neo4j图数据库--Cypher入门
1、Cypher 查询语言简单使用
1.1.基本语法
Node语法:
Cypher使用一对圆括号来表示一个节点:提供了多种格式如下:
( ) 匿名节点
(matrix) 为节点添加一个ID
(:Movie) Movie label标签,声明的是节点类型。noe4j的索引使用label,每个索引由标签和属性组成
(matrix:Movie)
(matrix:Movie {title: "The Matrix"}) 节点属性。 (如:title)代表一个key\value 的List
(matrix:Movie {title: "The Matrix", released: 1997})
RelationShip语法:
-- 表示一个无指向的关系
--> 表示一个有指向的关系
[ ] 能够添加ID,属性,类型等信息
-[role]->
-[:ACTED_IN]-> ACTED_IN是标签
-[role:ACTED_IN]->
-[role:ACTED_IN {roles: ["Neo"]}]->
Pattern 语法:
节点和关系语法的合并就表示模式。
(keanu:Person:Actor {name: "Keanu Reeves"} )
-[role:ACTED_IN {roles: ["Neo"] } ]->
(matrix:Movie {title: "The Matrix"} )
Pattern Identifiers :
为模式分配ID,为例增加模块化和重复使用
acted_in = (:Person)-[:ACTED_IN]->(:Movie)
1.2.模式实践
bin/neo4j-shell(或者cypher-shell)
创建一个节点数据:
CREATE (:Movie { title:"The Matrix",released:1997 }) ;

如果想返回创建的数据,需要指定ID:
create (p:Person {name:"weiw", born:2000}) return p;

创建多个节点数据,多个元素间用逗号或者用create分开:
create (a:Person {name:"jiaj",born:2003})-[r:ACTED_IN {roles:["student"]}]->(m:School {name:"CDLG",address:"chengdu"})
create (d:Person {name:"weiw",born:2001})-[:DIRECTED]->(m)
return a,d,r,m;

Matching Patterns :模式匹配
我们想连接新的数据到已经存在的结构,这个需求需要我们知道怎样找到在图中已经存在的模式。
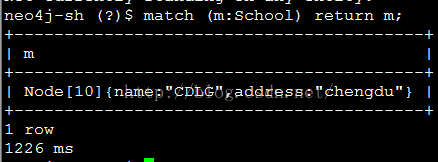
match (m:School) return m;
match (p:Person {name:"weiw"}) return p;

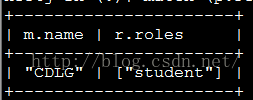
match (p:Person {name:"jiaj"})-[r:ACTED_IN]->(m:School) return m.name, r.roles;
Attaching Structures:
将match和create进行合并使用。将匹配到的节点连接到一个新的节点上。
match (p:Person {name:"jiaj"})
create (m:School {name:"DEJY",address:"deyang"})
create (p)-[r:ACTED_IN {roles:["studeng"]}]->(m)
return p,r,m;

Completing Patterns :
merge在查找时,如果找到则返回,如果没找到则创建。可以避免创建重复的节点
merge (m:School {name:"SCDX"})
on create set m.address="chegndu"
return m;
MATCH (m:School { name:"CDLG" })
MATCH (p:Person { name:"jiaj" })
MERGE (p)-[r:ACTED_IN]->(m)
ON CREATE SET r.roles =['teacher']
RETURN p,r,m ;

之前的案列中,关联的方向是随意的,你可以改变箭头的指向。MERGE 会检查关联两边的方向,如果没有匹配到关系,则创建一个新的方向的关系。
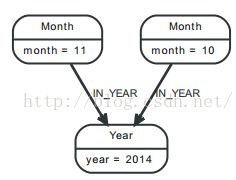
CREATE (y:Year { year:2014 })
MERGE (y)<-[:IN_YEAR]-(m10:Month { month:10 })
MERGE (y)<-[:IN_YEAR]-(m11:Month { month:11 })
RETURN y,m10,m11 ;
1.3.Getting the Results You Want
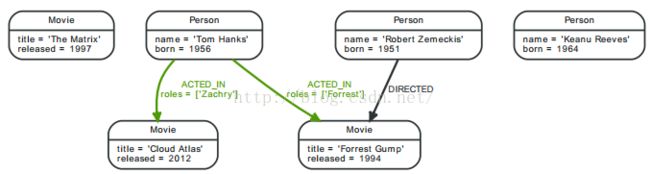
数据准备:以人在电影中扮演的角色为例
CREATE (matrix:Movie { title:"The Matrix",released:1997 })
CREATE (cloudAtlas:Movie { title:"Cloud Atlas",released:2012 })
CREATE (forrestGump:Movie { title:"Forrest Gump",released:1994 })
CREATE (keanu:Person { name:"Keanu Reeves", born:1964 })
CREATE (robert:Person { name:"Robert Zemeckis", born:1951 })
CREATE (tom:Person { name:"Tom Hanks", born:1956 })
CREATE (tom)-[:ACTED_IN { roles: ["Forrest"]}]->(forrestGump)
CREATE (tom)-[:ACTED_IN { roles: ['Zachry']}]->(cloudAtlas)
CREATE (robert)-[:DIRECTED]->(forrestGump)
Filtering Results :数据过滤
常用谓词:AND, OR, XOR,NOT
match (m:Movie) where m.title="The Matrix" return m;

