Python学习笔记——科学计算工具Numpy
目录
Numpy(Numerical Python)
numpy的常用操作
numpy中常见的更多数据类型
数据类型的操作
数组的形状
数组和数的计算
数组和数组的计算
广播原则
轴
二维数组的轴
三维数组的轴
numpy读取数据
numpy中的转置
numpy索引和切片
numpy中数值的修改
numpy中布尔索引
numpy中三元运算符
numpy中的clip(裁剪)
numpy中的nan和inf
numpy中的nan的注意点
numpy中常用统计函数
ndarry缺失值填充均值
数组的拼接
数组的行列交换
numpy更多好用的方法
numpy生成随机数
分布的补充
1、均匀分布
numpy的注意点copy和view
ndarray 多维数组(N Dimension Array)
ndarray的随机创建
ndarray的序列创建
1. np.array(collection)
2. np.zeros()
3. np.ones()
4. np.empty()
5. np.arange() 和 reshape()
6. np.arange() 和 random.shuffle()
ndarray的数据类型
1. dtype参数
2. astype方法
ndarray的矩阵运算
1. 矢量运算:相同大小的数组间运算应用在元素上
2. 矢量和标量运算:"广播" - 将标量"广播"到各个元素
ndarray的索引与切片
1. 一维数组的索引与切片
2. 多维数组的索引与切片:
3. 条件索引
ndarray的维数转换
元素计算函数
元素统计函数
元素判断函数
元素去重排序函数
2016年美国总统大选民意调查数据统计:
示例代码1 :
示例代码2:
Numpy(Numerical Python)
Numpy:提供了一个在Python中做科学计算的基础库,重在数值计算,主要用于多维数组(矩阵)处理的库。用来存储和处理大型矩阵,比Python自身的嵌套列表结构要高效的多。本身是由C语言开发,是个很基础的扩展,Python其余的科学计算扩展大部分都是以此为基础。
-
高性能科学计算和数据分析的基础包
-
ndarray,多维数组(矩阵),具有矢量运算能力,快速、节省空间
-
矩阵运算,无需循环,可完成类似Matlab中的矢量运算
-
线性代数、随机数生成
-
import numpy as np
Scipy
Scipy :基于Numpy提供了一个在Python中做科学计算的工具集,专为科学和工程设计的Python工具包。主要应用于统计、优化、整合、线性代数模块、傅里叶变换、信号和图像处理、常微分方程求解、稀疏矩阵等,在数学系或者工程系相对用的多一些,和数据处理的关系不大, 我们知道即可,这里不做讲解。
-
在NumPy库的基础上增加了众多的数学、科学及工程常用的库函数
-
线性代数、常微分方程求解、信号处理、图像处理
-
一般的数据处理numpy已经够用
-
import scipy as sp
参考学习资料:
Python、NumPy和SciPy介绍:http://cs231n.github.io/python-numpy-tutorial
NumPy和SciPy快速入门:https://docs.scipy.org/doc/numpy-dev/user/quickstart.html
numpy的常用操作
numpy中常见的更多数据类型

