《Google软件测试之道》—第2章2.1节SET的工作
本节书摘来自异步社区《Google软件测试之道》一书中的第2章2.1节SET的工作,作者【美】James Whittaker , Jason Arbon , Jeff Carollo,更多章节内容可以访问云栖社区“异步社区”公众号查看。
第2章 软件测试开发工程师
Google软件测试之道
C:Documents and SettingsAdministrator桌面页面提取自- 9780321803023_book.jpg
在理想情况下,一个完美的开发过程是怎样进行的呢?测试先行,在一行代码都没有真正编写之前,一个开发人员就会去思考如何测试他即将编写的代码。他会设计一些边界场景的测试用例,数据取值范围从极大到极小、导致循环语句超出限制范围的情况,另外还会考虑很多其他的极端情况。这些测试代码会作为产品代码的一部分,以自检代码或单元测试代码的形式与功能代码存储在一起。对于此种类型的测试,最合适且最有资格去做的人,其实就是编写功能代码的人。
另外一些测试需要的知识在本产品代码之外,通常都依赖于外部基础设施服务。例如,一个测试用例需要从远程数据源(一个数据库或者云端)读取数据,这就需要存在一个真实数据库或模拟的数据库。在过去几年中,工业界使用了各种特定术语来描述这些辅助设施,包括测试框架、测试通用设施、模拟设施和虚拟设施(译注:test harnesses, test infrastructure, mock and fake)。在假想的完美开发过程中,在你做功能测试时,如果需要,这些工具都应该及时出现在你眼前,任由你使用(记住,这是在一个真正理想的软件世界里)。
在理想开发过程中首次需要测试人员的时刻即将来临。对于人的思维方式而言,在编写功能代码的时候与编写测试代码的时候是迥然不同的,这也就需要去区分功能开发人员和测试开发人员(译注:原文是feature developer and test developer)。对于功能代码而言,思维模式是创建,重点在考虑用户、使用场景和数据流程上;而对于测试代码来说,主要思路是去破坏,怎样写测试代码用以扰乱分离用户及其数据。由于我们假设的前提是在一个童话般的理想开发过程里,所以我们或许可以分别雇佣不同的开发工程师:一个写功能代码,而另一个思考如何破坏这些功能(译注:两种开发工程师,分别是功能开发人员和测试开发人员)。
注意
编写功能代码和编写测试代码在思维方式上有着很大的不同。
在这样乌托邦式(译注:乌托邦是一个理想的群体和社会的构想,名字由托马斯·摩尔的《乌托邦》一书中所写的完全理性的共和国“乌托邦”而来,意指理想完美的境界)的理想开发过程中,众多的功能开发人员(译注:feature developer)和测试开发人员(译注:test developer)需要通力合作,共同为打造同一款产品而努力。在我们假想的完美理想情况下,产品的每一个功能都对应一个开发人员,整个产品则配备一定数量的测试开发人员。测试开发人员通过使用测试工具与框架帮助功能开发人员解决特定的单元测试问题,而这些问题如果只是由功能开发人员独自完成,则会消耗掉他们许多的精力。
功能开发人员在编写功能代码的时候,测试开发人员编写测试代码,但我们还需要第三种角色,一个关心真正用户的角色。显然在我们理想化的乌托邦测试世界里,这个工作应该由第三种工程师来完成,既不是功能开发人员,也不是测试开发人员。我们把这个新角色称为用户开发人员(译注:user developer)。他们需要解决的主要问题是面向用户的任务,包括用例(use case)、用户故事、用户场景、探索式测试等。用户开发人员关心这些功能模块如何集成在一起成为一个完整的整体,他们主要考虑系统级别的问题,通常情况下都会从用户角度出发,验证独立模块集成在一起之后是否对最终用户产生价值。
这就是我们眼中软件开发过程的乌托邦理想模式,三种开发角色在可用性和可靠性方面分工合作,达到完美。每个角色专门处理重要的事情,相互之间又可以平等地合作。
谁不想为这样的软件开发公司工作呢?大家全都要报名应聘!
但不幸的是,这样的公司目前还不存在,Google也只是比较接近而已。Google与其他公司一样,都在尽力去尝试成为这样的公司。或许是因为Google起步较晚,我们有机会从前人那里吸取了很多经验教训。当前软件正经历一个巨大的转变,从发布周期需要以年为单位的客户端模式向每周、每天,甚至每小时都会发布的云端模式转变(注:一个有趣的事情需要说明一下,即使是客户端软件,Google也喜欢常去更新,客户端使用一个“自动更新”的功能,几乎所有的客户端应用都有这个功能),而Google也从这次转换浪潮之中受益良多。在这两种原因的促进下,Google的软件开发流程与乌托邦模式也有了几分相似。
Google的SWE就是功能开发人员,负责客户使用的功能模块开发。他们编写功能代码及这些功能的单元测试代码。
Google的SET就是测试开发人员,部分职责是在单元测试方面给予开发人员支持,另外一部分职责是为开发人员提供测试框架,以方便他们编写中小型测试,用以进行更多质量相关的测试工作。
Google的TE就是用户开发人员,负责从用户的角度来思考质量方面各种问题。从开发的角度来看,他们编写用户使用场景方面的自动化用例代码;从产品的角度看,他们评估整体测试覆盖度,并验证其他工程师角色在测试方面合作的有效性。这不是乌托邦,这就是Google实践之路上最好的尝试,前进的道路上充满了不可预料且无路可退。
注意
Google的SWE是功能开发人员;Google的SET是测试开发人员;Google的TE是用户开发人员。
在这本书里,我们将会着重介绍SET和TE这两个角色的工作内容,也会包含少量SWE的工作内容,作为上述两种角色的补充。虽然SWE也重度参与测试工作,但一般情况下都是在头衔中包含“测试”的工程师的指导之下完成的。
2.1 SET的工作
在任何软件公司创立的初期阶段,通常都没有专职的测试人员(译注:本节标题“SET的工作”,因为原文为The Life of an SET。“The Life of ”是Google内部系列课程(搜索和广告是如何工作的)中使用的特定术语。针对Nooglers(新Google员工)的课程里,Life of a Query揭秘搜索query是如何实现的,Life of a Dollar揭秘广告系统的工作原理)。当然那时候也没有产品经理、计划人员、发布工程师、系统管理员等其他角色。每位员工都独自完成所有工作。我们也经常想象Larry和Sergey(译注:Google的早期创始人之一)在早期是如何思考用户使用场景和设计单元测试的样子。随着Google的不断成长壮大,出现了第一个融合开发角色和质量意识于一身的角色,即SET(注:Patrick Copeland在本书的序中已经介绍了SET的出现背景)。
2.1.1 开发和测试流程
在详细讲解SET工作流程之前,我们先来了解一下SET的工作背景,这对理解整个开发过程将十分有益。在新产品的开发过程中,SET和SWE是紧密合作的伙伴,他们达成一致,甚至一些实际工作也会有所重叠。Google其实就是这样设计的,Google认为测试工作是由整个工程团队负责,而不仅仅单独由那些头衔上带着“测试”的工程师来负责。
工程师团队的交付物就是即将发布的代码。代码的组织形式、开发过程、维护是日常工作重点。Google多数代码存放在同一个代码库中,并使用统一的一套工具。这些工具和代码支撑着Google的构建和发布流程。Google所有的工程师无论是什么角色,对如何使用这些工具环境都非常地熟练,团队成员可以毫不费力地完成新代码的入库、提交、执行测试、创建版本等任务(前提是角色有这样的需求)。
注意
工程师团队的交付物就是即将要发布的代码。代码的组织形式、开发过程、维护是日常的工作重点。
这种单一的代码库模式,使得工程师可以很从容地在不同项目之间转换而几乎不需要什么学习成本。这为工程师提供了很大便利,这种单一的代码库模式让工程师从他们进入项目开始的第一天起,其“百分之二十的贡献”(译注:“百分之二十时间”是指Googler称为的“业余项目”。这并不是一个炒作的概念,而是官方真正存在的,允许所有Googler每周投入一天时间在他的日常工作之外的项目上。每周四天工作用来赚取薪水,剩下一天用以试验和创新。这并不是完全强制的,之前有些Googler认为这个想法只是一个传说。根据我们的真实经历,这个概念是真正存在的,我们三个都参与过“百分之二十时间”项目。实际上,本书提及的许多工具都是“百分之二十”项目的结晶。在现实中,许多Goolers选择把“百分之二十时间”投入到新产品之中,特别是一些听起来很酷的产品,很享受这种工作模式)极具效率。这也意味着对于有需求的工程师,所有的源代码对他们都是开放的。Web 应用的开发人员无须申请任何权限,就能查看所有可以简化他们工作的浏览器端代码。他们从有经验的工程师那里学习到在类似场景下如何编写代码,他们可以重用一些通用模块或详细的数据结构,甚至是重用一些程序控制结构。Google在代码库搜索方面也提供了非常便利的功能。
公开的代码库、和谐的工程工具、公司范围内的资源共享,成就了丰富的Google内部共享代码库与公共服务。这些共享的代码运行依赖于Google的基础设施产品,它们在加速项目完成与减少项目失败上发挥了很大作用。
注意
公开的代码库、和谐的工程工具、公司范围内的资源共享,成就了丰富的Google内部共享代码库与公共服务。
工程师们对这些共享的基础代码做了特殊处理,形成了一套不成文但却非常重要的实践规则,工程师在维护修改这些代码的时候都要遵守这些规则。
所有的工程师必须复用已经存在的公共库,除非在项目特定需求方面有很好的理由。
对于公共的共享代码,首先要考虑的是能否可以容易地被找到,并具有良好的可读性。代码必须存储在代码库的共享区域,以便查找。由于共享代码会被不同的工程师使用,这些代码应该容易理解。所有的代码都要考虑到未来会被其他人阅读或修改。
公共代码必须尽可能地被复用且相对独立。如果一个工程师提供的服务被许多团队使用,这将为他带来很高的信誉。与功能的复杂性或设计的巧妙性相比,可复用性带来的价值更大。
所有依赖必须明确指出,不可被忽视。如果一个项目依赖一些公用共享代码,在项目工程师不知情的前提下,这些共享代码是不允许被修改的。
如果一个工程师对共享代码库在某些地方有更好的解决方案,他需要去重构已有的代码,并协助依赖在这个公用代码库之上的应用项目迁移到新的代码库上。这种乐善好施的社区工作是值得鼓励的(译注:这是Google经常提及的“同僚奖金(peer bonus)”。任何工程师如果受到其他工程师正面的影响,就可以送出“同僚奖金”作为感谢。除此之外,经理还有权使用其他奖励手段。这样做的目的就是让这种正向团队合作形成一种良性循环,并持续下去。当然,另外还有同事之间私下里的感谢)。
Google非常重视代码审核,特别是公共通用模块的代码必须经过审核。开发人员必须通过相关语言的可读性审核。在开发人员拥有按照代码风格编写出干净代码的记录之后,委员会会授予这名开发人员一个“良好可读性”的证书。Google的四大主要开发语言:C++、Java、Python和JavaScript都有可读性方面的代码风格指南。
在共享代码库里的代码,对测试有更高的要求(在后面部分会做讨论)。
最小化对平台的依赖。所有工程师都有一台桌面工作机器,且操作系统都尽可能地与Google生产环境的操作系统保持一致。为了减少对平台的依赖,Google对Linux发行版本的管理也十分谨慎,这样开发人员在自己工作机器上测试的结果,与生产系统里的测试结果会保持一致。从桌面到数据中心,CPU和OS的变化尽可能小(注:唯一不在Google通用测试平台里的本地测试实验室,是Android和Chrome OS。这些类目不同的硬件必须在手边进行测试)如果一个bug在测试机器上出现,那么在开发机器上和生产环境的机器上也都应该能够复现。
所有对平台有依赖的代码,都会强制要求使用公共的底层库。维护Linux发行版本的团队同时也在维护这个底层平台相关的公共库。还有一点,对于Google使用的每个编程语言,都要求使用统一的编译器,这个编译器被很好地维护着,针对不同的Linux发行版本都会有持续的测试。这样做本身其实并没有什么神奇之处,但限制运行环境可以节省大量下游的测试工作,也可以避免许多与环境相关且难以调试的问题,能把开发人员的重心转移到新功能开发上。保持简单,也就相对会安全。
注意
Google在平台方面有特定的目标,就是保持简单且统一。开发工作机和生产环境的机器都保持统一的Linux发行版本;一套集中控制的通用核心库;一套统一的通用代码、构建和测试基础设施;每个核心语言只有一个编译器;与语言无关的通用打包规范;文化上对这些共享资源的维护表示尊重且有 激励。
使用统一的运行平台和相同的代码库,持续不断地在构建系统中打包(译注:打包是一个过程,包括将源代码编译成二进制文件,然后再把二进制文件统一封装在一个linux rpm包里面),这可以简化共享代码的维护工作。构建系统要求使用统一的打包规范,这个打包规范与项目特定的编程语言无关,与团队是否使用C++、Python或Java也都无关。大家使用同样的“构建文件”来打包生成二进制文件。
一个版本在构建的时候需要指定构建目标,这个构建目标(可以是公共库、二进制文件或测试套件)由许多源文件编译链接产生。下面是整体流程。
(1)针对某个服务,在一个或多个源代码文件中编写一类或一系列功能函数,并保证所有代码可以编译通过。
(2)把这个新服务的构建目标设定为公共库。
(3)通过调用这个库的方式编写一套单元测试用例,把外部重要依赖通过mock模拟实现。对于需要关注的代码路径,使用最常见的输入参数来验证。
