeedLink(title="猫1", message_url="https://www.badiu.com/",
pic_url="http://rrd.me/gE9zB")
feedlink2 = FeedLink(title="猫2", message_url="https://www.badiu.com/",
pic_url="http://rrd.me/gE9zN")
feedlink3 = FeedLink(title="猫3", message_url="https://www.badiu.com/",
pic_url="http://rrd.me/gE9zV")
feedlin4k = FeedLink(title="猫4", message_url="https://www.badiu.com/",
pic_url="http://rrd.me/gE92a")
links = [feedlink1, feedlink2, feedlink3, feedlin4k]
xiaoDing.send_feed_card(links)
接下来就是展示自己使用场景的时候了
sched实现定时任务
结合爬虫, 数据分析得到的结果
… …
PS:26日更新
分享一个自己写的天气爬虫,可以直接运行
import re
import requests
import datetime
def 爬虫获取明日天气():
place = "杭州"
url = "http://tianqi.2345.com/tomorrow-58457.htm"
# 杭州天气对应的网址,其它的自己去该网站查找,也可以自己再写一个根据地名获取url的爬虫,随意
r = requests.get(url)
r.encoding = 'gb2312'
main = r.text # 得到信息
tomorrow = datetime.date.today() + datetime.timedelta(days=1) # 获取第二天的日期
day1 = '明日白天(.*?)猜您感兴趣' # 获取天气的正则
day2 = '明日生活指数(.*?)精选推荐' # 获取穿衣指数的正则
天气信息 = re.findall(day1, main, re.S)[0]
天气白天 = re.findall('class="phrase">(.*?)', 天气信息, re.S)[0]
天气晚上 = re.findall('class="phrase">(.*?)', 天气信息, re.S)[1]
信息 = ""
天气 = ""
if 天气白天 == 天气晚上:
天气 = 天气白天
else:
天气 = 天气白天 + "转" + 天气晚上
最高温度 = re.findall('最高:(.*?)', 天气信息, re.S)[0]+"℃"
最低温度 = re.findall('最低:(.*?)', 天气信息, re.S)[0]+"℃"
空气质量 = re.findall('id="aqiText">(.*?)', 天气信息, re.S)[0]
风力 = re.findall('风力:(.*?)', 天气信息, re.S)[0]
湿度 = re.findall('湿度:(.*?)', 天气信息, re.S)[0]
紫外线强度 = re.findall('紫外线强度:(.*?)', 天气信息, re.S)[0]
信息 += "宝贝晚上好呀,明天是" + str(tomorrow) + ","+place + "的天气: " + 天气 + \
"\n"+"温度:" + 最低温度 + "~" + 最高温度 + \
"\n"+"空气质量:"+空气质量+",风力:"+风力 + \
"\n"+"湿度:"+湿度 +\
"\n"+"紫外线强度:"+紫外线强度
穿衣指数信息 = re.findall(day2, main, re.S)[0]
穿着 = re.findall(' (.*?)