数据类型的操作
数组的形状


数组和数的计算

数组和数组的计算






广播原则

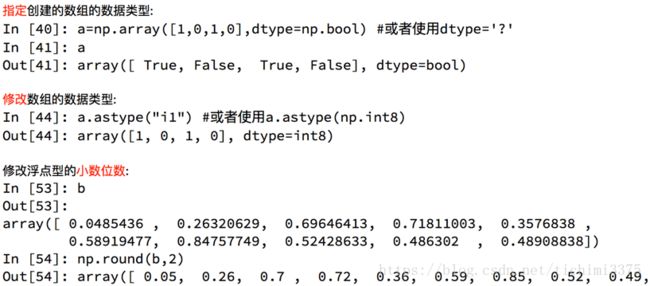
轴
在numpy中可以理解为方向,使用0,1,2...数字表示,对于一个一维数组,只有一个0轴,对于2维数组(shape(2,2)),有0轴和1轴,对于三维数组(shape(2,2, 3)),有0,1,2轴
有了轴的概念之后,我们计算会更加方便,比如计算一个2维数组的平均值,必须指定是计算哪个方向上面的数字的平均值
二维数组的轴
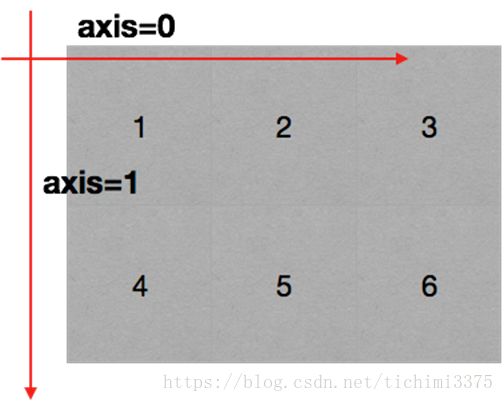
三维数组的轴
numpy读取数据
CSV:Comma-Separated Value,逗号分隔值文件
显示:表格状态
源文件:换行和逗号分隔行列的格式化文本,每一行的数据表示一条记录
由于csv便于展示,读取和写入,所以很多地方也是用csv的格式存储和传输中小型的数据,为了方便教学,我们会经常操作csv格式的文件,但是操作数据库中的数据也是很容易的实现的
np.loadtxt(fname,dtype=np.float,delimiter=None,skiprows=0,usecols=None,unpack=False)


numpy中的转置


numpy索引和切片


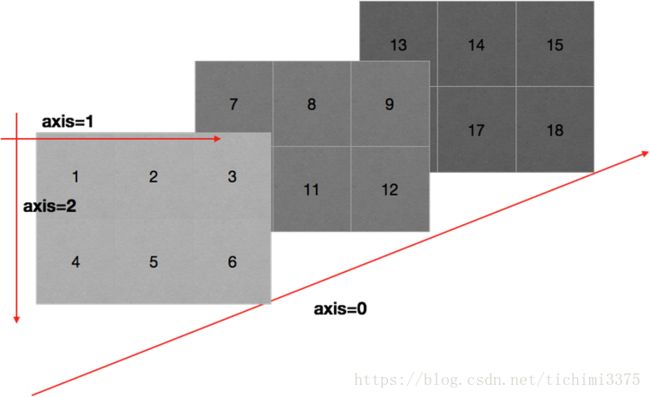
numpy中数值的修改

numpy中布尔索引
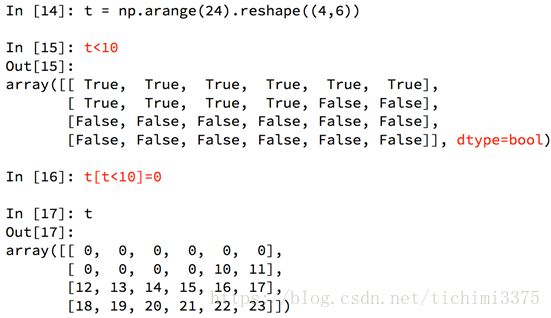
numpy中三元运算符

numpy中的clip(裁剪)
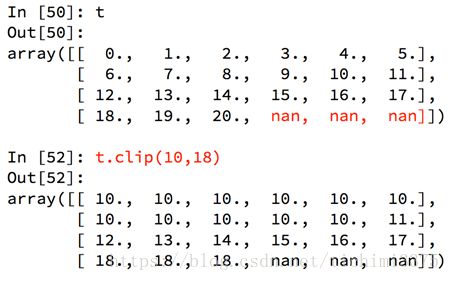
numpy中的nan和inf
nan(NAN,Nan):not a number表示不是一个数字
什么时候numpy中会出现nan:
当我们读取本地的文件为float的时候,如果有缺失,就会出现nan
当做了一个不合适的计算的时候(比如无穷大(inf)减去无穷大)
inf(-inf,inf):infinity,inf表示正无穷,-inf表示负无穷
什么时候回出现inf包括(-inf,+inf)
比如一个数字除以0,(python中直接会报错,numpy中是一个inf或者-inf)