(4)为单元测试创建一个测试构建目标。
(5)构建并运行测试目标,做适当的修改调整,直到所有的测试都运行成功。
(6)按要求运行静态代码分析工具,确保遵守统一的代码风格,且通过一系列常见问题的静态扫描检测。
(7)提交代码申请代码审核(后面对代码审核会做更多详细说明),根据反馈再做适当的修改,然后运行所有的单元测试并保证顺利通过。
产出将是两个配套的构建目标:库构建目标和测试构建目标。库构建目标是需要新发布的公共库、测试构建目标用以验证新发布的公共库是否满足需求。注意:在Google许多开发人员使用“测试驱动开发”的模式,这意味着步骤(3)会在步骤(1)和步骤(2)之前进行。
对于规模更大的服务,通过链接编译持续新增的代码,构建目标也会逐渐变大,直到整个服务全部构建完成。在这个时候,会产生二进制构建目标,其由包含主入口main函数文件和服务库链接在一起构成。现在,你完成了一个Google产品,它由三部分组成:一个经过良好测试的独立库、一个在可读性与可复用性方面都不错的公共服务库(这个服务库中还包含另外一套支持库,可以用来创建其他的服务)、一套覆盖所有重要构建目标的单元测试套件。
一个典型的Google产品由许多服务组成,所有产品团队都希望一个SWE负责对应一个服务。这意味着每个服务都可以并行地构建、打包和测试,一旦所有的服务都完成了,他们会在一个最终的构建目标里一起集成。为了保证单独的服务可以并行地开发,服务之间的接口需要在项目的早期就确定下来。这样,开发者会依赖在协商好的接口上,而不是依赖在需要开发的特定库上。为了不耽搁服务级别之间的早期测试,这些接口一般都不会真正实现,而只是做一个虚假的实现。
SET会参与到许多测试目标的构建之中,并指出哪些地方需要小型测试。在多个构建目标集成在一起,形成规模更大应用程序的构建目标时,SET需要加速他们的工作,开始做一些更大规模的集成测试。在一个单独的库构建目标中,需要运行几乎所有的小型测试(由SWE编写,所有支持这个项目的SET都会给予帮助)。当构建目标日益增大时,SET也会参与到中大型测试的编写之中去。
在构建目标的增长到一定规模时,针对功能集成的小型测试会成为回归测试的一部分。如果一个测试用例,本应该运行通过,但如果运行失败,也会报一个测试用例的bug。这个针对测试用例的bug和针对功能的bug没有任何区别。测试就是功能的一部分,问题较多的测试就是功能性bug,一定要得到修复。这样才可以保证新增的功能不会把已有功能损坏掉,任何代码的修改都不会导致测试本身的失败。
在所有的这些活动中,SET始终是核心参与者。他们在开发人员不知道哪些地方需要单元测试的时候可以明确指出。他们同时编写许多mock和fake工具。他们甚至编写中大型集成测试。好了,现在是展开讨论SET工作的时候了。
2.1.2 SET究竟是谁
SET首先是工程师角色,他使得测试存活于先前讨论的所有Google开发过程之中。SET(software engineer in test)是软件测试开发工程师。最重要的一点,SET是软件工程师,正如我们招聘宣传海报和内部晋升体系中所说的那样,是一个100%的编码角色。这种测试方式的有趣之处在于它使测试人员能尽早介入到开发流程中去,但不是通过“质量模型”和“测试计划”的方式,而是通过参与设计和代码开发的方式。这会使得功能的开发工程师和测试的开发工程师处于相同的地位,SET积极参与各种测试,使测试富有效率,包括手动测试和探索式测试,而这些测试后期会由其他工程师负责。
注意
测试是应用产品的另外一种功能,而SET就是这个功能的负责人。
SET与功能开发人员坐在一起(实际上,让他们物理位置坐在一起是也是我们的设计目标)。这样讲可能更公平一些,测试也是应用产品的一种功能特性,而SET是这个产品功能特性的负责人。SET参与SWE的代码评审,反之亦然。
在面试SET的时候,在代码要求标准上与SWE的招聘要求是一样的,而且增加了一个额外考核——SET需要了解如何去测试他们编写的代码。换句话说,SWE和SET都需要回答代码问题,而且SET还要求去解答测试问题。
正如你想象的那样,找到满足如此条件的人是非常困难的,在Google,SET的数量也相对比较少,这并不是因为Google在生产率方面有什么神奇的开发测试比要求,而是因为招聘到满足SET技能要求的人实在太难了。SWE和SET这两个角色比较相似,在招聘方面这两个群体的要求也类似。假想这样的场景,公司里的开发人员可以做测试,而测试人员可以写代码。Google其实还没有完全做到这一点,或许永远也做不到。这两大群体之间相互交流学习,SWE向SET学习,SET也在学习SWE,正是我们这些最优秀的工程师一起构成了我们最有效率的工程产品团队。
2.1.3 项目的早期阶段
Google没有规定SET何时进入项目,同样也没有规定怎样的项目才算是“真正”的项目。通常情况下,在Google的产品项目初期阶段,工程师只会投入20%的时间。Gmail和Chrome OS也是从一个想法演变而来,初期也并没有任何Google官方资源的投入,这些资源来源于团队开发测试成员的业余时间。事实上也正如我们的朋友Alberto Savoia(本书的序言的作者之一,详细介绍参见序部分)所说的那样,“只有在软件产品变的重要的时候质量才显得重要”。
许多创新的产品都是来源于团队20%的业余时间。这些时间投入的产品有些慢慢地消失了,而另外一些规模会越做越大,有的甚至会成为Google的官方产品。在这些产品的初期,没有一个会得到测试资源。在未来可能失败的项目中投入测试资源来构建测试方面基础设施,这是一种资源浪费。如果项目被取消了,那么这些创建好的测试也会毫无价值。
一个产品如果在概念上还没有完全确定成型时就去关心质量,这就是优先级混乱的表现。许多来源于Google百分之二十努力的产品原型,在其以后的dogfood或beta版本发布时,还要经历重新设计,原始代码保留的概率几乎为零。很明显,在试验初期阶段强调测试是一件非常愚蠢的事情。
当然,物极必反,风险总是相对的。如果一个产品太长时间没有测试的介入,早期在可测试性上的槽糕设计在后期也很难去做改进,这样会导致自动化难以实施且测试工具极不稳定。在这种情况下,不得不以质量的名义来做重构。这样的质量“债”会拖慢产品的发布,甚至长达数年之久。
在项目早期,Google一般不会让测试介入进来。实际上,即使SET在早期参与进来,也不是从事测试工作,而是去做开发。绝非有意忽视测试,当然也不是说早期产品的质量就不重要。这是受Google非正式创新驱动产品的流程所约束。Google很少在项目创建初期就投入一大帮人来做计划(包括质量与测试计划),然后再让一大群开发参与进来。Google项目的诞生从来没有如此正式过。
Chrome OS是一个可以说明问题的典型例子。本书的三个作者都在这个产品上工作过一年以上。但是,在我们正式加入之前,只有几个开发人员做了原型,且多数实现都是脚本与伪件(fake),这样他们可以拿着浏览器应用模型做演示,并通过正式的立项批准。在这些早期原型阶段,主要精力都集中在如何试验并证明这些想法的可行性上。考虑到项目还没有正式批准,且所有的演示脚本最终都会被C++代码重写替换,如果在早期投入大量测试和可测试性方面努力,其实没有太大的实用价值。为了演示而使用脚本搭建的产品,一旦得到正式批准立项,其开发总监就会找到工程生产力团队,寻求测试资源。
Google内部其实也并存着不同的文化。没有项目会认为如果得不到测试资源,他们的产品就将不复存在。开发团队在寻求测试帮助的时候,有义务让测试人员相信他们的产品是令人兴奋且并充满希望的。在Chrome OS的开发总监给我们介绍他们项目、进度和发布计划时,我们也要求提供当前已有的测试状态、期望的单元测试覆盖率水平、以及明确在发布过程中各自承担的责任。在项目还是概念阶段的时候,测试人员不会参与进来,而项目一旦真正立项,我们就要在这些测试是如何执行的方面发挥我们的影响力。
注意
没有项目会认为如果得不到测试资源,他们的产品就将不复存在。开发团队在寻求测试帮助的时候,有义务让测试人员相信他们的产品是令人兴奋且并充满希望的。
2.1.4 团队结构
SWE会深入他们自己编写的那部分代码之中,通常这部分代码只是某个单一功能的模块甚至更小范围的代码。SWE一般仅在自己的模块领域里提供最优方案,但如果从整个产品的角度来看,视野会显得略微狭窄。一个好的SET正好可以弥补这一点,不仅要具有更宽广的整体产品视野,而且在产品的整个生命周期里对产品及功能特性做充分理解,许多SWE来往穿梭于不同产品,但产品的生命存活期比SWE待在产品里的时间要长久得多。
像Gmail或Chrome这样的产品注定要经历许多版本,并消耗数以百计的开发人员为之工作。如果一个SWE在某个产品的第三个版本研发时加入,这时这个产品已经有良好的文档、不错的可测试性、运行着稳定的自动化测试、清晰的代码提交流程,这些现象都在说明这个产品早期已有出色的SET在为之工作。
在整个项目生命周期里,功能的实现、版本的发布、补丁的创建、为改进而做的重构在不断地发生,你很难说清楚什么时候项目结束或一个项目是否真的已经结束。但所有软件项目都有明确的开始时间。在早期阶段,我们常去改变我们的目标。我们做计划,并尝试把东西做出来。我们尝试去文档化我们将要去做的事情。我们尝试去保证我们早期做的决定长期看来也是正确的。
我们在编码之前做计划、试验、文档,这部分工作量取决于我们对未来产品的信心。我们不想在项目初期做少量的计划,而到项目后期却发现这个计划是值得花费更多精力去做的。同样,我们也不希望在早期计划上投入数周时间,而之后却发现这个世界已经改变了,甚至与之前我们想象的世界完全不同了。某种程度上来说,我们早期在文档结构和过程中的处理方式也是明智的。总而言之,做多少和怎样做比较合适,由创建项目的工程师来做最终决定。
Google产品团队最初是由一个技术负责人(tech lead)和一个或更多的项目发起人组成。在Google,技术负责人这个非正式的岗位一般由工程师担任,负责设定技术方向、开展合作、充当与其他团队沟通的项目接口人。他知道关于项目的任何问题,或者能够指出谁知道这些问题的细节。技术负责人通常是一名SWE,或者由一名具备SWE能力的工程师来担任。
项目的技术负责人和发起人要做的第一件事就是设计文档(后文会做介绍)。随着文档的不断完善,就需要不同专业类型的工程师角色投入到项目中去。许多技术负责人期望SET在早期就能参与项目,即便那时SET资源还相对稀缺。
2.1.5 设计文档
所有Google项目都有设计文档。这是一个动态的文档,随着项目的演化也在不断地保持更新。最早期的项目设计文档,主要包括项目的目标、背景、团队成员、系统设计。在初期阶段,团队成员一起协同完成设计文档的不同部分。对于一些规模足够大的项目来说,需要针对主要子系统也创建相应的设计文档,并在项目设计文档中增加子系统设计文档的链接。在初期版本完成后,里面会囊括所有将来需要完成的工作清单,这也可以作为项目前进的路标。从这一点上讲,设计文档必须要经过相关技术负责人的审核。在项目设计文档得到足够的评审与反馈之后,初期版本的设计文档就接近尾声了,接下来项目就正式进入实施阶段。
作为SET,比较幸运的是在初期阶段就加入了项目,会有一些重要且有影响力的工作急需完成。如果能够合理地谋划策略,我们在加速项目进度的同时,也可以做到简化项目相关人员的工作。实际上,作为工程师,SET在团队中有一个巨大的优势,就是拥有产品方面最广阔的视野。一个好的SET会把非常专业的广阔视野转化成影响力,在开发人员所编写的代码上产生深远的影响力。通常来说,代码复用和模块交互方面的设计会由SET来做,而不是SWE。后面会着重介绍SET在项目的初期阶段是如何发挥作用的。
注意
在设计阶段,SET在推进项目的同时也可以简化相关项目成员的工作。
如果有另外一双眼睛来帮助审核你的工作,这是无疑会很有帮助且令人期待。SWE就渴望得到来自SET的这种帮助与反馈。在SWE完成设计文档的各个部分之后,需要发送给更大范围人去做正式审核,在这之前他们希望得到SET的帮助。一个优秀的SET对这样的文档审核也会比较期待,乐意去投入他的时间,在SET审阅过程中,会针对质量和可靠性方面增加一些必要的内容。下面是我们为什么这么做的几个原因。
SET需要熟悉了解所负责的系统设计(阅读所有的设计文档是一个途径),SET和SWE都期望如此。
SET早期提出的建议会反馈在文档和代码里,这样也增加了SET的整体影响力。
作为第一个审阅所有设计文档的人(也因此了解所有迭代过程),SET对项目的整体了解程度超过了技术负责人。
对于SET来说,这也是一个非常好的机会,可以在项目初期就与相应开发工程师一起建立良好的工作关系。
审阅设计文档的时候应该有一定的目的性,而不是像读报纸那样随便看两眼就算了。优秀的SET在审阅过程中始终保持强烈的目的性。下面是一些我们推荐的一些要点。
完整性:找出文档中残缺不全或一些需要特殊背景知识的地方。通常情况下团队里没人会了解这些知识,特别是对新人而言。鼓励文档作者在这方面添加更多细节,或增加一些外部文档链接,用以补充这部分背景知识。
正确性:看一下是否有语法、拼写、标点符号等方面的错误,这一般是马虎大意造成的,并不意味着他们以后编写的代码也是这样。但也不能为这种错误而破坏规矩。
一致性:确保配图和文字描述一致。确保文档中没有出现与其他文档中截然相反的观点和主张。
设计:文档中的一些设计要经过深思熟虑。考虑到可用的资源,目标是否可以顺利达成?要使用何种基础的技术框架(读一读框架文档并了解他们的不足)?期望的设计在框架方面使用方法上是否正确?设计是否太过复杂?有可能简化吗?还是太简单了?这个设计还需要增加什么内容?
