一、背景说明
最近有位朋友咨询说为何如此多线程处于Searching rows for update,当时看到这个状态的第一反应就是锁,这里暂且抛开锁不谈,谈一谈为何出现Searching rows for update
二、实验环境:
root@mysqldb 10:15: [xucl]> show create table test1\G
*************************** 1. row ***************************
Table: test1
Create Table: CREATE TABLE `test1` (
`a` int(11) NOT NULL,
`b` varchar(20) DEFAULT NULL,
PRIMARY KEY (`a`),
KEY `b` (`b`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
1 row in set (0.00 sec)
root@mysqldb 10:15: [xucl]> select * from test1;
+---+------+
| a | b |
+---+------+
| 2 | b |
| 3 | c |
| 1 | ccc |
+---+------+
3 rows in set (0.00 sec)
大概出现的状态如下所示:

三、初探过程
简单做了pstack,其中id=2的线程堆栈如下:
从堆栈很明显可以看出,该线程处于锁等待的状态,但为何处于Searching rows for update并没有给出明确暗示,可以看到调用的顺序是
mysql_parse
mysql_execute_command
Sql_cmd_update::execute_command
mysql_update
...
ha_innobase::index_read
...
lock_wait_suspend_thread
...
废话不多说,咱们直接从mysql_update切入,该入口函数位置在sql_update.cc
bool mysql_update(THD *thd,
List &fields,
List &values,
ha_rows limit,
enum enum_duplicates handle_duplicates,
ha_rows *found_return, ha_rows *updated_return)
{
...
if (used_key_is_modified || order)
{
/*
When we get here, we have one of the following options:
A. used_index == MAX_KEY
This means we should use full table scan, and start it with
init_read_record call
B. used_index != MAX_KEY
B.1 quick select is used, start the scan with init_read_record
B.2 quick select is not used, this is full index scan (with LIMIT)
Full index scan must be started with init_read_record_idx
*/
if (used_index == MAX_KEY || (qep_tab.quick()))
error= init_read_record(&info, thd, NULL, &qep_tab, 0, 1, FALSE);
else
error= init_read_record_idx(&info, thd, table, 1, used_index, reverse);
if (error)
goto exit_without_my_ok;
THD_STAGE_INFO(thd, stage_searching_rows_for_update);
ha_rows tmp_limit= limit;
}
...
debug结果如下:

这里判断条件为used_index是否等于MAX_KEY,其中MAX_KEY为常量,used_index的定义如下:
used_index= get_index_for_order(order, &qep_tab, limit, &need_sort, &reverse);
这里的判断就比较复杂了,本人水平有限,暂时未深入理解优化器的部分,也不展开说明,源码位置在sql_select.cc,有兴趣的同学可以深入研究一下
函数is_key_used定义如下:无锡看妇科的医院 http://www.ytsgfk120.com/
bool is_key_used(TABLE *table, uint idx, const MY_BITMAP *fields)
{
bitmap_clear_all(&table->tmp_set); //清空tmp_set位图
table->mark_columns_used_by_index_no_reset(idx, &table->tmp_set); //这里设置位图
const bool overlapping= bitmap_is_overlapping(&table->tmp_set, fields); //比较索引位置和修改位置是否重合
// Clear tmp_set so it can be used elsewhere
bitmap_clear_all(&table->tmp_set);
if (overlapping)
return 1; //如果重合返回1
...
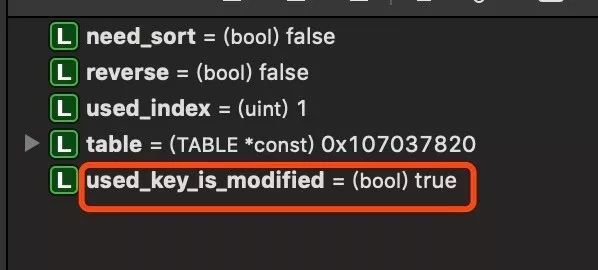
看到debug的结果变量,used_key_is_modified为true,那么进入如下判断

然后就进入stage_searching_rows_for_update状态,也就是我们一开始在show processlist中看到的状态

而如果我们修改的是其他字段,那么进入的状态便是Updating,对应的源码为
if (used_key_is_modified || order)
{
...
}
...
thd->count_cuted_fields= CHECK_FIELD_WARN;
thd->cuted_fields=0L;
THD_STAGE_INFO(thd, stage_updating);
...
废话不多说,我们来测试验证一下THD_STAGE_INFO(thd, stage_updating);处打上断点,然后更新数据

实验结果符合预期
其他测试结果:
case结果
update主键直接进入stage_updating
update唯一索引直接进入stage_updating
update普通二级索引+limit进入stage_searching_rows_for_update,完成后进入stage_updating
四、总结
最后总结一下:
Searching rows for update状态出现的要求比较严格,当进行数据更新时,如果更新的字段为当前执行计划用到的索引,并且该索引属于普通二级索引(不能是主键也不能是唯一索引),那么就会出现Searching rows for update状态,正因为出现了锁等待,所以能看到这种状态
如果不是,那么直接进入Updating状态,这个状态也就是我们经常看到的状态
出现如上两种状态并且持续时间长,并不是造成数据库性能下降的根本原因,而应该考虑其他原因,如本案例中的锁等待问题