numpy中的nan的注意点

numpy中常用统计函数
求和:t.sum(axis=None)
均值:t.mean(a,axis=None) 受离群点的影响较大
中值:np.median(t,axis=None)
最大值:t.max(axis=None)
最小值:t.min(axis=None)
极值:np.ptp(t,axis=None) 即最大值和最小值只差
标准差:t.std(axis=None)
标准差是一组数据平均值分散程度的一种度量。一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值
反映出数据的波动稳定情况,越大表示波动越大,约不稳定
默认返回多维数组的全部的统计结果,如果指定axis则返回一个当前轴上的结果
ndarry缺失值填充均值
t中存在nan值,如何操作把其中的nan填充为每一列的均值
t = array([[ 0., 1., 2., 3., 4., 5.],
[ 6., 7., nan, 9., 10., 11.],
[ 12., 13., 14., nan, 16., 17.],
[ 18., 19., 20., 21., 22., 23.]])

数组的拼接

数组的行列交换

numpy更多好用的方法
1.获取最大值最小值的位置
1. np.argmax(t,axis=0)
2. np.argmin(t,axis=1)
2.创建一个全0的数组: np.zeros((3,4))
3.创建一个全1的数组:np.ones((3,4))
4.创建一个对角线为1的正方形数组(方阵):np.eye(3)
numpy生成随机数