接口与协议:文档中是否对所使用的协议有清晰的定义?是否完整地描述了产品对外的接口与协议?这些接口协议的实现是否与他们期望的那样一致?对于其他的Google产品是否满足统一的标准?是否鼓励开发人员自定义Protocol buffer数据格式(后面会讨论Protocol buffer)?
测试:系统或文档中描述的整套系统的可测试性怎样?是否需要新增测试钩子(译注:testing hook,这里指为了测试而增加一些接口,用以显示系统内部状态信息)?如果需要,确保他们也被添加到文档之中。系统的设计是否考虑到易测试性,而为之也做了一些调整?是否可以使用已有的测试框架?预估一下在测试方面我们都需要做哪些工作,并把这部分内容也增加到设计文档中去。
注意
审阅设计文档的时候要,具备一定的目的性,需要完成特定的目标,而不是像读报纸那样随意看两眼。
在SET与相应的SWE一起沟通文档的审阅结果时,关于测试的工作量以及各个角色之间如何共同参与测试,会有一个比较正式的讨论。这是一个绝佳的时机,可以了解到开发在单元测试方面的目标,以及如果想打造一款经过良好测试的产品,团队成员需要遵守哪些最佳实践。当这种讨论以互帮互助的形式开始出现时,我们的工作就开始逐步进入正轨了。
2.1.6 接口与协议
在Google,由于接口协议与编写代码相关,所以对于开发人员来说,文档化这部分是比较轻松的事情。Google protocol buffer语言(注:Google protocol buffers 是开源的,参见http://code.google.com/apis/protocolbuffers)与编码语言和平台无关,对结构化数据而言具有可扩展性,就像XML一样,但更小、更快、更简单。开发人员使用protocol buffer的描述语言来定义数据结构,然后使用自动生成的源代码,从各种数据流中来读或写这些结构化的数据,使用任何编程语言(Java, C++或python)皆可。对于新项目而言,protocol buffer源码通常是第一份源代码。在系统实现之后,如果设计文档中仍然使用protocol buffers来描述系统是如何工作的,这比较罕见。
SET会对protocol buffer代码做比较系统全面的审查,因为protocol buffer定义的接口与协议的代码实现是要由SET来完成的。没错,SET是第一个实现所有接口和协议的人。在系统真正搭建起来之前,集成测试的运行依赖这些接口实现。为了能够尽早地开始做集成测试,SET针对各个模块的依赖提供了mock或fake的实现。虽然功能模块代码还没有实现,集成测试的代码就已经可以开始编写了。在这个时候,如果集成测试代码可以运行起来,那将会更有价值。另外,在任何阶段,集成测试总是依赖mock和fake。因为有了它们,一些依赖服务的期望错误场景和条件异常,会比较容易产生。
注意
为了能够尽早可以运行集成测试,针对依赖服务,SET提供了mock与fake。
2.1.7 自动化计划
SET时间有限且需要做的事情太多,尽早地提供一个可实施的自动化测试计划是一个很好的解决方法。试图在一个测试套件中自动化所有端到端的测试用例,这是一个常见的错误。没有SWE会被这样一个无所不包的设计所吸引并感兴趣,SET也就得不到SWE的什么帮助。如果SET希望能从SWE那里得到帮忙,他的自动化计划就必须合情合理且有影响力。自动化上投入的越多,维护的成本也就越大。在系统升级变化时,自动化也会更加不稳定。规模更小且目的性更强的自动化计划,并存在可以提供帮助的测试框架,这些会吸引SWE一起参与测试。
在端到端的自动化测试上过度投入,常常会把你与产品的特定功能设计绑定在一起,这部分测试在整个产品稳定之前都不会特别有用。在产品完成之后,这个时候如果去修改设计就已经太晚了。所以,这个时刻从测试中得到的任何反馈也将变得毫无意义。SET的时间,本应投入在提高质量方面,却白白地花费在维护这些不稳定的端到端测试套件上。
注意
在端到端自动化测试上过度投入,常常会把你与产品的特定功能设计绑定在一起。
在Google,SET遵循了下面的方法。
我们首先把容易出错的接口做隔离,并针对它们创建mock和fake(在之前的章节中做过介绍),这样我们可以控制这些接口之间的交互,确保良好的测试覆盖率。
接下来构建一个轻量级的自动化框架,控制mock系统的创建和执行。这样的话,写代码的SWE可以使用这些mock接口来做一个私有构建。在他们把修改的代码提交到代码服务器之前运行相应的自动化测试,可以确保只有经过良好测试的代码才能被提交到代码库中。这是自动化测试擅长的地方,保证生态系统远离糟糕代码,并确保代码库永远处于一个时刻干净的状态。
SET除了在这个计划中涵盖自动化(mock、fake和框架)之外,还要包括如何公开产品质量方面的信息给所有关心的人。在Google,SET使用报表和仪表盘(译注:dashboard)来展示收集到的测试结果以及测试进度。通过将整个过程简化和信息公开透明化,获取高质量代码的概率会大大增加。
2.1.8 可测试性
在产品开发过程中,SWE和SET紧密地工作在一起。SWE编写产品代码并测试这些代码。SET编写测试框架,为SWE编写测试代码方面提供帮助。另外,SET也做一些维护工作。质量责任由SWE和SET共同承担。
SET的第一要务就是可测试性。SET在扮演一个质量顾问的角色,提供程序结构和代码风格方面的建议给开发人员,这样开发人员可以更好地做单元测试。同时提供测试框架方面的建议,使得开发人员能够在这些框架的基础上自己写测试。后面我们再讨论框架,在这里让我们首先说一下Google的代码流程。
作为开发人员,一个基本的要求就是有能力做代码审查。代码审查需要工具和文化方面的支持,这个文化习俗来源于开源社区中“提交者”的概念,只有被证明是值得信赖的开发者之后,才具有往代码库中提交代码的资格。
注意
为了使SET也成为源码的拥有者之一,Google把代码审查作为开发流程的中心。相比较编写代码而言,代码审查更值得炫耀。
在Google,每个人都是代码提交者。但是,我们使用了另外一个词“可读性”来区分有已被证明有资格的提交者和新开发人员。下面介绍整个流程如何工作的。
代码以一个被称为“变更列表”(译注:change list,下文简写CL)的单元被编写和封装起来。CL在编码结束之后会提交审查,其中使用一个Google内部工具Mondrian(以一个荷兰抽象派画家为名)。Mondrian会把需要审查的代码发送给具有审阅资格的SWE或SET,并最终通过代码审查(译注:在Google App Engine上运行着一个开源版本的Mondrian,参见http://code.google.com/p/rietveld/)。
CL可以是一段新代码,也可以是对已有代码的修改,或是缺陷修复等。CL代码的大小从几行到几百行不等,一般审查者都会要求把数量较大的CL分解成数量较小的几个CL。新加入Google的SWE和SET都需要通过持续提交优秀的CL,来获取一个“可读性”方面的代码审查资格。可读性与编程语言有关,Google内部主要的编程语言C++、Java、Python和JavaScript都有不同的可读性要求。有经验和值得信赖的开发人员,会得到“可读性”的资格,大家同心协力确保整个代码库看起来像是由一个人编写的一样(注:Google的C++代码风格指南是对外公开的,参见http://google-styleguide.googlecode.com/svn/trunk/cppguide.xml)。
在CL提交审查之前,会经过一系列的自动化检查。这种自动化静态检查所使用的规则包含一些简单的确认,例如是否遵循Google的代码风格指南、提交CL相关的测试用例是否执行通过(原则上所有的测试必须全部通过)等。CL里面一般总是包含针对这个CL的测试代码,测试代码总是和功能代码在一起。在检查完成之后,Mondrian会给相应的CL审阅者发送一封包含这个CL链接的通知邮件。随后审阅者会进行代码审查,并把修改建议发回给SWE去处理。这个过程会反复进行,直到提交者和审阅者都满意为止。
提交队列(译注:submit queue)的主要功能是保持“绿色”的构建,这意味着所有测试必须全部通过。这是构建系统和版本控制系统之间的最后一道防线。通过在干净环境中编译代码并运行测试,提交队列系统可以捕获在开发机器上无法发现的环境错误,但这会导致构建失败,甚至是导致版本控制系统中的代码处于不可编译的状态。
规模较大的团队可以利用提交队列在同一个代码分支上进行开发。如果没有提交队列,通常在代码集成或每轮测试时都会把代码冻结,使用提交队列就可以避免这个问题。在这种模式下,提交队列可以使得规模较大团队就像小团队一样,高效且独立。由于这样增加了开发提交代码的频率,势必给SET的工作带来了较大难度,这可能是唯一的弊端。
提交队列和持续集成构建由来
by Jeff Carollo
在Google规模还很小的初期,有一个约定的习俗就是在代码提交之前需要运行所有已经编写好的单元测试,用以验证这次代码变更的质量是否满足要求。测试运行失败的情况常常会发生,大家不得不花时间去找到问题的根源并加以修复。
公司在不断变大,为了节省资源,高质量的公共基础库被工程师们编写实现、维护和共用。且随着时间的变化,这些核心公共代码在数量上、规模上和复杂性上都有显著的增长。在这个时候,仅仅依靠单元测试就不够了,在一些与外部公共库或框架有交互的地方还需要依赖集成测试的验证。此时Google也发现许多测试运行失败的原因都是由于其外部依赖所导致。但在没有代码提交之前,这些测试不会被运行,即使它们已经失败数天之久也无人知晓。
这个时候“单元测试展板(Unit Test Dashboard)”出现了。这个系统把所有公司代码库的一级目录都作为一个“项目”,当然也允许自己增加自定义的“项目”,只要提供一系列构建和测试维护人员信息即可。这个系统会每日运行所有项目的测试。在展板上展示一个报表,记录着每个项目的测试通过与失败比率。每日运行失败的项目维护者也会收到一封相应的通知邮件,虽然测试运行失败通常不会持续太长的时间,但依然还会有失败的情况发生。
有些团队希望能够尽早知道哪些代码变更可能引起构建失败。每24小时才运行一次所有测试已经不能满足要求。个别团队就开始去编写持续构建脚本,在专用机器上持续不断地构建并运行相应的单元测试与集成测试。后来发现这个系统具有一定的通用性,也可以用来支持其他团队,Chris Lopez和Jay Corbett就一起编写了“Chris/Jay持续构建”工具,其他团队通过注册一台机器、填写一个配置文件和运行一个脚本,就能够运行自己的持续集成了。这很快变成了一个标准做法,后来几乎所有的Google项目都在使用Chris/Jay持续构建工具。在测试运行失败之后,会给最近一次提交代码的开发人员发送一封通知邮件,因为他们极有可能是导致测试失败的元凶。另外,Chris/Jay持续构建工具找出了“黄金变更列表”,这些代码变更在版本控制系统上得到确认,所有相关的测试和构建都已经成功通过。这样开发可以得到干净的代码版本而不受到最近提交代码的影响,最近提交的代码可能会导致构建失败(对于挑选用于发布的版本会非常有帮助)。
还有部分团队希望能够更早地捕获引起构建失败的代码变更。随着项目规模和复杂度的上升,一旦发生构建失败就已经有些晚了,就需要花费很大代价去修复。出于保护持续构建系统的目的,提交队列就出现了。在早期实现版本中,所有等待提交的CL必须逐个排队,等待测试,如果测试通过则证明这个CL是没有问题的,可以提交进代码库(因此也需要排队)。当有大量长时间运行的测试需要执行时,CL在发送给提交队列和CL真正被提交到源码库之间可能需要消耗数小时,这确实也很常见。在后来的实现中,允许所有等待的CL在互相隔离的前提下,并发地构建并运行测试。这样的改进可能会引起一些竞争条件的出现,但实际上很少发生,他们最终也都会被持续构建系统所捕获。快速地提交代码,省下的时间远远大于解决偶尔需要修复持续构建错误的时间。多数Google大型项目都在使用提交队列,项目成员会轮流做“构建警察”,构建警察的职责是快速响应处理任何在提交队列和持续构建系统中遇到的问题。
整套系统(单元测试展板、Chris/Jay持续构建工具和提交队列)在Google存活了相当长的时间(数以年计)。它们只需很少的搭建时间成本和不同程度的维护工作,但却给团队提供了极大的帮助。可以这样讲,它已经成为一个实用可行的公用基础工具,为所有团队在系统集成方面提供帮助。测试自动化,简写TAP(译注:Test Automation Program)就是这样做的。TAP几乎应用于所有的Google项目,但Chromium和Android除外(它们是开源项目,使用了不同代码库和构建环境)。
虽然所有的团队使用相同的一套工具和基础框架有一定的益处,但这些益处也不能被过分夸大。有些简单的小工具也可以解决现实问题。工程师使用一个简单的命令在云端提交CL、并发构建、运行所有可能涉及的测试代码,并将运行结果可视化地展示在一个永久的网站上。在命令运行终端也会显示“成功”、“失败”,以及指向任务详情的超链接。如果开发选择使用这样的方式,他的测试结果(包括覆盖率信息)就会被存储在云端,并通过Google内部代码审查工具对所有的代码审查者可见。
2.1.9 SET的工作流程:一个实例
现在让我们把所有与SET相关的东西拼装在一起,看一个完整的实例。需要注意的是,这部分将涉及部分技术内容,且会深入到某些底层细节里面。如果你只对SET概要介绍感兴趣,那么你可以跳过这一部分。
假设有一个简单的网络应用,它的功能是允许用户向Google提交URL,并把这个URL增加到Google的索引文件之中。HTML的网页表单页面上接收两个字段:url和相应的注释,然后向Google的服务器发送类似以下的一个HTTP GET请求。
GET /addurl?url=http://www.foo.com&comment=Foo+comment HTTP/1.1
