MySQL单表查询总结
目录
一.where
1.模糊查询
2.关系运算符
3.逻辑运算符
4.in
5.is null/is not null
6.between and
二.排序
三.聚合函数、分组
1.聚合函数
2.分组
四.having
五.单行函数
本篇中的查询操作均使用以下创建的这个student表:
create table student(
id char(36) primary key,
name varchar(8) not null,
age int(3) default 0,
mobile char(11),
address varchar(150)
);
insert into student
values ('9b4435ec-372c-456a-b287-e3c5aa23dff4','张三',24,'12345678901','北京海淀');
insert into student
values ('a273ea66-0a42-48d2-a17b-388a2feea244','李%四',10,'98765432130',null);
insert into student
values ('eb0a220a-60ae-47b6-9e6d-a901da9fe355','张李三',11,'18338945560','安徽六安');
insert into student
values ('6ab71673-9502-44ba-8db0-7f625f17a67d','王_五',28,'98765432130','北京朝阳区');
insert into student
values ('0055d61c-eb51-4696-b2da-506e81c3f566','王_五%%',11,'13856901237','吉林省长春市宽平区');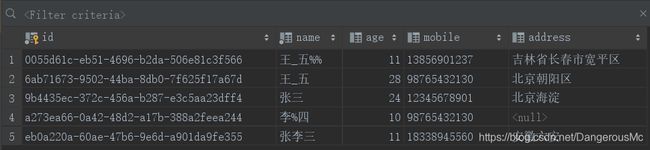
一.where
1.模糊查询
where最常规的用法就是精确查询:where 目标字段=‘目标值’
当不知道目标的确切值的时候,可以使用where的模糊查询,以下是模糊查询的用法:
select * from student where name like '王%';
注意:%代表匹配一次或多次,_必须匹配一次,也就是说%意味着“王”后面可以有多个字符,如果用_意味着“王”后面只能有一个字符。
但如果要查找的字符为%或_时,就需要使用escape:
select * from student where name like '%A%%' escape 'A';
其中,在%前随意加一个字符,然后在模糊查询的后面加上escape ‘该字符’
2.关系运算符
和编程语言一样,where不只可以使用=,还可以使用<=,>=,<,>:
select * from student where age >= 11; 
3.逻辑运算符
and、or、not:
select * from student where age >= 11 and address like '北京%';
4.in
in(a,b)意味着查询该字段的值为a或b其中一个的数据:
select * from student where age in(28,24);它等价于:
select * from student where age =28 or age=24; 
5.is null/is not null
is null是查询某字段为空的字段,is not null是查询某字段不为空的字段:
select * from student where address is not null;
6.between and
between and用于查询某字段的值在此区间中的数据:
select * from student where age between 11 and 28;
这里要注意一点:between and中必须是小数据在前,大数据在后,否则不会查出任何结果。
二.排序
对表中的数据按某一字段进行排序,使用order by语句:
select * from student order by age;
我们可以看到查询出来的该表是以升序排的,因为order by语句默认在后面有一个asc,是升序,而如果想降序排列,则需在后面手动加上desc:
select * from student order by age desc; 
order by还可以对多个字段进行排序,规则是先对第一个字段进行排序,当第一个字段中出现相同的值的时候,再以第二个字段进行排序,以此类推:
select * from student order by age asc,mobile desc;
当被排序的字段是字符串的时候,则排序规则是以ASC码的顺序靠前的为小,靠后的为大:
select * from student order by name asc; 
但是我们可以看到结果并没有按照name字段的顺序排, 这是因为对汉字排序时要加上如下的语句:
select * from student order by convert(name USING gbk) asc; 
三.聚合函数、分组
1.聚合函数
聚合函数,就是对表中的多行数据进行操作的函数,介绍几种比较常用的聚合函数:
①count()
count函数用来统计某字段共含有的列数:
select count(id) from student;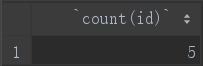
②sum()
sum函数用来计算某字段的所有值的加和:
select sum(age) from student; 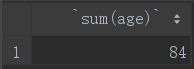
③avg()
avg函数用来计算某字段所有值的平均值:
select avg(age) age from student;它等价于:
select sum(age)/count(id) as age from student; 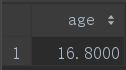
④max()min()
这两个函数就是用来取某字段的最大值和最小值的:
select max(age),min(age)from student;
2.分组
group by语句用于分组,且常和聚合函数一起使用,将被分组的字段相同的分为一组,聚合函数可以对其做相应的统计:
select age,count(id) from student group by age;