分布的补充
1、均匀分布
在相同的大小范围内的出现概率是等可能的
2、正态分布
呈钟型,两头低,中间高,左右对称

numpy的注意点copy和view
1.a=b 完全不复制,a和b相互影响
2.a = b[:],视图的操作,一种切片,会创建新的对象a,但是a的数据完全由b保管,他们两个的数据变化是一致的,
3.a = b.copy(),复制,a和b互不影响
ndarray 多维数组(N Dimension Array)
NumPy数组是一个多维的数组对象(矩阵),称为ndarray,具有矢量算术运算能力和复杂的广播能力,并具有执行速度快和节省空间的特点。
注意:ndarray的下标从0开始,且数组里的所有元素必须是相同类型
ndarray拥有的属性
ndim属性:维度个数shape属性:维度大小dtype属性:数据类型
ndarray的随机创建
通过随机抽样 (numpy.random) 生成随机数据。
示例代码:
# 导入numpy,别名np
import numpy as np
# 生成指定维度大小(3行4列)的随机多维浮点型数据(二维),rand固定区间0.0 ~ 1.0
arr = np.random.rand(3, 4)
print(arr)
print(type(arr))
# 生成指定维度大小(3行4列)的随机多维整型数据(二维),randint()可以指定区间(-1, 5)
arr = np.random.randint(-1, 5, size = (3, 4)) # 'size='可省略
print(arr)
print(type(arr))
# 生成指定维度大小(3行4列)的随机多维浮点型数据(二维),uniform()可以指定区间(-1, 5)
arr = np.random.uniform(-1, 5, size = (3, 4)) # 'size='可省略
print(arr)
print(type(arr))
print('维度个数: ', arr.ndim)
print('维度大小: ', arr.shape)
print('数据类型: ', arr.dtype)
运行结果:
[[ 0.09371338 0.06273976 0.22748452 0.49557778]
[ 0.30840042 0.35659161 0.54995724 0.018144 ]
[ 0.94551493 0.70916088 0.58877255 0.90435672]]
[[ 1 3 0 1]
[ 1 4 4 3]
[ 2 0 -1 -1]]
[[ 2.25275308 1.67484038 -0.03161878 -0.44635706]
[ 1.35459097 1.66294159 2.47419548 -0.51144655]
[ 1.43987571 4.71505054 4.33634358 2.48202309]]
维度个数: 2
维度大小: (3, 4)
数据类型: float64
ndarray的序列创建
1. np.array(collection)
collection 为 序列型对象(list)、嵌套序列对象(list of list)。
示例代码:
# list序列转换为 ndarray
lis = range(10)
arr = np.array(lis)
print(arr) # ndarray数据
print(arr.ndim) # 维度个数
print(arr.shape) # 维度大小
# list of list嵌套序列转换为ndarray
lis_lis = [range(10), range(10)]
arr = np.array(lis_lis)
print(arr) # ndarray数据
print(arr.ndim) # 维度个数
print(arr.shape) # 维度大小
运行结果:
# list序列转换为 ndarray
[0 1 2 3 4 5 6 7 8 9]
1
(10,)
# list of list嵌套序列转换为 ndarray
[[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]]
2
(2, 10)
2. np.zeros()
指定大小的全0数组。注意:第一个参数是元组,用来指定大小,如(3, 4)。
3. np.ones()
指定大小的全1数组。注意:第一个参数是元组,用来指定大小,如(3, 4)。
4. np.empty()
初始化数组,不是总是返回全0,有时返回的是未初始的随机值(内存里的随机值)。
示例代码(2、3、4):
# np.zeros
zeros_arr = np.zeros((3, 4))
# np.ones
ones_arr = np.ones((2, 3))
# np.empty
empty_arr = np.empty((3, 3))
# np.empty 指定数据类型
empty_int_arr = np.empty((3, 3), int)
print('------zeros_arr-------')
print(zeros_arr)
print('\n------ones_arr-------')
print(ones_arr)
print('\n------empty_arr-------')
print(empty_arr)
print('\n------empty_int_arr-------')
print(empty_int_arr)
运行结果:
------zeros_arr-------
[[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]]
------ones_arr-------
[[ 1. 1. 1.]
[ 1. 1. 1.]]
------empty_arr-------
[[ 0. 0. 0.]
[ 0. 0. 0.]
[ 0. 0. 0.]]
------empty_int_arr-------
[[0 0 0]
[0 0 0]
[0 0 0]]
5. np.arange() 和 reshape()
arange() 类似 python 的 range() ,创建一个一维 ndarray 数组。
reshape() 将 重新调整数组的维数。
示例代码(5):
# np.arange()
arr = np.arange(15) # 15个元素的 一维数组