在这个例子中,这个web应用的服务器端分成至少两部分:前端服务AddUrlFrontend(它接收原始的HTTP请求,并做解析和验证工作)和后端服务AddUrlService。这个后端服务接受来自于前端服务AddUrlFrontend的请求,检查数据是否有错,并与后端数据存储持久层(例如Google的Bigtable(译注:http://labs.google.com/papers/bigtable.html)或GFS Goolge文件系统(译注:http://labs.google. com/papers/gfs.html)进行交互。
SWE针对这个服务,要做的第一件事就是为这个项目创建一个目录。
$ mkdir depot/addurl/
他们使用Google Protocol Buffer描述性语言(注:http://code.google.com/apis/protocol buffers/ docs/overview.html)定义AddUrlService的协议。
File: depot/addurl/addurl.proto
message AddUrlRequest {
required string url = 1; // The URL entered by the user.
optional string comment = 2; // Comments made by the user.
}
message AddUrlReply {
// Error code, if an error occurred.
optional int32 error_code = 1;
// Error message, if an error occurred.
optional string error_details = 2;
}
service AddUrlService {
// Accepts a URL for submission to the index.
rpc AddUrl(AddUrlRequest) returns (AddUrlReply) {
option deadline = 10.0;
}
}
上面的“addurl.proto”文件定义了三个重要部分:AddUrlRequest的消息格式AddUrlReply的消息格式、AddUrlService远程方法调用服务(RPC)。
通过查看AddUrlRequest消息的定义,我们可以知道调用者必须提供一个url字段,而另外一个comment字段是可选的。
类似地,通过检查AddUrlReply消息的定义,我们可以知道error_code 和 error_details两个服务器提供的响应字段都是可选的。我们可以安全地假设:当一个URL被成功接收以后这些字段一般情况下会返回为空,这样也可以最小化中间的数据传输量。这是Google的惯例,让常见的场景快速运行。
通过查看AddUrlService服务的定义可以知道单一服务方法——AddUrl,接受一个AddUrlRequest并返回一个AddUrlReply。默认情况下,如果client在调用AddUrl 之后10秒还没有收到任何回应就会超时。AddUrlService在实现上会与后端持久数据存储层再做交互,但client并不需要关心这一部分细节,所以在“addurl.proto”文件中没有这部分接口的定义详情。
在消息字段中出现的“=1”并不是指这个字段的值。这种使用方法是为了允许协议将来升级使用。例如,以后某人可能想增加一个额外的uri字段到AddUrlRequest消息中。为了实现这个,他们可以做如下变更。
message AddUrlRequest {
required string url = 1; // The URL entered by the user.
optional string comment = 2; // Comments made by the user.
optional string uri = 3; // The URI entered by the user.
}
但这样做会有点傻。一些人更希望直接把url字段修改为uri。如果使用相同的数值,老版本和新版本之间就会保持兼容性。
message AddUrlRequest {
required string uri = 1; // The URI entered by the user.
optional string comment = 2; // Comments made by the user.
}
在完成addurl.proto以后,开发人员可以为proto_library创建构建规则,根据addurl.proto中定义的字段自动产生C++源文件并编译成一个C++静态库(增加额外的选项,也可以绑定到其他语言,如Java或Ptyhon)。
File: depot/addurl/BUILD
proto_library(name=”addurl”,
srcs=[“addurl.proto”])
开发人员使用构建系统,并修复在构建过程中可能出现的addurl.proto问题或构建定义文件中的问题。构建系统会调用Protocol Buffer编译器,产生源码文件addurl.pb.h和addurl.pb.cc,同时会产生一个可以被链接的静态库adurl。
现在可以新建文件addurl_frontend.h,并在其中定义AddUrlFrontend类。代码大体如下。
File: depot/addurl/addurl_frontend.h
#ifndef ADDURL_ADDURL_FRONTEND_H_
#define ADDURL_ADDURL_FRONTEND_H_
// Forward-declaration of dependencies.
class AddUrlService;
class HTTPRequest;
class HTTPReply;
// Frontend for the AddUrl system.
// Accepts HTTP requests from web clients,
// and forwards well-formed requests to the backend.
class AddUrlFrontend {
public:
// Constructor which enables injection of an
// AddUrlService dependency.
explicit AddUrlFrontend(AddUrlService* add_url_service);
~AddUrlFrontend();
// Method invoked by our HTTP server when a request arrives
// for the /addurl resource.
void HandleAddUrlFrontendRequest(const HTTPRequest* http_request,
HTTPReply* http_reply);
private:
AddUrlService* add_url_service_;
// Declare copy constructor and operator= private to prohibit
// unintentional copying of instances of this class.
AddUrlFrontend(const AddUrlFrontend&);
AddUrlFrontend& operator=(const AddUrlFrontend& rhs);
};
#endif // ADDURL_ADDURL_FRONTEND_H_
继续AddUrlFrontend类的实现部分,开发人员创建“addurl_frontend.cc”文件。这是AddUrlFrontend类的主要逻辑实现部分,为了简短说明,省略了部分文件内容。
File: depot/addurl/addurl_frontend.cc
#include “addurl/addurl_frontend.h”
#include “addurl/addurl.pb.h”
#include “path/to/httpqueryparams.h”
// Functions used by HandleAddUrlFrontendRequest() below, but
// whose definitions are omitted for brevity.
void ExtractHttpQueryParams(const HTTPRequest* http_request,
HTTPQueryParams* query_params);
void WriteHttp200Reply(HTTPReply* reply);
void WriteHttpReplyWithErrorDetails(
HTTPReply* http_reply, const AddUrlReply& add_url_reply);
// AddUrlFrontend constructor that injects the AddUrlService
// dependency.
AddUrlFrontend::AddUrlFrontend(AddUrlService* add_url_service)
: add_url_service_(add_url_service) {
}
// AddUrlFrontend destructor - there’s nothing to do here.
AddUrlFrontend::~AddUrlFrontend() {
}
// HandleAddUrlFrontendRequest:
// Handles requests to /addurl by parsing the request,
// dispatching a backend request to an AddUrlService backend,
// and transforming the backend reply into an appropriate
// HTTP reply.
//
// Args:
// http_request - The raw HTTP request received by the server.
// http_reply - The raw HTTP reply to send in response.
void AddUrlFrontend::HandleAddUrlFrontendRequest(
const HTTPRequest* http_request, HTTPReply* http_reply) {
// Extract the query parameters from the raw HTTP request.
HTTPQueryParams query_params;
ExtractHttpQueryParams(http_request, &query_params);
// Get the ‘url’ and ‘comment’ query components.
// Default each to an empty string if they were not present
// in http_request.
string url = query_params.GetQueryComponentDefault(“url”, “”);
string comment = query_params.GetQueryComponentDefault(“comment”, “”);
// Prepare the request to the AddUrlService backend.
AddUrlRequest add_url_request;
AddUrlReply add_url_reply;
add_url_request.set_url(url);
if (!comment.empty()) {
add_url_request.set_comment(comment);
}
// Issue the request to the AddUrlService backend.
RPC rpc;
add_url_service_->AddUrl(
&rpc, &add_url_request, &add_url_reply);
// Block until the reply is received from the
// AddUrlService backend.
rpc.Wait();
// Handle errors, if any:
if (add_url_reply.has_error_code()) {
WriteHttpReplyWithErrorDetails(http_reply, add_url_reply);
} else {
// No errors. Send HTTP 200 OK response to client.
WriteHttp200Reply(http_reply);
}
}
HandleAddUrlFrontendRequest是一个经常被调用的成员函数。许多Web处理函数大多如此。开发人员可以通过提取一些功能到helper函数中,用来简化这个函数。但是,类似这样的重构在构建稳定之前和单元测试编写完成并可以顺利通过运行之前是很少去做的。
在这个时候,开发人员修改已有addurl项目的构建文件,为addurl_frontend库增加入口。在构建的时候会产生一个C++静态库AddUrlFrontend。
File: /depot/addurl/BUILD
From before:
proto_library(name=”addurl”,
srcs=[“addurl.proto”])
New:
cc_library(name=”addurl_frontend”,
srcs=[“addurl_frontend.cc”],
deps=[
“path/to/httpqueryparams”,
“other_http_server_stuff”,
“:addurl”, # Link against the addurl library above.
