数据库知识点
https://blog.csdn.net/zsq520520/article/details/68954646
https://blog.csdn.net/Hectorhua/article/details/13767361
聚集索引与非聚集索引 https://www.cnblogs.com/s-b-b/p/8334593.html
内连接和外连接的区别
- 内连接(自然连接): 只有两个表相匹配的行才能在结果集中出现
- 外连接: 包括
- 左外连接(左边的表不加限制)
- 右外连接(右边的表不加限制)
- 全外连接(左右两表都不加限制)
超键、候选键、主键区别?
https://www.cnblogs.com/lumnm/archive/2010/11/08/1871783.html
- 超键(super key):在关系中能唯一标识元组的属性集称为关系模式的超键
- 候选键(candidate key):不含有多余属性的超键称为候选键
- 主键(primary key):用户选作元组标识的一个候选键程序主键
- 外键:在一个表中存在的另一个表的主键称此表的外键。
比如一个小范围的所有人,没有重名的,考虑以下属性 身份证 姓名 性别 年龄
身份证唯一,所以是一个超键
姓名唯一,所以是一个超键
(姓名,性别)唯一,所以是一个超键
(姓名,性别,年龄)唯一,所以是一个超键
--这里可以看出,超键的组合是唯一的,但可能不是最小唯一的
身份证唯一,而且没有多余属性,所以是一个候选键
姓名唯一,而且没有多余属性,所以是一个候选键
--这里可以看出,候选键是没有多余属性的超键
考虑输入查询方便性,可以选择 身份证 为主键
也可以 考虑习惯 选择 姓名 为主键
--主键是选中的一个候选键
主键与唯一索引
所谓主键(primary key)就是能够唯一标识表中某一行的属性或属性组,一个表只能有一个主键,但可以有多个候选索引。因为主键可以唯一标识某一行记录,所以可以确保执行数据更新、删除的时候不会出现张冠李戴的错误。主键除了上述作用外,常常与外键构成参照完整性约束,防止出现数据不一致。数据库在设计时,主键起到了很重要的作用。创建唯一索引的目的不是为了提高访问速度,而只是为了避免数据出现重复。唯一索引可以有多个但索引列的值必须唯一,索引列的值允许有空值。如果能确定某个数据列将只包含彼此各不相同的值,在为这个数据列创建索引的时候就应该使用关键字UNIQUE,把它定义为一个唯一索引。
- 主键一定是唯一性索引,唯一性索引并不一定就是主键。
- 主键可以保证记录的唯一和主键域非空,数据库管理系统对于主键自动生成唯一索引,所以主键也是一个特殊的索引。
- 一个表中可以有多个唯一性索引,但只能有一个主键。
- 主键列不允许空值,而唯一性索引列允许空值。
- 索引可以提高查询的速度。
什么是事务?
事务是数据库中一个单独的执行单元,它通常由高级数据库操作语言(例如SQL)或编程语言(C++,Java)编写的用户程序的执行所引起。当在数据库中更改数据成功时,在事务中更改的数据便会提交不再改变。否则,事务就取消或者回滚,更改无效。
而一个逻辑工作单元要成为事务,就必须满足ACID属性
- A:原子性(Atomicity) 事务中的操作要么都不做,要么就全做。不允许事务部分地完成
- C:一致性(Consistency) 事务执行的结果必须是从数据库从一个一致性状态转换到另一个一致性状态。由用户来负责,由并发控制机制来实现,例如,银行转账,转账前后两个账户的金额之和应该保持不变。