print(arr)
print(arr.reshape(3, 5)) # 3x5个元素的 二维数组
print(arr.reshape(1, 3, 5)) # 1x3x5个元素的 三维数组
运行结果:
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14]
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]]
[[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]]]
6. np.arange() 和 random.shuffle()
random.shuffle() 将打乱数组序列(类似于洗牌)。
示例代码(6):
arr = np.arange(15)
print(arr)
np.random.shuffle(arr)
print(arr)
print(arr.reshape(3,5))
运行结果:
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14]
[ 5 8 1 7 4 0 12 9 11 2 13 14 10 3 6]
[[ 5 8 1 7 4]
[ 0 12 9 11 2]
[13 14 10 3 6]]
ndarray的数据类型
1. dtype参数
指定数组的数据类型,类型名+位数,如float64, int32
2. astype方法
转换数组的数据类型
示例代码(1、2):
# 初始化3行4列数组,数据类型为float64
zeros_float_arr = np.zeros((3, 4), dtype=np.float64)
print(zeros_float_arr)
print(zeros_float_arr.dtype)
# astype转换数据类型,将已有的数组的数据类型转换为int32
zeros_int_arr = zeros_float_arr.astype(np.int32)
print(zeros_int_arr)
print(zeros_int_arr.dtype)
运行结果:
[[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]]
float64
[[0 0 0 0]
[0 0 0 0]
[0 0 0 0]]
int32ndarray的矩阵运算
数组是编程中的概念,矩阵、矢量是数学概念。
在计算机编程中,矩阵可以用数组形式定义,矢量可以用结构定义!
1. 矢量运算:相同大小的数组间运算应用在元素上
示例代码(1):
# 矢量与矢量运算
arr = np.array([[1, 2, 3],
[4, 5, 6]])
print("元素相乘:")
print(arr * arr)
print("矩阵相加:")
print(arr + arr)
运行结果:
元素相乘:
[[ 1 4 9]
[16 25 36]]
矩阵相加:
[[ 2 4 6]
[ 8 10 12]]
2. 矢量和标量运算:"广播" - 将标量"广播"到各个元素
示例代码(2):
# 矢量与标量运算
print(1. / arr)
print(2. * arr)
运行结果:
[[ 1. 0.5 0.33333333]
[ 0.25 0.2 0.16666667]]
[[ 2. 4. 6.]
[ 8. 10. 12.]]
ndarray的索引与切片
1. 一维数组的索引与切片
与Python的列表索引功能相似
示例代码(1):
# 一维数组
arr1 = np.arange(10)
print(arr1)
print(arr1[2:5])
运行结果:
[0 1 2 3 4 5 6 7 8 9]
[2 3 4]
2. 多维数组的索引与切片:
arr[r1:r2, c1:c2]
arr[1,1] 等价 arr[1][1]
[:] 代表某个维度的数据
示例代码(2):
# 多维数组
arr2 = np.arange(12).reshape(3,4)
print(arr2)
print(arr2[1])
print(arr2[0:2, 2:])
print(arr2[:, 1:3])
运行结果:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[4 5 6 7]
[[2 3]
[6 7]]
[[ 1 2]
[ 5 6]
[ 9 10]]
3. 条件索引
布尔值多维数组:arr[condition],condition也可以是多个条件组合。
注意,多个条件组合要使用 & | 连接,而不是Python的 and or。
示例代码(3):
# 条件索引
# 找出 data_arr 中 2005年后的数据
data_arr = np.random.rand(3,3)
print(data_arr)
year_arr = np.array([[2000, 2001, 2000],
[2005, 2002, 2009],
[2001, 2003, 2010]])
is_year_after_2005 = year_arr >= 2005
print(is_year_after_2005, is_year_after_2005.dtype)
filtered_arr = data_arr[is_year_after_2005]
print(filtered_arr)
#filtered_arr = data_arr[year_arr >= 2005]
#print(filtered_arr)
# 多个条件
filtered_arr = data_arr[(year_arr <= 2005) & (year_arr % 2 == 0)]
print(filtered_arr)
运行结果:
[[ 0.53514038 0.93893429 0.1087513 ]
[ 0.32076215 0.39820313 0.89765765]
[ 0.6572177 0.71284822 0.15108756]]
[[False False False]
[ True False True]
[False False True]] bool
[ 0.32076215 0.89765765 0.15108756]