])
再次运行构建工具,同时修复在编译链接addurl_frontend.h和addurl_frontend.cc过程中可能出现的错误,直到所有编译和链接不出现警告和错误为止。此时,可以去编写AddUrlFrontend的单元测试代码了。单元测试在另外一个新文件“addurl_frontend_test.cc”中。在测试中定义一个虚假(fake)的后端服务,使用AddUrlFrontend的构造函数可以把这个虚假的后端服务在运行时刻调用。这样的话,单元测试在运行时,无需修改AddUrlFrontend代码本身,代码逻辑能够进入AddUrlFrontend内部期望分支中或错误流程里(译注:阅读以下代码需要提前了解Google’s framework for writing C++ test,即googletest,参见https://code.google.com/p/googletest/)。
File: depot/addurl/addurl_frontend_test.cc
include “addurl/addurl.pb.h”
include “addurl/addurl_frontend.h”
// See http://code.google.com/p/googletest/
include “path/to/googletest.h”
// Defines a fake AddUrlService, which will be injected by
// the AddUrlFrontendTest test fixture into AddUrlFrontend
// instances under test.
class FakeAddUrlService : public AddUrlService {
public:
FakeAddUrlService()
: has_request_expectations_(false),
error_code_(0) {
}
// Allows tests to set expectations on requests.
void set_expected_url(const string& url) {
expected_url_ = url;
has_request_expectations_ = true;
}
void set_expected_comment(const string& comment) {
expected_comment_ = comment;
has_request_expectations_ = true;
}
// Allows for injection of errors by tests.
void set_error_code(int error_code) {
error_code_ = error_code;
}
void set_error_details(const string& error_details) {
error_details_ = error_details;
}
// Overrides of the AddUrlService::AddUrl method generated from
// service definition in addurl.proto by the Protocol Buffer
// compiler.
virtual void AddUrl(RPC* rpc,
const AddUrlRequest* request,
AddUrlReply* reply) {
// Enforce expectations on request (if present).
if (has_request_expectations_) {
EXPECT_EQ(expected_url_, request->url());
EXPECT_EQ(expected_comment_, request->comment());
}
// Inject errors specified in the set_* methods above if present.
if (error_code_ != 0 || !error_details_.empty()) {
reply->set_error_code(error_code_);
reply->set_error_details(error_details_);
}
}
private:
// Expected request information.
// Clients set using set_expected_* methods.
string expected_url_;
string expected_comment_;
bool has_request_expectations_;
// Injected error information.
// Clients set using set_* methods above.
int error_code_;
string error_details_;
};
// The test fixture for AddUrlFrontend. It is code shared by the
// TEST_F test definitions below. For every test using this
// fixture, the fixture will create a FakeAddUrlService, an
// AddUrlFrontend, and inject the FakeAddUrlService into that
// AddUrlFrontend. Tests will have access to both of these
// objects at runtime.
class AddurlFrontendTest : public ::testing::Test {
protected:
// Runs before every test method is executed.
virtual void SetUp() {
// Create a FakeAddUrlService for injection.
fake_add_url_service_.reset(new FakeAddUrlService);
// Create an AddUrlFrontend and inject our FakeAddUrlService
// into it.
add_url_frontend_.reset(
new AddUrlFrontend(fake_add_url_service_.get()));
}
scoped_ptr fake_add_url_service_;
scoped_ptr add_url_frontend_;
};
// Test that AddurlFrontendTest::SetUp works.
TEST_F(AddurlFrontendTest, FixtureTest) {
// AddurlFrontendTest::SetUp was invoked by this point.
}
// Test that AddUrlFrontend parses URLs correctly from its
// query parameters.
TEST_F(AddurlFrontendTest, ParsesUrlCorrectly) {
HTTPRequest http_request;
HTTPReply http_reply;
// Configure the request to go to the /addurl resource and
// to contain a ‘url’ query parameter.
http_request.set_text(
“GET /addurl?url=http://www.foo.com HTTP/1.1rnrn”);
// Tell the FakeAddUrlService to expect to receive a URL
// of ‘http://www.foo.com’.
fake_add_url_service_->set_expected_url(“http://www.foo.com”);
// Send the request to AddUrlFrontend, which should dispatch
// a request to the FakeAddUrlService.
add_url_frontend_->HandleAddUrlFrontendRequest(
&http_request, &http_reply);
// Validate the response.
EXPECT_STREQ(“200 OK”, http_reply.text());
}
// Test that AddUrlFrontend parses comments correctly from its
// query parameters.
TEST_F(AddurlFrontendTest, ParsesCommentCorrectly) {
HTTPRequest http_request;
HTTPReply http_reply;
// Configure the request to go to the /addurl resource and
// to contain a ‘url’ query parameter and to also contain
// a ‘comment’ query parameter that contains the
// url-encoded query string ‘Test comment’.
http_request.set_text(“GET /addurl?url=http://www.foo.com”
“&comment=Test+comment HTTP/1.1rnrn”);
// Tell the FakeAddUrlService to expect to receive a URL
// of ‘http://www.foo.com’ again.
fake_add_url_service_->set_expected_url(“http://www.foo.com”);
// Tell the FakeAddUrlService to also expect to receive a
// comment of ‘Test comment’ this time.
fake_add_url_service_->set_expected_comment(“Test comment”);
// Send the request to AddUrlFrontend, which should dispatch
// a request to the FakeAddUrlService.
add_url_frontend_->HandleAddUrlFrontendRequest(
&http_request, &http_reply);
// Validate that the response received is a ‘200 OK’ response.
EXPECT_STREQ(“200 OK”, http_reply.text());
}
// Test that AddUrlFrontend sends proper error information when
// the AddUrlService encounters a client error.
TEST_F(AddurlFrontendTest, HandlesBackendClientErrors) {
HTTPRequest http_request;
HTTPReply http_reply;
// Configure the request to go to the /addurl resource.
http_request.set_text(“GET /addurl HTTP/1.1rnrn”);
// Configure the FakeAddUrlService to inject a client error with
// error_code 400 and error_details of ‘Client Error’.
