背景:女票快毕业了(没错!我是有女票的!!!),写论文,主题是儿童性教育,查看儿童性教育绘本数据死活找不到,没办法,就去当当网查询下数据,但是数据怎么弄下来呢,首先想到用Python,但是不会!!百度一番,最终决定还是用java大法爬虫,毕竟java熟悉点,话不多说,开工!:
实现:
首先搭建框架,创建一个maven项目,使用框架是springboot和mybatis,开发工具是idea,pom.xml如下:
xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.1.4.RELEASEversion>
<relativePath/>
parent>
<groupId>cn.com.bocogroupId>
<artifactId>demoartifactId>
<version>0.0.1-SNAPSHOTversion>
<name>demoname>
<description>Demo project for Spring Bootdescription>
<properties>
<java.version>1.8java.version>
properties>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-jpaartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.mybatis.spring.bootgroupId>
<artifactId>mybatis-spring-boot-starterartifactId>
<version>2.0.1version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<scope>runtimescope>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>com.oraclegroupId>
<artifactId>ojdbc6artifactId>
<version>11.2.0version>
dependency>
<dependency>
<groupId>org.apache.httpcomponentsgroupId>
<artifactId>httpclientartifactId>
<version>4.5.5version>
dependency>
<dependency>
<groupId>org.jsoupgroupId>
<artifactId>jsoupartifactId>
<version>1.11.3version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.45version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
plugins>
build>
project>
目录结构如下:

连接的数据库是oracle本地的数据库,配置文件如下
注意:application.yml文件中
spring:
profiles:
active:dev
指定的就是application_dev.yml文件,就是配置文件用的这个,在实际开发中,可以通过这种方式配置几份配置环境,这样发布的时候切换active属性就行,不用修改配置文件了
application_dev.yml配置文件:
server:
port: 8084
spring:
datasource:
username: system
password: 123456
url: jdbc:oracle:thin:@localhost
driver-class-name: oracle.jdbc.driver.OracleDriver
mybatis:
mapper-locations: classpath*:mapping/*.xml
type-aliases-package: cn.com.boco.demo.entity
#showSql
logging:
level:
com:
example:
mapper : debug
application.yml文件:
spring:
profiles:
active: dev
启动类如下,加上MapperScan注解,扫描dao层的接口:
@MapperScan("cn.com.boco.demo.mapper")
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
dao层接口:
@Repository public interface BookMapper { void insertBatch(Listlist); }
xml文件:
xml version="1.0" encoding="UTF-8"?>
DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="cn.com.boco.demo.mapper.BookMapper">
<insert id="insertBatch" parameterType="java.util.List">
INSERT ALL
<foreach collection="list" item="item" index="index" separator=" ">
into dangdang_message (title,img,author,publish,detail,price,parentUrl,inputTime) values
(#{item.title,jdbcType=VARCHAR},
#{item.img,jdbcType=VARCHAR},
#{item.author,jdbcType=VARCHAR},
#{item.publish,jdbcType=VARCHAR},
#{item.detail,jdbcType=VARCHAR},
#{item.price,jdbcType=DOUBLE},
#{item.parentUrl,jdbcType=VARCHAR},
#{item.inputTime,jdbcType=DATE})
foreach>
select 1 from dual
insert>
mapper>
两个实体类:
public class BaseModel { private int id; private Date inputTime; public Date getInputTime() { return inputTime; } public void setInputTime(Date inputTime) { this.inputTime = inputTime; } public int getId() { return id; } public void setId(int id) { this.id = id; } }
@Alias("dangBook")
public class DangBook extends BaseModel {
//标题
private String title;
//图片地址
private String img;
//作者
private String author;
//出版社
private String publish;
//详细说明
private String detail;
//价格
private float price;
//父链接,即请求链接
private String parentUrl;
public String getParentUrl() {
return parentUrl;
}
public void setParentUrl(String parentUrl) {
this.parentUrl = parentUrl;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getPublish() {
return publish;
}
public void setPublish(String publish) {
this.publish = publish;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getImg() {
return img;
}
public void setImg(String img) {
this.img = img;
}
public String getDetail() {
return detail;
}
public void setDetail(String detail) {
this.detail = detail;
}
public float getPrice() {
return price;
}
public void setPrice(float price) {
this.price = price;
}
}
service层:
@Service public class BookService { @Autowired private BookMapper bookMapper; public void insertBatch(Listlist){ bookMapper.insertBatch(list); } }
controll层代码:
@RestController @RequestMapping("/book") public class DangdangBookController { @Autowired private BookService bookService; private static Logger logger = LoggerFactory.getLogger(DemoApplication.class); //url解码之后 private static final String URL = "http://search.dangdang.com/?key=性教育绘本&act=input&att=1000006:226&page_index="; //url解码之前 private static final String URL2 = "http://search.dangdang.com/?key=%D0%D4%BD%CC%D3%FD%BB%E6%B1%BE&act=input&att=1000006%3A226&page_index="; @RequestMapping("/parse") public JSONObject parse(){ JSONObject jsonObject = new JSONObject(); for(int i =1;i<=10;i++){ ListdangBooks = ParseUtils.dingParse(URL+i); if(dangBooks != null && dangBooks.size() >0){ logger.info("解析完数据,准备入库"); bookService.insertBatch(dangBooks); logger.info("入库完成,入库数据条数"+ dangBooks.size()); jsonObject.put("code",1); jsonObject.put("result","success"); }else{ jsonObject.put("code",0); jsonObject.put("result","fail"); } } return jsonObject; } }
本来是前端传入地址解析的,但是发现参数丢失了,用url编码也不行,最后放到后台了
ParseUtils和HttpGetUtils工具类:
public class HttpGetUtils { private static Logger logger = LoggerFactory.getLogger(HttpGetUtils.class); public static String getUrlContent(String url) { if (url == null) { logger.info("url地址为空"); return null; } logger.info("url为:" + url); logger.info("开始解析"); String contentLine = null; //最新版httpclient.jar已经舍弃new DefaultHttpClient() //但是还是可以用的 HttpClient httpClient = new DefaultHttpClient(); HttpResponse httpResponse = getResp(httpClient, url); if (httpResponse.getStatusLine().getStatusCode() == 200) { try { contentLine = EntityUtils.toString(httpResponse.getEntity(), "utf-8"); } catch (IOException e) { e.printStackTrace(); } } logger.info("解析结束"); return contentLine; } /** * 根据url 获取response对象 */ public static HttpResponse getResp(HttpClient httpClient, String url) { logger.info("开始获取response对象"); HttpGet httpGet = new HttpGet(url); HttpResponse httpResponse = new BasicHttpResponse(HttpVersion.HTTP_1_1, HttpStatus.SC_OK, "OK"); try { httpResponse = httpClient.execute(httpGet); } catch (IOException e) { e.printStackTrace(); } logger.info("获取对象结束"); return httpResponse; } }
public class ParseUtils { private static Logger logger = LoggerFactory.getLogger(ParseUtils.class); public static ListdingParse(String url) { List list = new ArrayList<>(); Date date = new Date(); if (url == null) { logger.info("url为空,数据获取结束"); return null; } logger.info("开始获取数据"); String content = HttpGetUtils.getUrlContent(url); if (content != null) logger.info("得到解析数据"); else { logger.info("解析数据为空,数据获取结束"); return null; } Document document = Jsoup.parse(content); //遍历当当图书列表 for(int i =1;i<=60;i++){ Elements elements = document.select("ul[class=bigimg]").select("li[class=line"+i+"]"); for (Element e : elements) { String title = e.select("p[class=name]").select("a").text(); logger.info("书名:" + title); String img = e.select("a[class=pic]").select("img").attr("data-original"); logger.info("图片地址:" + img); String authorAndPublish = e.select("p[class=search_book_author]").select("span").select("a").text(); String []a = authorAndPublish.split(" "); String author = a[0]; logger.info("作者:" + author); String publish = a[a.length - 1]; logger.info("出版社:" + publish); // String publish =e.select("p[class=name]").select("a").text(); String detail = e.select("p[class=detail]").text(); logger.info("图书介绍:" + detail); String priceS = e.select("p[class=price]").select("span[class=search_now_price]").text(); float price = 0.0f; if(priceS.length()>1 && priceS != null){ price = Float.parseFloat(priceS.substring(1, priceS.length() - 1)); } logger.info("价格:" + price); logger.info("-------------------------------------------------------------------------"); DangBook dangBook = new DangBook(); dangBook.setTitle(title); dangBook.setImg(img); dangBook.setAuthor(author); dangBook.setPublish(publish); dangBook.setDetail(detail); dangBook.setPrice(price); dangBook.setParentUrl(url); dangBook.setInputTime(date); list.add(dangBook); } } return list; } }
最后表里数据如下:
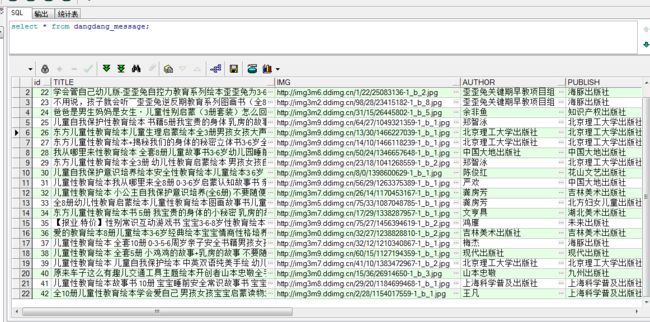
注意:建表的时候注意字段类型,orcale的var(255)不够我的这个数据标题用,开始报错,后来改了字段类型,还有注意ID的自增和入库时间的自动添加,个人数据库较差,百度一番才弄好