#[ 0.32076215 0.89765765 0.15108756]
[ 0.53514038 0.1087513 0.39820313]
ndarray的维数转换
二维数组直接使用转换函数:transpose()
高维数组转换要指定维度编号参数 (0, 1, 2, …),注意参数是元组
示例代码:
arr = np.random.rand(2,3) # 2x3 数组
print(arr)
print(arr.transpose()) # 转换为 3x2 数组
arr3d = np.random.rand(2,3,4) # 2x3x4 数组,2对应0,3对应1,4对应3
print(arr3d)
print(arr3d.transpose((1,0,2))) # 根据维度编号,转为为 3x2x4 数组
运行结果:
# 二维数组转换
# 转换前:
[[ 0.50020075 0.88897914 0.18656499]
[ 0.32765696 0.94564495 0.16549632]]
# 转换后:
[[ 0.50020075 0.32765696]
[ 0.88897914 0.94564495]
[ 0.18656499 0.16549632]]
# 高维数组转换
# 转换前:
[[[ 0.91281153 0.61213743 0.16214062 0.73380458]
[ 0.45539155 0.04232412 0.82857746 0.35097793]
[ 0.70418988 0.78075814 0.70963972 0.63774692]]
[[ 0.17772347 0.64875514 0.48422954 0.86919646]
[ 0.92771033 0.51518773 0.82679073 0.18469917]
[ 0.37260457 0.49041953 0.96221477 0.16300198]]]
# 转换后:
[[[ 0.91281153 0.61213743 0.16214062 0.73380458]
[ 0.17772347 0.64875514 0.48422954 0.86919646]]
[[ 0.45539155 0.04232412 0.82857746 0.35097793]
[ 0.92771033 0.51518773 0.82679073 0.18469917]]
[[ 0.70418988 0.78075814 0.70963972 0.63774692]
[ 0.37260457 0.49041953 0.96221477 0.16300198]]]元素计算函数
-
ceil(): 向上最接近的整数,参数是 number 或 array -
floor(): 向下最接近的整数,参数是 number 或 array rint(): 四舍五入,参数是 number 或 arrayisnan(): 判断元素是否为 NaN(Not a Number),参数是 number 或 arraymultiply(): 元素相乘,参数是 number 或 arraydivide(): 元素相除,参数是 number 或 arrayabs():元素的绝对值,参数是 number 或 arraywhere(condition, x, y): 三元运算符,x if condition else y
示例代码(1、2、3、4、5、6、7):
# randn() 返回具有标准正态分布的序列。
arr = np.random.randn(2,3)
print(arr)
print(np.ceil(arr))
print(np.floor(arr))
print(np.rint(arr))
print(np.isnan(arr))
print(np.multiply(arr, arr))
print(np.divide(arr, arr))
print(np.where(arr > 0, 1, -1))
运行结果:
# print(arr)
[[-0.75803752 0.0314314 1.15323032]
[ 1.17567832 0.43641395 0.26288021]]
# print(np.ceil(arr))
[[-0. 1. 2.]
[ 2. 1. 1.]]
# print(np.floor(arr))
[[-1. 0. 1.]
[ 1. 0. 0.]]
# print(np.rint(arr))
[[-1. 0. 1.]
[ 1. 0. 0.]]
# print(np.isnan(arr))
[[False False False]
[False False False]]
# print(np.multiply(arr, arr))
[[ 5.16284053e+00 1.77170104e+00 3.04027254e-02]
[ 5.11465231e-03 3.46109263e+00 1.37512421e-02]]
# print(np.divide(arr, arr))
[[ 1. 1. 1.]
[ 1. 1. 1.]]
# print(np.where(arr > 0, 1, -1))
[[ 1 1 -1]
[-1 1 1]]
元素统计函数
-
np.mean(),np.sum():所有元素的平均值,所有元素的和,参数是 number 或 array -
np.max(),np.min():所有元素的最大值,所有元素的最小值,参数是 number 或 array np.std(),np.var():所有元素的标准差,所有元素的方差,参数是 number 或 arraynp.argmax(),np.argmin():最大值的下标索引值,最小值的下标索引值,参数是 number 或 arraynp.cumsum(),np.cumprod():返回一个一维数组,每个元素都是之前所有元素的 累加和 和 累乘积,参数是 number 或 array- 多维数组默认统计全部维度,
axis参数可以按指定轴心统计,值为0则按列统计,值为1则按行统计。
示例代码:
arr = np.arange(12).reshape(3,4)
print(arr)
print(np.cumsum(arr)) # 返回一个一维数组,每个元素都是之前所有元素的 累加和
print(np.sum(arr)) # 所有元素的和