fake_add_url_service_->set_error_code(400);
fake_add_url_service_->set_error_details(“Client Error”);
// Send the request to AddUrlFrontend, which should dispatch
// a request to the FakeAddUrlService.
add_url_frontend_->HandleAddUrlFrontendRequest(
&http_request, &http_reply);
// Validate that the response contained a 400 client error.
EXPECT_STREQ(“400rnError Details: Client Error”,
http_reply.text());
}
通常情况下开发人员会写更多的测试用例,但这里只是通过上面的示例来演示通用模式,即如何定义Fake对象、如何注入这个Faoke对象、在测试中如何调用这个Fake对象来引入期待的错误并验证程序逻辑,上面的例子就已经足够了。有一个需要注意的地方,那就是此例中我们缺少了模拟AddUrlFrontend和FakeAddUrlService之间的网络超时。这说明我们的开发人员忘记了去处理在超时条件下的检查验证逻辑。
有经验的敏捷测试高手会指出所有测试使用FakeAddUrlService有点单一,也可以使用mock来替换。这个高手的建议是对的。我们使用一个fake只是为了纯粹的演示目的。
现在我们的开发人员想去运行这些测试,他必须先要修改构建定义文件,把新测试代码addurl_frontend_test添加到构建规则中去。
File: depot/addurl/BUILD
From before:
proto_library(name=”addurl”,
srcs=[“addurl.proto”])
Also from before:
cc_library(name=”addurl_frontend”,
srcs=[“addurl_frontend.cc”],
deps=[
“path/to/httpqueryparams”,
“other_http_server_stuff”,
“:addurl”, # Depends on the proto_library above.
])New:
cc_test(name=”addurl_frontend_test”,
size=”small”, # See section on Test Sizes.
srcs=[“addurl_frontend_test.cc”],
deps=[
“:addurl_frontend”, # Depends on library above.
“path/to/googletest_main”])
开发人员再一次使用构建工具编译运行addurl_frontend_test程序,修复构建中可能出现的编译链接错误,这次也会修复测试程序的错误,包括测试套件、fake和AddUrlFrontend本身的错误。上述过程在FixtureTest定义之后就会迅速展开,后面的用例添加之后也会重复上面的过程。当测试都通过之后,开发人员会创建一个包含所有这些文件的代码变更CL,修复代码检查工具提示的小问题,再把这个CL发出去做代码审查,然后就去做另外的工作(很可能是实现一个真实的后端AddUrlService服务),并等待代码审查的结果反馈。
$ create_cl BUILD \
addurl.proto \
addurl_frontend.h \
addurl_frontend.cc \
addurl_frontend_test.cc$ mail_cl -m [email protected]
当代码审查反馈结果出来之后,开发人员会做适当的修改(或与审查者一起协商方案),很可能需要再次审查,然后将这个CL提交到代码库之中。从此刻起,不管什么时候如果有人修改了这里面的任何文件,Google的自动化测试系统就会感知,并运行addurl_frontend_test这个测试来验证是否新的修改导致已有测试用例运行失败。另外,如果有人尝试去修改addurl_frontend.cc,addurl_frontend_test就像一个安全保护网一样自动运行并进行保护。
**2.1.10 测试执行**
然而,测试自动化不仅仅是自动化测试程序的编写。如果想让这些测试程序有价值,必须要去考虑如何编译测试程序、执行、分析、存储和报告所有测试运行结果,这些都是自动化测试会遇到的挑战。在软件开发过程中测试自动化想真正发挥作用,还要凭借其自身的努力。
除了要关注如何正确编写自动化程序之外,还要把工程师的注意力转移到在实际项目中如何更大发挥自动化测试的价值上。只有能加速开发过程的自动化测试才有意义,测试不应拖慢开发的速度。因此,自动化必须与开发过程真正集成在一起,并使之成为开发过程的一部分,而不是孤立它。功能代码从来都不像真空一样孤立存在,测试代码也是如此。
因此,一个可以做代码编译、测试执行、结果分析、数据存储、报表展示的通用的测试框架逐渐形成了。事情正在向我们期待的方向上发展:Google工程师专注于测试程序的编写、运行的细节留给通用基础执行框架。对于工程师来说,测试代码和功能代码一样,都是代码。
在SET新增一个测试程序之后,同时会针对这个测试创建一个构建说明文件。这个测试程序的构建文件包括测试名称、源码文件、依赖库及数据、还要指明其规模大小。每一个测试程序必须要标明它的规模是小型、中型、大型还是超大型。在编写完测试程序和构建文件之后,后面就交给Google构建工具和测试执行框架了。从提交时刻开始,一个命令就可以触发构建、运行自动化、展示运行结果了。
Google的测试执行框架对我们如何编写测试程序有一定的要求限制。这些要求是怎样的以及我们是如何应对处理的,在后面会做更多解释。
**2.1.11 测试大小的定义**
随着Google不断的成长和新员工不断的增加,一些令人疑惑的测试类型方面的专业术语持续不断地涌现出来:单元测试、代码级别测试、白盒测试、集成测试、系统测试、端到端测试等,从不同的粒度级别来表述测试的类型,如图2.1所示。在不久前,我们终于觉得忍无可忍,于是自己创建了一套测试命名规则。
 1.小型测试
小型测试是为了验证一个代码单元的功能,一般与运行环境隔离,例如针对一个独立的类或一组相关函数的测试。小型测试的运行不需要外部依赖。在Google之外,小型测试通常就是单元测试。
小型测试是所有测试类型里范畴最小的,一般集中精力在函数级别的独立操作与调用上,如图2.2所示。这样限定了范畴的测试可以提供更加全面的底层代码覆盖率,而其他类型的测试无法做到这一点。
1.小型测试
小型测试是为了验证一个代码单元的功能,一般与运行环境隔离,例如针对一个独立的类或一组相关函数的测试。小型测试的运行不需要外部依赖。在Google之外,小型测试通常就是单元测试。
小型测试是所有测试类型里范畴最小的,一般集中精力在函数级别的独立操作与调用上,如图2.2所示。这样限定了范畴的测试可以提供更加全面的底层代码覆盖率,而其他类型的测试无法做到这一点。
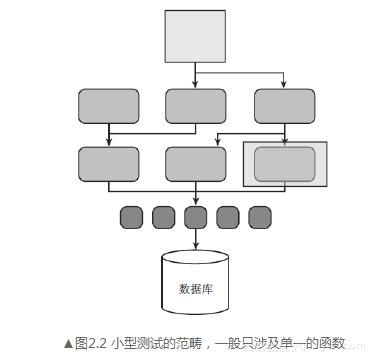 在小型测试里,外部服务(如文件系统、网络、数据库)必须通过模拟或虚假实现(mock & fake)。为了减少依赖,适当的时候也可模拟实现被测类所在模块的内部服务。
范畴隔离且没有外部依赖,这让小型测试可以在很短时间内就运行结束。因此,它们的执行频率也会更加频繁,并且可以很快就会发现问题。通常情况下,在开发人员修改了他们的功能代码之后就会立刻运行这些测试,当然他们还要维护这些测试代码。范畴隔离可以使构建与测试执行时间变短。
2.中型测试
中型测试是验证两个或多个模块应用之间的交互,如图2.3所示。和小型测试相比,中型测试有着更大的范畴且运行所需要的时间也更久。小型测试会尝试走遍单独函数的所有路径,而中型测试的主要目标是验证指定模块之间的交互。在Google之外,中型测试经常被称为“集成测试”。
中型测试运行的时间需要更久,需要测试执行工具在执行频率上加以控制,不能像小型测试那样频繁地运行。一般情况下是由SET来组织运行中型测试。
对于中型测试,鼓励使用模拟技术(mock)来解决外部服务的依赖问题,但这不是强制的,如出于性能考虑可以不使用模拟技术。轻量级的虚假实现(fake),如常驻内存的数据库,在不能使用mock的场景下可以用来提升性能。
在小型测试里,外部服务(如文件系统、网络、数据库)必须通过模拟或虚假实现(mock & fake)。为了减少依赖,适当的时候也可模拟实现被测类所在模块的内部服务。
范畴隔离且没有外部依赖,这让小型测试可以在很短时间内就运行结束。因此,它们的执行频率也会更加频繁,并且可以很快就会发现问题。通常情况下,在开发人员修改了他们的功能代码之后就会立刻运行这些测试,当然他们还要维护这些测试代码。范畴隔离可以使构建与测试执行时间变短。
2.中型测试
中型测试是验证两个或多个模块应用之间的交互,如图2.3所示。和小型测试相比,中型测试有着更大的范畴且运行所需要的时间也更久。小型测试会尝试走遍单独函数的所有路径,而中型测试的主要目标是验证指定模块之间的交互。在Google之外,中型测试经常被称为“集成测试”。
中型测试运行的时间需要更久,需要测试执行工具在执行频率上加以控制,不能像小型测试那样频繁地运行。一般情况下是由SET来组织运行中型测试。
对于中型测试,鼓励使用模拟技术(mock)来解决外部服务的依赖问题,但这不是强制的,如出于性能考虑可以不使用模拟技术。轻量级的虚假实现(fake),如常驻内存的数据库,在不能使用mock的场景下可以用来提升性能。
 3.对于大型测试
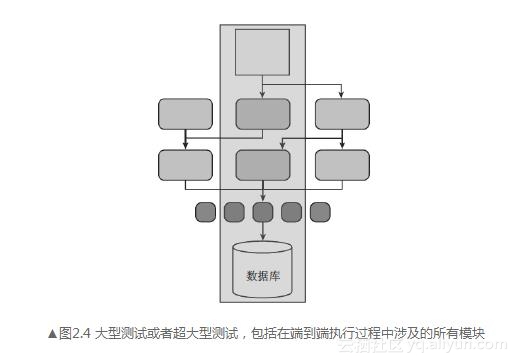
在Google之外通常被称为“系统测试”或“端到端测试”。大型测试在一个较高层次上运行,验证系统作为一个整体是如何工作的。这涉及应用系统的一个或所有子系统,从前端界面到后端数据储存,如图2.4所示。该测试也可能会依赖外部资源,如数据库、文件系统、网络服务等。
3.对于大型测试
在Google之外通常被称为“系统测试”或“端到端测试”。大型测试在一个较高层次上运行,验证系统作为一个整体是如何工作的。这涉及应用系统的一个或所有子系统,从前端界面到后端数据储存,如图2.4所示。该测试也可能会依赖外部资源,如数据库、文件系统、网络服务等。
 **注意**
小型测试是为了验证一个代码单元的功能。中型测试验证两个或多个模块应用之间的交互。大型测试是为了验证整个系统作为一个整体是如何工 作的。
**2.1.12 测试规模在共享测试平台中的使用**
使用统一的运行方式来执行不同的自动化测试是有一定难度的。对于一个大型工程组织来说,如果想使用通用的测试执行平台,那么这个平台必须支持运行各种各样的测试任务。
使用Google测试执行平台运行的一些通用任务如下。
开发人员编译和运行小型测试,希望立刻就能知道运行结果。
开发人员希望运行一个项目的所有小型测试,并能够快速知道运行结果。
开发人员只有在变更代码出现时,才希望去编译运行相关的项目测试,并即刻得到运行结果。
工程师希望能够知道一个项目的测试覆盖率并查看结果。
对项目的每次代码变更(CL),都能够运行这个项目的小型测试,并将运行结果发送给团队成员以辅助进行代码审查。
在代码变更(CL)提交到版本控制系统之后,自动运行项目的所有测试。
团队希望每周都能得到代码覆盖率,并实时跟踪覆盖率的变化。
上面提及的所有任务,有可能同时并发提交到Google测试执行系统。一些测试可能极度消耗资源,使得公用测试机器处于不可用状态达数小时。另外一些测试可能只需几毫秒,而且可以和其他几百个任务同时在一台机器上并发运行。当每一个测试都被标记为小型、中型、大型的时候,调度运行这些测试任务就会变得相对简单一些,因为调度器已经知道每个任务需要运行的时间,这样可以优化任务队列,达到合理利用的目的。
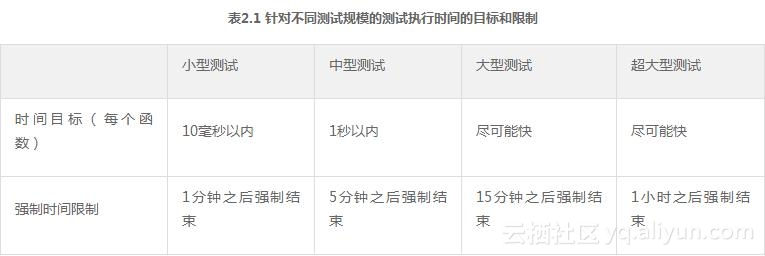
Google测试执行系统利用了测试规模的定义,把运行较快的任务从较慢的任务中挑选出来。测试规模在测试运行时间上规定了一个最大值,如表2.1所示;同时测试规模在测试运行消耗资源上也做了要求,如表2.2所示。Google测试执行系统在发现任何测试超时,或是消耗的资源超过这个测试规模应该使用的资源时,会把这个测试任务取消掉并报告这个错误。这会迫使工程师提供合适的测试规模标签。精准的测试规模,可以使Google测试执行系统在调度时做出明智的决定。