- I:隔离性(Isolation) 一个事务的执行不能被其他事务干扰 。实现隔离性是解决临时更新与消除级联回滚问题的一种方式(级联回滚:因一个事务故障导致一系列事务回滚的方式)
- D:持久性(Durability) 一个事务一旦提交,它对数据库中数据的改变就应该是永久性的 。一般通过数据库备份与恢复来保证。
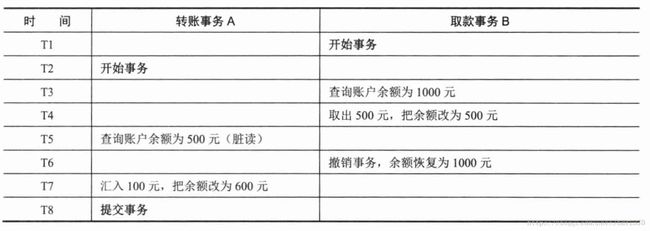
脏读 不可重复读 幻读
- 脏读:在一个事务中读取到另一个事务没有提交的数据
- 不可重复读:在一个事务中,两次查询的结果不一致(针对的update操作)
- 虚读(幻读):在一个事务中,两次查询的结果不一致(针对的insert操作)
---------------------
1.脏读:
脏读就是指当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。
2.不可重复读:
是指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的的数据可能是不一样的。这样就发生了在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。(即不能读到相同的数据内容)
例如,一个编辑人员两次读取同一文档,但在两次读取之间,作者重写了该文档。当编辑人员第二次读取文档时,文档已更改。原始读取不可重复。如果只有在作者全部完成编写后编辑人员才可以读取文档,则可以避免该问题。
3.幻读:
是指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好象发生了幻觉一样。
例如,一个编辑人员更改作者提交的文档,但当生产部门将其更改内容合并到该文档的主复本时,发现作者已将未编辑的新材料添加到该文档中。如果在编辑人员和生产部门完成对原始文档的处理之前,任何人都不能将新材料添加到文档中,则可以避免该问题。
原文:https://blog.csdn.net/JIESA/article/details/51317164
---------------------
原文:https://blog.csdn.net/JIESA/article/details/51317164
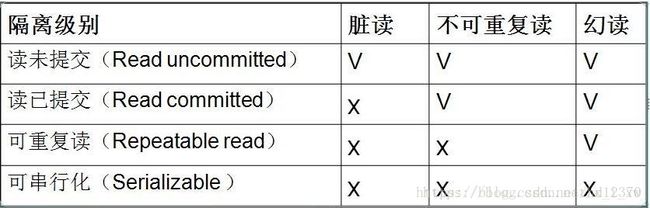
通过设置数据库的隔离级别来避免上面的问题(理解)
- read uncommitted 读未提交 上面的三个问题都会出现
- read committed 读已提交 可以避免脏读的发生
- repeatable read 可重复读 可以避免脏读和不可重复读的发生
- serializable 串行化 可以避免所有的问题
不可重复读和幻读的区别是:
- 前者是指读到了已经提交的事务的更改数据(修改或删除),后者是指读到了其他已经提交事务的新增数据。
对于这两种问题解决采用不同的办法:
- 防止读到更改数据,只需对操作的数据添加行级锁,防止操作中的数据发生变化;
- 防止读到新增数据,往往需要添加表级锁,将整张表锁定,防止新增数据(oracle采用多版本数据的方式实现)。
https://blog.csdn.net/starlh35/article/details/76445267
范式
https://www.cnblogs.com/lca1826/p/6601395.html
第一范式(1NF):属性不可分。
第二范式(2NF):符合1NF,并且,非主属性完全依赖于码。(注意是完全依赖不能是部分依赖,设有函数依赖W→A,若存在XW,有X→A成立,那么称W→A是局部依赖,否则就称W→A是完全函数依赖)