print(np.sum(arr, axis=0)) # 数组的按列统计和
print(np.sum(arr, axis=1)) # 数组的按行统计和
运行结果:
# print(arr)
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
# print(np.cumsum(arr))
[ 0 1 3 6 10 15 21 28 36 45 55 66]
# print(np.sum(arr)) # 所有元素的和
66
# print(np.sum(arr, axis=0)) # 0表示对数组的每一列的统计和
[12 15 18 21]
# print(np.sum(arr, axis=1)) # 1表示数组的每一行的统计和
[ 6 22 38]
元素判断函数
np.any(): 至少有一个元素满足指定条件,返回Truenp.all(): 所有的元素满足指定条件,返回True
示例代码:
arr = np.random.randn(2,3)
print(arr)
print(np.any(arr > 0))
print(np.all(arr > 0))
运行结果:
[[ 0.05075769 -1.31919688 -1.80636984]
[-1.29317016 -1.3336612 -0.19316432]]
True
False
元素去重排序函数
np.unique():找到唯一值并返回排序结果,类似于Python的set集合
示例代码:
arr = np.array([[1, 2, 1], [2, 3, 4]])
print(arr)
print(np.unique(arr))
运行结果:
[[1 2 1]
[2 3 4]]
[1 2 3 4]2016年美国总统大选民意调查数据统计:
-
项目地址:https://www.kaggle.com/fivethirtyeight/2016-election-polls
-
该数据集包含了2015年11月至2016年11月期间对于2016美国大选的选票数据,共27列数据
示例代码1 :
# loadtxt
import numpy as np
# csv 名逗号分隔值文件
filename = './presidential_polls.csv'
# 通过loadtxt()读取本地csv文件
data_array = np.loadtxt(filename, # 文件名
delimiter=',', # 分隔符
dtype=str, # 数据类型,数据是Unicode字符串
usecols=(0,2,3)) # 指定读取的列号
# 打印ndarray数据,保留第一行
print(data_array, data_array.shape)
运行结果:
[["b'cycle'" "b'type'" "b'matchup'"]
["b'2016'" 'b\'"polls-plus"\'' 'b\'"Clinton vs. Trump vs. Johnson"\'']
["b'2016'" 'b\'"polls-plus"\'' 'b\'"Clinton vs. Trump vs. Johnson"\'']
...,
["b'2016'" 'b\'"polls-only"\'' 'b\'"Clinton vs. Trump vs. Johnson"\'']
["b'2016'" 'b\'"polls-only"\'' 'b\'"Clinton vs. Trump vs. Johnson"\'']
["b'2016'" 'b\'"polls-only"\'' 'b\'"Clinton vs. Trump vs. Johnson"\'']] (10237, 3)
示例代码2:
import numpy as np
# 读取列名,即第一行数据
with open(filename, 'r') as f:
col_names_str = f.readline()[:-1] # [:-1]表示不读取末尾的换行符'\n'
# 将字符串拆分,并组成列表
col_name_lst = col_names_str.split(',')
# 使用的列名:结束时间,克林顿原始票数,川普原始票数,克林顿调整后票数,川普调整后票数
use_col_name_lst = ['enddate', 'rawpoll_clinton', 'rawpoll_trump','adjpoll_clinton', 'adjpoll_trump']
# 获取相应列名的索引号
use_col_index_lst = [col_name_lst.index(use_col_name) for use_col_name in use_col_name_lst]
# 通过genfromtxt()读取本地csv文件,
data_array = np.genfromtxt(filename, # 文件名
delimiter=',', # 分隔符
#skiprows=1, # 跳过第一行,即跳过列名
dtype=str, # 数据类型,数据不再是Unicode字符串
usecols=use_col_index_lst)# 指定读取的列索引号
# genfromtxt() 不能通过 skiprows 跳过第一行的
# ['enddate' 'rawpoll_clinton' 'rawpoll_trump' 'adjpoll_clinton' 'adjpoll_trump']
# 去掉第一行
data_array = data_array[1:]
# 打印ndarray数据
print(data_array[1:], data_array.shape)
运行结果:
[['10/30/2016' '45' '46' '43.29659' '44.72984']
['10/30/2016' '48' '42' '46.29779' '40.72604']
['10/24/2016' '48' '45' '46.35931' '45.30585']
...,
['9/22/2016' '46.54' '40.04' '45.9713' '39.97518']
['6/21/2016' '43' '43' '45.2939' '46.66175']
['8/18/2016' '32.54' '43.61' '31.62721' '44.65947']] (10236, 5)