**注意**
小型测试是为了验证一个代码单元的功能。中型测试验证两个或多个模块应用之间的交互。大型测试是为了验证整个系统作为一个整体是如何工 作的。
**2.1.12 测试规模在共享测试平台中的使用**
使用统一的运行方式来执行不同的自动化测试是有一定难度的。对于一个大型工程组织来说,如果想使用通用的测试执行平台,那么这个平台必须支持运行各种各样的测试任务。
使用Google测试执行平台运行的一些通用任务如下。
开发人员编译和运行小型测试,希望立刻就能知道运行结果。
开发人员希望运行一个项目的所有小型测试,并能够快速知道运行结果。
开发人员只有在变更代码出现时,才希望去编译运行相关的项目测试,并即刻得到运行结果。
工程师希望能够知道一个项目的测试覆盖率并查看结果。
对项目的每次代码变更(CL),都能够运行这个项目的小型测试,并将运行结果发送给团队成员以辅助进行代码审查。
在代码变更(CL)提交到版本控制系统之后,自动运行项目的所有测试。
团队希望每周都能得到代码覆盖率,并实时跟踪覆盖率的变化。
上面提及的所有任务,有可能同时并发提交到Google测试执行系统。一些测试可能极度消耗资源,使得公用测试机器处于不可用状态达数小时。另外一些测试可能只需几毫秒,而且可以和其他几百个任务同时在一台机器上并发运行。当每一个测试都被标记为小型、中型、大型的时候,调度运行这些测试任务就会变得相对简单一些,因为调度器已经知道每个任务需要运行的时间,这样可以优化任务队列,达到合理利用的目的。
Google测试执行系统利用了测试规模的定义,把运行较快的任务从较慢的任务中挑选出来。测试规模在测试运行时间上规定了一个最大值,如表2.1所示;同时测试规模在测试运行消耗资源上也做了要求,如表2.2所示。Google测试执行系统在发现任何测试超时,或是消耗的资源超过这个测试规模应该使用的资源时,会把这个测试任务取消掉并报告这个错误。这会迫使工程师提供合适的测试规模标签。精准的测试规模,可以使Google测试执行系统在调度时做出明智的决定。
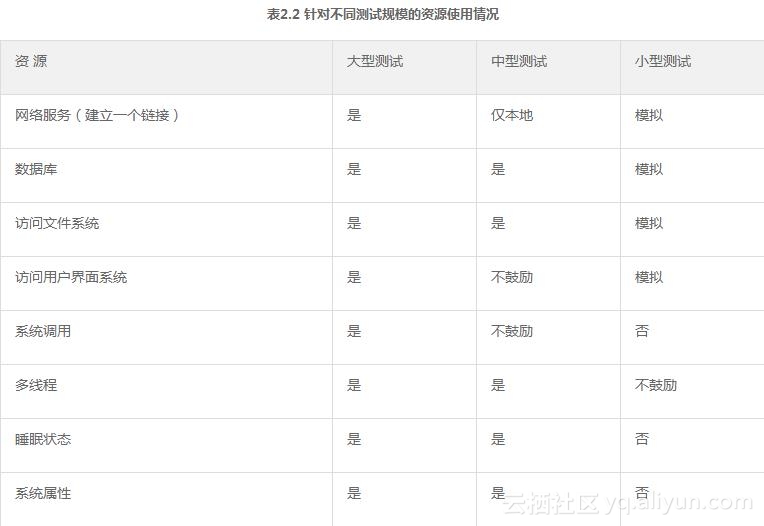 **2.1.13 测试规模的益处**
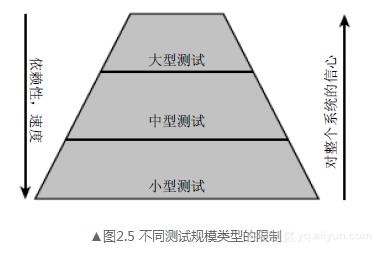
每一种测试规模都带来了一些益处,如图2.5所示。每种测试规模的优点和缺点也都罗列在这里以供参考和比较。
**2.1.13 测试规模的益处**
每一种测试规模都带来了一些益处,如图2.5所示。每种测试规模的优点和缺点也都罗列在这里以供参考和比较。
 1.大型测试
大型测试的优点和缺点包括如下。
测试最根本最重要的:在考虑外部系统的情况下应用系统是如何工作的。
由于对外部系统有依赖,因此它们是非确定性的。
很宽的测试范畴意味着如果测试运行失败,寻找精准失败根源就会比较困难。
测试数据的准备工作会非常耗时。
大型测试是较高层次的操作,如果想要走到特定的代码路径区域是不切实际的,而这一部分却是小型测试的专长。
2.中型测试
中型测试的优点和缺点包括如下。
由于不需要使用mock技术,且不受运行时刻的限制,因此该测试是从大型测试到小型测试之间的一个过渡。
因为它们运行速度相对较快,所以可以频繁地运行它们。
它们可以在标准的开发环境中运行,因此开发人员也可以很容易运行它们。
它们依赖外部系统。
由于对外部系统有依赖,因此它们本身就有不确定性。
它们的运行速度没有小型测试快。
3.小型测试
小型测试的优点和缺点包括如下。
为了更容易地就被测试到,代码应清晰干净、函数规模较小且重点集中。为了方便模拟,系统之间的接口需要有良好的定义。
由于它们可以很快运行完毕,因此在有代码变更发生的时候就可以立刻运行,从而可以较早地发现缺陷并提供及时的反馈。
在所有的环境下它们都可以可靠地运行。
它们有较小的测试范围,这样可以很容易地做边界场景与错误条件的测试,例如一个空指针。
它们有特定的范畴,可以很容易地隔离错误。
不要做模块之间的集成测试,这是其他类型的测试要做的事情(中型测试)。
有时候对子系统的模拟是有难度的。
使用mock或fake环境,可以不与真实的环境同步。
小型测试带来优秀的代码质量、良好的异常处理、优雅的错误报告;大中型测试带来整体产品质量和数据验证。单一的测试类型不能解决所有项目需求。正是由于这个原因,Google项目维护着一个不同测试类型之间的健康比例。对于一个项目,如果全部使用大型的端到端自动化测试是错误的,全部使用小型的单元测试同样也是错误的。
**注意**
小型测试带来优秀的代码质量、良好的异常处理、优雅的错误报告;大中型测试会带来整体产品质量和数据验证。
检验一个项目里小型测试、中型测试和大型测试之间的比率是否健康,一个好办法是使用代码覆盖率。测试代码覆盖率可以针对小型测试、中大型测试分别单独产生报告。覆盖率报告会针对不同的项目展示一个可被接受的覆盖率结果。如果中大型测试只有20%的代码覆盖率,而小型测试有近100%的覆盖率,则说明这个项目缺乏端到端的功能验证。如果结果数字反过来了,则说明这个项目很难去做升级扩展和维护,由于小型测试较少,就需要大量的时间消耗在底层代码调试查错上。Google工程师可以使用构建与运行测试时使用的工具,来产生并查看测试覆盖率结果,只需要在命令行中额外增加一个选项即可。覆盖率结果会存储在云端,任何工程师在公司内网络环境下都可以通过浏览器查看这些报告。
Google有许多不同类型的项目,这些项目对测试的需求也不同,小型测试、中型测试和大型测试之间的比例随着项目团队的不同而不同。这个比例并不是固定的,总体上有一个经验法则,即70/20/10原则:70%是小型测试,20%是中型测试,10%是大型测试。如果一个项目是面向用户的,拥有较高的集成度,或者用户接口比较复杂,他们就应该有更多的中型和大型测试;如果是基础平台或者面向数据的项目,例如索引或网络爬虫,则最好有大量的小型测试,中型测试和大型测试的数量要求会少很多。
另外有一个用来监视测试覆盖率的内部工具是Harvester。Harvester是一个可视化的工具,可以记录所有项目的CL历史,并以图形化的方式展示,例如测试代码和CL中新增代码的比率、代码变更的多少、按时间的变化频率、按照开发人员的变化次数,等等。这些图形的目的是展示随着时间的变化,测试的变化趋势是怎样的。
**2.1.14 测试运行要求**
无论测试规模的大小是什么,由于Google的测试执行系统是一个公用环境,因此就要求测试本身满足下面几个条件。
每个测试和其他测试之间都是独立的,使它们就能够以任意顺序来执行。
测试不做任何数据持久化方面的工作。在这些测试用例离开测试环境的时候,要保证测试环境的状态与测试用例开始执行之前的状态是一样的。
这两个要求比较简单也很容易理解,但必须严格遵守。测试本身会尽可能地遵守要求,但被测系统却有可能违背原则;保存数据或修改环境配置信息。幸运的是,Google测试执行环境提供了许多特性可以确保这些要求比较容易就得到满足。
由于测试用例有独立运行的要求,在运行时刻,工程师通过设置一个标记就能以随机的顺序来执行它们。这样也可以找到那些对执行顺序有要求的用例。总之,“任意顺序”意味着可以并发执行用例。测试执行系统可以选择在同一个机器上同时执行两个用例,但如果每个用例都要求独占系统某些资源,其中一个用例就可能运行失败。例如以下几种情况。
两个测试都要绑定同一个端口,用以接收来自网络的数据。
两个测试需要在同一个路径下创建相同的目录。
一个测试希望创建并使用一个数据库表,而另外一个测试想删除这个数据库表。
这种类型的冲突,不仅会导致自己的用例运行失败,而且可能会导致测试执行系统中其他正在运行的用例也失败,即便另外的用例已经遵守了规则。测试执行系统可以找出这些测试用例,并通知给相应的用例负责人。另外,通过设置一个特殊标记,用例可以在指定的机器上以独立排他的方式运行。但排他的方式运行只是一个临时方案。更多的时候,测试或者被测系统必须重构,彻底解决在单一资源方面的依赖。下面的做法可以帮助解决一些问题。
在测试执行系统中,让每个测试用例获取一个未被使用的端口,并让被测系统动态地绑定到这个端口上。
在测试执行之前,为每一个测试用例在临时目录下创建目录和文件,并使用独一无二的目录名。
每个测试运行在自己的数据库实例之上,使用与环境隔离的目录和端口。这些都由测试执行系统来控制。
Google全力维护其测试执行系统,甚至文档也非常详尽。这些文档存放在Google的“测试百科全书”中,这里有对其运行使用的资源所做的最终解释。“测试百科全书”有点像IEEE RFC(译注:IEEE定义的正式标准,RFC是Request for Comment的简写),明确使用“必须”或“应该”这样的字样,并在其中详细解释了角色、测试用例职责、测试执行者、集群系统、运行时刻的libc、文件系统等。
许多Google工程师感觉没有太多必要去阅读“测试百科全书”,他们从其他人身上了解这方面的知识,或者从不断的试验错误中得到教训,也在代码评审中收到改进反馈。他们不知道,公用测试执行环境能够服务于所有Google项目,其中背后的细节都已在文档之中。他们也不知道,在公用执行环境中的运行结果为什么与工作机器上的运行结果一致,背后的原因也都在文档里了。对于测试执行系统平台的使用用户来说,细节实现是透明的。所有的一切都能正常工作。
测试的速度与规模
by Pooja Gupta, Mark Ivey, and John Penix
在开发过程中,持续集成系统在保证软件正常工作方面发挥着重要作用。多数持续集成系统按照下面基本步骤工作。
(1)得到最新的代码。
(2)运行所有的测试。
(3)报告运行结果。
(4)重复以上(1)~(3)步。
在代码规模较小时,上述过程可以很容易地工作,代码变化不多,测试也可以很快就运行结束。随着代码库中的代码不断增加,这样一个系统的效率就会下降。每次全新地取出干净代码再运行耗时较大,多次变更被勉强地塞进一次测试运行之中。如果运行失败,对于团队来说,发现定位这个错误并回滚,将成为了一个漫长且易错的过程。
Google的软件开发过程在速度和规模上日新月异。Google代码库每分钟都会收到多于20次的变更申请,50%的文件每个月都会发生变化。每个产品的发布从“头”开始就依赖于自动化测试去验证产品功能。发布的频率根据产品团队不同,也从每天数次到几周一次不等。
拥有如此庞大且不停变化的代码库,为了保持构建始终保持“绿色”,就需要花费大量的时间做维护。一个持续集成系统,如果测试失败,应该可以提供具体哪次代码变更导致失败,而不是给出一堆可疑的变更列表,或消耗较长时间做二分查找从而定位具体哪次代码变更导致了问题的发生。为了精确定位哪次代码变更导致测试用例运行失败,我们可以针对每次代码变更运行所有的测试,但这样做的代价也是非常昂贵的。
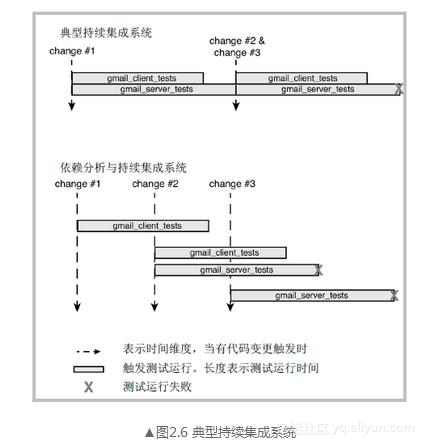
为了解决这个问题,我们对持续集成系统做了优化,如图2.6所示。利用依赖分析技术寻找所有可能受影响的模块,针对一个代码变更只运行受影响模块的测试。这个系统在Google云计算平台上构建,使得许多构建可以并发执行,并在代码变更提交的时候立刻运行可能受影响模块的测试。
这里用一个示例来说明我们的系统是如何提供更快反馈的,与传统持续构建系统相比,我们的反馈内容也会更加精准。在这个示例中,我们使用了两个测试(gmail_client_tests, gmail_server_tests)和三个可能会影响这两个测试的代码变更(change #1, #2, #3)。gmail_server_tests运行失败由变更#2导致,而传统的持续集成系统只能告诉我们可能是变更#2或变更#3引起。通过使用并发构建,我们不必等构建测试运行全部结束就可以开始新的测试。依赖分析针对每一次代码变更会限制执行测试次数,所以此例中,测试执行的总数与之前是相同的。
图像说明文字
1.大型测试
大型测试的优点和缺点包括如下。
测试最根本最重要的:在考虑外部系统的情况下应用系统是如何工作的。
由于对外部系统有依赖,因此它们是非确定性的。
很宽的测试范畴意味着如果测试运行失败,寻找精准失败根源就会比较困难。
测试数据的准备工作会非常耗时。
大型测试是较高层次的操作,如果想要走到特定的代码路径区域是不切实际的,而这一部分却是小型测试的专长。
2.中型测试
中型测试的优点和缺点包括如下。
由于不需要使用mock技术,且不受运行时刻的限制,因此该测试是从大型测试到小型测试之间的一个过渡。
因为它们运行速度相对较快,所以可以频繁地运行它们。
它们可以在标准的开发环境中运行,因此开发人员也可以很容易运行它们。
它们依赖外部系统。
由于对外部系统有依赖,因此它们本身就有不确定性。
它们的运行速度没有小型测试快。
3.小型测试