MATCH (p:Person)-[r:ACTED_IN]->(m:Movie)
WHERE p.name =~ "K.+" OR m.released > 2000 OR "Neo" IN r.roles
RETURN p,r,m ;
最后一个角色条件没有完全匹配上:

MATCH (p:Person)-[:ACTED_IN]->(m)
WHERE NOT (p)-[:DIRECTED]->()
RETURN p,m ;
Returning Results :结果返回
返回 numbers, strings and arrays as [1,2,3], and maps like {name:"Tom Hanks", born:1964, movies:["Forrest Gump", ...], count:13}.
常用表达式:
names[0] ,movies[1..-1]. length(array), toInt("12"), substring("2014-07-01",0,4), or coalesce(p.nickname,"n/a") ,DISTINCT
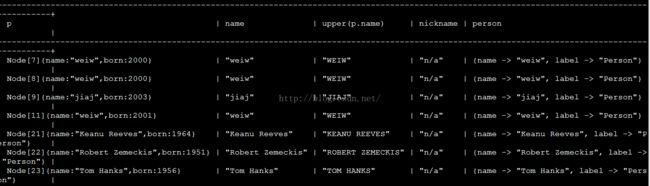
MATCH (p:Person)
RETURN p, p.name AS name, upper(p.name), coalesce(p.nickname,"n/a") AS nickname, { name: p.name, label:head(labels(p))} AS person;
Aggregating Information:聚合操作
常用聚合: count, sum, avg, min, max,count(DISTINCT role),NULL值自动跳过
MATCH (:Person) RETURN count(*) AS people

To find out how often an actor and director worked together, you’d run this statement:
MATCH (actor:Person)-[:ACTED_IN]->(movie:Movie)<-[:DIRECTED]-(director:Person)
RETURN actor,director,count(*) AS collaborations
Ordering and Pagination :排序和分页
排序用法:ORDER BY person.age
分页用法:SKIP {offset} LIMIT {count}
MATCH (a:Person)-[:ACTED_IN]->(m:Movie)
RETURN a,count(*) AS appearances
ORDER BY appearances DESC LIMIT 10;
Collecting Aggregation:聚集聚合
collects all aggregated values into a real array or list。
MATCH (m:Movie)<-[:ACTED_IN]-(a:Person)
RETURN m.title AS movie, collect(a.name) AS cast, count(*) AS actors

1.4.Compose Large Statements:编写大型语句
UNION:
MATCH (p:Person)-[r:ACTED_IN]->(m:Movie)
RETURN p,type(r) AS rel,m
UNION
MATCH (p:Person)-[r:DIRECTED]->(m:Movie)
RETURN p,type(r) AS rel,m
WITH:
1.5.Utilizing Data Structures
MATCH (m:Movie)<-[:ACTED_IN]-(a:Person)
RETURN m.title AS movie, collect(a.name)[0..5] AS five_of_cast
List谓词:
When using lists and arrays in comparisons you can use predicates like value IN list or any(x IN list
WHERE x = value). There are list predicates to satisfy conditions for all, any, none and single elements.
MATCH path =(:Person)-->(:Movie)<--(:Person)
WHERE ALL (r IN rels(path) WHERE type(r)= 'ACTED_IN') AND ANY (n IN nodes(path) WHERE n.name = 'Clint Eastwood')
RETURN path
List处理:
you want to process lists to filter, aggregate (reduce) or transform (extract) their values.
WITH range(1,10) AS numbers
WITH extract(n IN numbers | n*n) AS squares
WITH filter(n IN squares WHERE n > 25) AS large_squares
RETURN reduce(a = 0, n IN large_squares | a + n) AS sum_large_squares;

MATCH (m:Movie)<-[r:ACTED_IN]-(a:Person)
WITH m.title AS movie, collect({ name: a.name, roles: r.roles }) AS cast
RETURN movie, extract(c2 IN filter(c1 IN cast WHERE c1.name =~ "T.*")| c2.roles)
Unwind Lists:列表展开
you have collected information into a list, but want to use each element individually as a row。For instance, you might want to further match patterns in the graph.
MATCH (a:Person)-[:ACTED_IN]->(m:Movie)<-[:ACTED_IN]-(colleague:Person)
WITH colleague, count(*) AS frequency, collect(DISTINCT m) AS movies
ORDER BY frequency DESC LIMIT 5 UNWIND movies AS m
MATCH (m)<-[:ACTED_IN]-(a)
RETURN m.title AS movie, collect(a.name) AS cast
1.6.Labels, Constraints and Indexes
使用约束: title被唯一化约束
adding the unique constraint will add an index on that property。
CREATE CONSTRAINT ON (movie:Movie) ASSERT movie.title IS UNIQUE
查看索引:
CREATE INDEX ON :Actor(name)
CREATE (actor:Actor { name:"Tom Hanks" }),(movie:Movie { title:'Sleepless IN Seattle' }), (actor)-[:ACTED_IN]->(movie);
标签:
MATCH (actor:Actor { name: "Tom Hanks" }) SET actor :American return actor;
删除标签:
MATCH (actor:Actor { name: "Tom Hanks" }) REMOVE actor:American;
官方文档手册下载地址:http://download.csdn.net/detail/wangweislk/8983743