第三范式(3NF):符合2NF,并且,消除传递依赖(也就是每个非主属性都不传递依赖于候选键,判断传递函数依赖,指的是如果存在"A → B → C"的决定关系,则C传递函数依赖于A。)
BC范式(BCNF):符合3NF,并且,主属性不依赖于主属性(也就是不存在任何字段对任一候选关键字段的传递函数依赖)
视图
http://www.cnblogs.com/zzwlovegfj/archive/2012/06/23/2559596.html
视图是由查询结果形成的一张虚拟表。如果某个查询结果出现的非常频繁,也就是要经常拿这个查询结果来做子查询
create view 视图名 as select 语句;
- ①简化查询语句
- ②可以进行权限控制
- ③大数据分表时可以用到
索引
MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
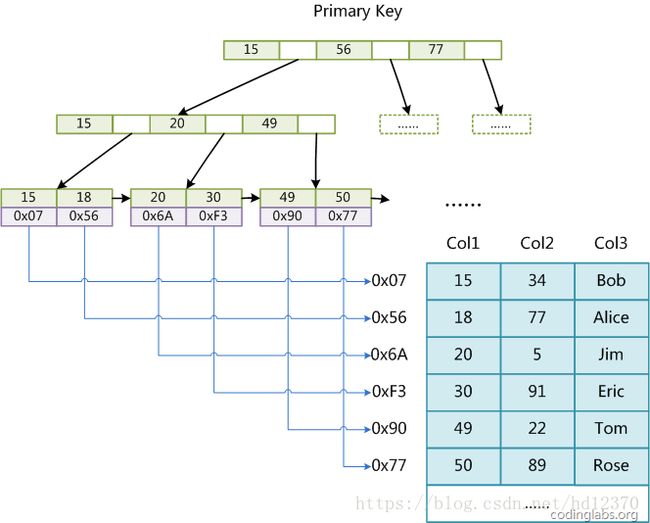
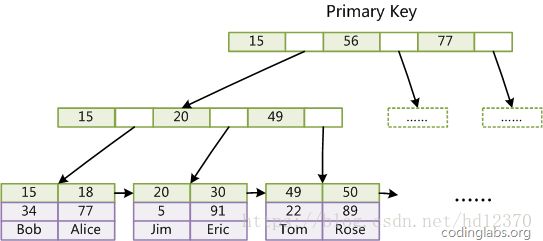
(图inndb主键索引)是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。
InnoDB索引和MyISAM索引的区别:
- 一是主索引的区别,InnoDB的数据文件本身就是索引文件。而MyISAM的索引和数据是分开的。
- 二是辅助索引的区别:InnoDB的辅助索引data域存储相应记录主键的值而不是地址。而MyISAM的辅助索引和主索引没有多大区别。
数据库优化的思路
1.SQL语句优化
1)应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
2)应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0
3)很多时候用 exists 代替 in 是一个好的选择
4)用Where子句替换HAVING 子句因为HAVING 只会在检索出所有记录之后才对结果集进行过滤
2.索引优化
看上文索引
3.数据库结构优化
1)范式优化: 比如消除冗余(节省空间。。)
2)反范式优化:比如适当加冗余等(减少join)
3)拆分表:
分区将数据在物理上分隔开,不同分区的数据可以制定保存在处于不同磁盘上的数据文件里。这样,当对这个表进行查询时,只需要在表分区中进行扫描,而不必进行全表扫描,明显缩短了查询时间,另外处于不同磁盘的分区也将对这个表的数据传输分散在不同的磁盘I/O,一个精心设置的分区可以将数据传输对磁盘I/O竞争均匀地分散开。对数据量大的时时表可采取此方法。可按月自动建表分区。
4)拆分其实又分垂直拆分和水平拆分:
案例:
简单购物系统暂设涉及如下表:
1.产品表(数据量10w,稳定)
2.订单表(数据量200w,且有增长趋势)
3.用户表 (数据量100w,且有增长趋势)
以mysql为例讲述下水平拆分和垂直拆分,mysql能容忍的数量级在百万静态数据可以到千万
垂直拆分:
解决问题:表与表之间的io竞争
不解决问题:单表中数据量增长出现的压力
方案:
把产品表和用户表放到一个server上
订单表单独放到一个server上
水平拆分:
解决问题:单表中数据量增长出现的压力
不解决问题:表与表之间的io争夺
方案:
用户表通过性别拆分为男用户表和女用户表
订单表通过已完成和完成中拆分为已完成订单和未完成订单
产品表 未完成订单放一个server上
已完成订单表盒男用户表放一个server上
女用户表放一个server上(女的爱购物 哈哈)