小型测试的优点和缺点包括如下。
为了更容易地就被测试到,代码应清晰干净、函数规模较小且重点集中。为了方便模拟,系统之间的接口需要有良好的定义。
由于它们可以很快运行完毕,因此在有代码变更发生的时候就可以立刻运行,从而可以较早地发现缺陷并提供及时的反馈。
在所有的环境下它们都可以可靠地运行。
它们有较小的测试范围,这样可以很容易地做边界场景与错误条件的测试,例如一个空指针。
它们有特定的范畴,可以很容易地隔离错误。
不要做模块之间的集成测试,这是其他类型的测试要做的事情(中型测试)。
有时候对子系统的模拟是有难度的。
使用mock或fake环境,可以不与真实的环境同步。
小型测试带来优秀的代码质量、良好的异常处理、优雅的错误报告;大中型测试带来整体产品质量和数据验证。单一的测试类型不能解决所有项目需求。正是由于这个原因,Google项目维护着一个不同测试类型之间的健康比例。对于一个项目,如果全部使用大型的端到端自动化测试是错误的,全部使用小型的单元测试同样也是错误的。
**注意**
小型测试带来优秀的代码质量、良好的异常处理、优雅的错误报告;大中型测试会带来整体产品质量和数据验证。
检验一个项目里小型测试、中型测试和大型测试之间的比率是否健康,一个好办法是使用代码覆盖率。测试代码覆盖率可以针对小型测试、中大型测试分别单独产生报告。覆盖率报告会针对不同的项目展示一个可被接受的覆盖率结果。如果中大型测试只有20%的代码覆盖率,而小型测试有近100%的覆盖率,则说明这个项目缺乏端到端的功能验证。如果结果数字反过来了,则说明这个项目很难去做升级扩展和维护,由于小型测试较少,就需要大量的时间消耗在底层代码调试查错上。Google工程师可以使用构建与运行测试时使用的工具,来产生并查看测试覆盖率结果,只需要在命令行中额外增加一个选项即可。覆盖率结果会存储在云端,任何工程师在公司内网络环境下都可以通过浏览器查看这些报告。
Google有许多不同类型的项目,这些项目对测试的需求也不同,小型测试、中型测试和大型测试之间的比例随着项目团队的不同而不同。这个比例并不是固定的,总体上有一个经验法则,即70/20/10原则:70%是小型测试,20%是中型测试,10%是大型测试。如果一个项目是面向用户的,拥有较高的集成度,或者用户接口比较复杂,他们就应该有更多的中型和大型测试;如果是基础平台或者面向数据的项目,例如索引或网络爬虫,则最好有大量的小型测试,中型测试和大型测试的数量要求会少很多。
另外有一个用来监视测试覆盖率的内部工具是Harvester。Harvester是一个可视化的工具,可以记录所有项目的CL历史,并以图形化的方式展示,例如测试代码和CL中新增代码的比率、代码变更的多少、按时间的变化频率、按照开发人员的变化次数,等等。这些图形的目的是展示随着时间的变化,测试的变化趋势是怎样的。
**2.1.14 测试运行要求**
无论测试规模的大小是什么,由于Google的测试执行系统是一个公用环境,因此就要求测试本身满足下面几个条件。
每个测试和其他测试之间都是独立的,使它们就能够以任意顺序来执行。
测试不做任何数据持久化方面的工作。在这些测试用例离开测试环境的时候,要保证测试环境的状态与测试用例开始执行之前的状态是一样的。
这两个要求比较简单也很容易理解,但必须严格遵守。测试本身会尽可能地遵守要求,但被测系统却有可能违背原则;保存数据或修改环境配置信息。幸运的是,Google测试执行环境提供了许多特性可以确保这些要求比较容易就得到满足。
由于测试用例有独立运行的要求,在运行时刻,工程师通过设置一个标记就能以随机的顺序来执行它们。这样也可以找到那些对执行顺序有要求的用例。总之,“任意顺序”意味着可以并发执行用例。测试执行系统可以选择在同一个机器上同时执行两个用例,但如果每个用例都要求独占系统某些资源,其中一个用例就可能运行失败。例如以下几种情况。
两个测试都要绑定同一个端口,用以接收来自网络的数据。
两个测试需要在同一个路径下创建相同的目录。
一个测试希望创建并使用一个数据库表,而另外一个测试想删除这个数据库表。
这种类型的冲突,不仅会导致自己的用例运行失败,而且可能会导致测试执行系统中其他正在运行的用例也失败,即便另外的用例已经遵守了规则。测试执行系统可以找出这些测试用例,并通知给相应的用例负责人。另外,通过设置一个特殊标记,用例可以在指定的机器上以独立排他的方式运行。但排他的方式运行只是一个临时方案。更多的时候,测试或者被测系统必须重构,彻底解决在单一资源方面的依赖。下面的做法可以帮助解决一些问题。
在测试执行系统中,让每个测试用例获取一个未被使用的端口,并让被测系统动态地绑定到这个端口上。
在测试执行之前,为每一个测试用例在临时目录下创建目录和文件,并使用独一无二的目录名。
每个测试运行在自己的数据库实例之上,使用与环境隔离的目录和端口。这些都由测试执行系统来控制。
Google全力维护其测试执行系统,甚至文档也非常详尽。这些文档存放在Google的“测试百科全书”中,这里有对其运行使用的资源所做的最终解释。“测试百科全书”有点像IEEE RFC(译注:IEEE定义的正式标准,RFC是Request for Comment的简写),明确使用“必须”或“应该”这样的字样,并在其中详细解释了角色、测试用例职责、测试执行者、集群系统、运行时刻的libc、文件系统等。
许多Google工程师感觉没有太多必要去阅读“测试百科全书”,他们从其他人身上了解这方面的知识,或者从不断的试验错误中得到教训,也在代码评审中收到改进反馈。他们不知道,公用测试执行环境能够服务于所有Google项目,其中背后的细节都已在文档之中。他们也不知道,在公用执行环境中的运行结果为什么与工作机器上的运行结果一致,背后的原因也都在文档里了。对于测试执行系统平台的使用用户来说,细节实现是透明的。所有的一切都能正常工作。
测试的速度与规模
by Pooja Gupta, Mark Ivey, and John Penix
在开发过程中,持续集成系统在保证软件正常工作方面发挥着重要作用。多数持续集成系统按照下面基本步骤工作。
(1)得到最新的代码。
(2)运行所有的测试。
(3)报告运行结果。
(4)重复以上(1)~(3)步。
在代码规模较小时,上述过程可以很容易地工作,代码变化不多,测试也可以很快就运行结束。随着代码库中的代码不断增加,这样一个系统的效率就会下降。每次全新地取出干净代码再运行耗时较大,多次变更被勉强地塞进一次测试运行之中。如果运行失败,对于团队来说,发现定位这个错误并回滚,将成为了一个漫长且易错的过程。
Google的软件开发过程在速度和规模上日新月异。Google代码库每分钟都会收到多于20次的变更申请,50%的文件每个月都会发生变化。每个产品的发布从“头”开始就依赖于自动化测试去验证产品功能。发布的频率根据产品团队不同,也从每天数次到几周一次不等。
拥有如此庞大且不停变化的代码库,为了保持构建始终保持“绿色”,就需要花费大量的时间做维护。一个持续集成系统,如果测试失败,应该可以提供具体哪次代码变更导致失败,而不是给出一堆可疑的变更列表,或消耗较长时间做二分查找从而定位具体哪次代码变更导致了问题的发生。为了精确定位哪次代码变更导致测试用例运行失败,我们可以针对每次代码变更运行所有的测试,但这样做的代价也是非常昂贵的。
为了解决这个问题,我们对持续集成系统做了优化,如图2.6所示。利用依赖分析技术寻找所有可能受影响的模块,针对一个代码变更只运行受影响模块的测试。这个系统在Google云计算平台上构建,使得许多构建可以并发执行,并在代码变更提交的时候立刻运行可能受影响模块的测试。
这里用一个示例来说明我们的系统是如何提供更快反馈的,与传统持续构建系统相比,我们的反馈内容也会更加精准。在这个示例中,我们使用了两个测试(gmail_client_tests, gmail_server_tests)和三个可能会影响这两个测试的代码变更(change #1, #2, #3)。gmail_server_tests运行失败由变更#2导致,而传统的持续集成系统只能告诉我们可能是变更#2或变更#3引起。通过使用并发构建,我们不必等构建测试运行全部结束就可以开始新的测试。依赖分析针对每一次代码变更会限制执行测试次数,所以此例中,测试执行的总数与之前是相同的。
图像说明文字
 持续集成系统使用构建系统中的构建依赖规则。在这个规则中描述了代码是如何编译、数据文件是怎样集成在一起成为应用程序的,以及测试如何运行等信息。这个构建规则中详细定义了构建所需的输入输出。持续集成系统在内存中维护了图2.7所示的一个构建依赖图,并随着代码的变更而时刻保持最新状态。如果有代码变更提交,可以很快就计算得知哪些依赖模块可能会受到影响(直接或间接),然后重新运行构建测试,获得最新执行状态。让我们再看一个例子。
持续集成系统使用构建系统中的构建依赖规则。在这个规则中描述了代码是如何编译、数据文件是怎样集成在一起成为应用程序的,以及测试如何运行等信息。这个构建规则中详细定义了构建所需的输入输出。持续集成系统在内存中维护了图2.7所示的一个构建依赖图,并随着代码的变更而时刻保持最新状态。如果有代码变更提交,可以很快就计算得知哪些依赖模块可能会受到影响(直接或间接),然后重新运行构建测试,获得最新执行状态。让我们再看一个例子。
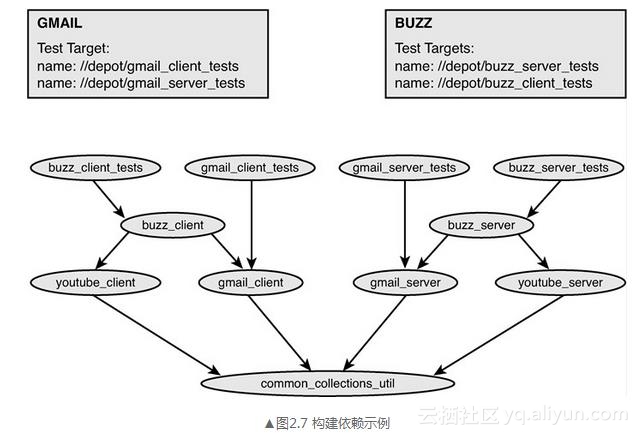 我们观察两个独立的代码变更,它们发生在依赖树的不同深度上,通过分析来决定哪些测试会受影响。这些受影响的测试就是需要运行的最小集合测试,它们用来保证GMAIL和BUZZ项目的构建保持“绿色”。
1.案例:在通用库上的代码变更
对于第一个场景,考虑common_collection_util部分的代码修改,如图2.8所示。
我们观察两个独立的代码变更,它们发生在依赖树的不同深度上,通过分析来决定哪些测试会受影响。这些受影响的测试就是需要运行的最小集合测试,它们用来保证GMAIL和BUZZ项目的构建保持“绿色”。
1.案例:在通用库上的代码变更
对于第一个场景,考虑common_collection_util部分的代码修改,如图2.8所示。
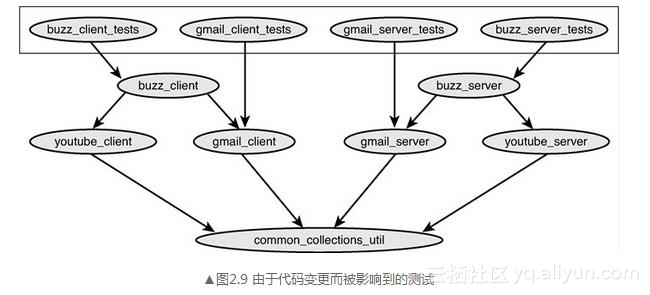
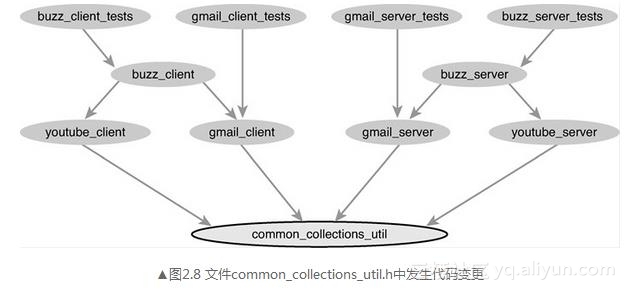 当这个代码变更CL提交时,我们沿着依赖图向上找到所有依赖于它的测试。当这个查找结束时(实际上只需要一瞬间),我们发现所有的测试都需要运行。在运行之后,根据运行结果更新项目的构建状态,如图2.9所示。
当这个代码变更CL提交时,我们沿着依赖图向上找到所有依赖于它的测试。当这个查找结束时(实际上只需要一瞬间),我们发现所有的测试都需要运行。在运行之后,根据运行结果更新项目的构建状态,如图2.9所示。
 2.案例:在一个依赖项目上的代码变更
对于第二个场景,我们来看如果在youtube_client的部分做一些代码变更,如图2.10所示。
2.案例:在一个依赖项目上的代码变更
对于第二个场景,我们来看如果在youtube_client的部分做一些代码变更,如图2.10所示。
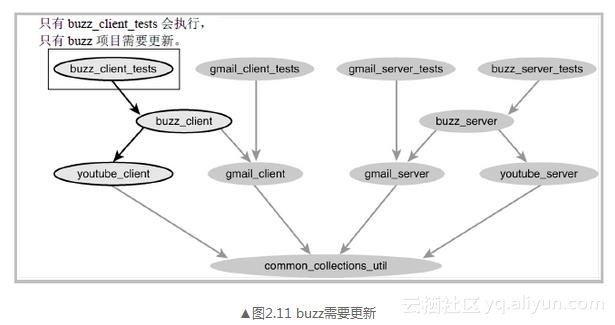
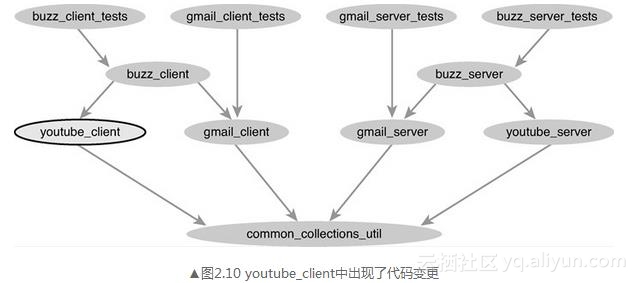 经过展开统一的分析之后,我们发现只有buzz_client_tests受到影响,只有buzz项目的状态需要更新,如图2.11所示。
在这个示例中,我们展示了如何优化每次代码变更后触发的测试执行次数。对于一个项目来说,并没有牺牲结果的准确度。每次运行较少的测试,可以让我们有机会针对每一次代码变更都运行其所有可能受影响的测试。对开发人员来说,排查导致构建失败的代码变更会更容易一些。
在持续集成系统中使用更加智能的分析工具与云计算平台,让整个运行过程更加迅速和稳定。当我们持续不断地在改进这个系统时,成千上万的Google项目已经在使用这套平台了。这样做不但有利于加快项目进度,而且进度对于用户也是可见的。
经过展开统一的分析之后,我们发现只有buzz_client_tests受到影响,只有buzz项目的状态需要更新,如图2.11所示。
在这个示例中,我们展示了如何优化每次代码变更后触发的测试执行次数。对于一个项目来说,并没有牺牲结果的准确度。每次运行较少的测试,可以让我们有机会针对每一次代码变更都运行其所有可能受影响的测试。对开发人员来说,排查导致构建失败的代码变更会更容易一些。
在持续集成系统中使用更加智能的分析工具与云计算平台,让整个运行过程更加迅速和稳定。当我们持续不断地在改进这个系统时,成千上万的Google项目已经在使用这套平台了。这样做不但有利于加快项目进度,而且进度对于用户也是可见的。