这里要注意一点,如果使用group by,则select字段列表只能是聚合函数或者分组字段,因为其余的字段并没有进行分组操作,会造成数据的丢失或混乱:
select name,age,count(id) from student group by age; 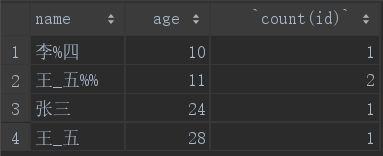
四.having
having和where的作用很相似,但having后面接的只能是聚合函数语句:
select age,count(id) from student group by age having count(id)>1; 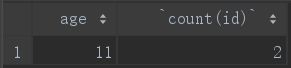
where和having的区别见博客: MySQL数据库中where、having、order by、group by
五.单行函数
单行函数用来对单行数据进行一系列操作,各行数据之间是不相关的。
1.length()
length函数用来求某一字段的字符串存储长度,其中汉字是占三个单位长度,符号占一个单位长度:
select name,length(name) from student; 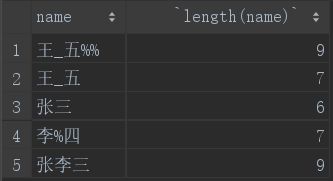
该函数还有一个衍生函数就是求某一字段的字符串的字符个数:
select name,char_length(name) from student; 
2.concat()
concat函数用于将字段拼接,用法如下,但是当参数列表中的字段有字段的值为null,则改行的拼接结果即为null:
select concat(id,',',name,',',mobile,',',address) as info from student; 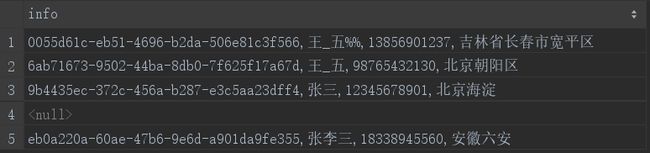
该函数还有一个衍生函数就是当拼接的时候要在相邻两个字段中加入某一符号时,可以简化拼接过程的函数,而且就算参数列表中有字段的值为null,查询结果还是会把该行中其他字段的值打印出来:
select concat_ws(',',id,name,mobile,address) info from student; 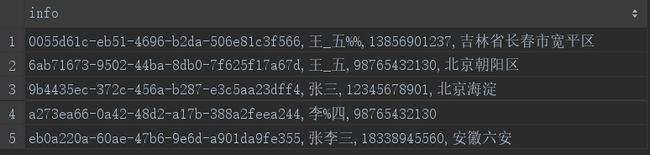
3.trim()
trim函数的作用就是将字段值中两端的空格去掉。假如将表中数据的张三前面加上五个空格,如下:

这时使用trim函数:
select trim(name) from student;
4.substr()
substr函数用于截取字符串,如果函数中传入两个参数,则第一个参数指定截取的字段,第二个参数指定从第几个字符开始截取:
select substr(name,2) from student; 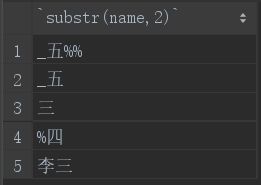
如果函数中出入三个参数,则第三个参数指定一共截取几个字符:
select substr(name,2,1) from student; 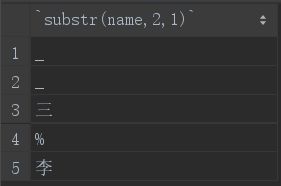
5.replace
replace用于对目标字段的字符串做替换,用法如下,将所有字符串中的所有‘_’替换成‘1’:
select replace(name,'_','1') from student;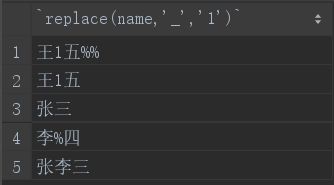
6.reverse
reverse函数作用是将字符串变为倒序的:
select name,reverse(name) from student; 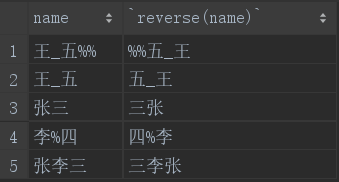
7.strcmp
和c语言中的strcmp函数一样,用于比较两个字符串的大小,比较规则依旧是ASC码:
select strcmp('a','b'); 
8.mod
因为%已经用于模糊查询中匹配字符了,所以取余数便使用mod函数:
select mod(1,2);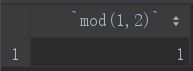
9.round
round函数用于对小数进行四舍五入,如果传入一个参数则默认保留整数部分:
select round(1.928);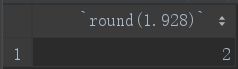
传入两个参数则第二个参数代表保留到小数点后第n位:
select round(1.928,2); 
10.truncate
truncate函数用于将小数截断,第二个参数传入0代表截断到整数部分:
select truncate(1.99,0);
11.date_format
date_format用于将时间类型的数据按指定格式打印出来:
select date_format(now(),'%Y%M%D');
该函数的应用见博客:
12.datediff
datediff函数用于查询当天的日期距参数中的日期的天数:
select datediff(now(),'2019-8-4');
13.timediff
与datediff函数功能类似,但是该函数是用来算精确时间差的:
select timediff(now(),'2019-8-16 16.04')
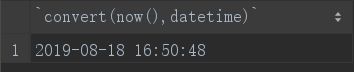
14.convert
convert函数用于将时间类型数据转为指定类型的数据,可以为char(取时间的位数),date,datetime等:
select convert(now(),char(10));
select convert(now(),date);
select convert(now(),datetime);

15.if(,,)
该函数的功能类似于三目运算符:
select id,name,mobile,if(address is null,'未知',address) from student; 
当替换的目标字段的值为null时,还可以使用if的简化版的衍生函数:
select id,name,mobile,ifnull(address,'未知') from student;16.distinct
distinct用于查询目标字段不包含重复的值:
select distinct age from student;
还有一点就是,如果distinct后面跟多个字段,则必须要这些字段的值都相同才算重复。